Streaming the Super Bowl: The Art of Scaling Across Multiple Cloud Regions
In this tutorial, learn to build multi-region applications that scale and tolerate all sorts of possible outages.
Join the DZone community and get the full member experience.
Join For FreeParamount+ streaming platform has outdone itself this NFL season, shattering viewership records during the AFC Championship Game and now the Super Bowl — hailed as the “most-watched telecast in history” with 123.4 million average viewers. Over 200 million tuned in to the game at some point, approximately ⅔ of the population of the United States. It also set a new benchmark as the most-streamed Super Bowl ever.
In anticipation of this level of interest, Paramount+ finalized their migration to a multi-region architecture early in 2023.
Since then, the streaming platform has been operating across multiple regions in Google Cloud and running on a distributed SQL database that functions across multiple distant locations. Prior to this, the database tier posed the biggest architectural challenge, prompting them to begin the search for a multi-master distributed database:
"Paramount+ was hosted on a single master (aka read/write) database. A single vertically scaled master database can only carry us forward so far. While the team considered sharding the data and spreading it out, our past experience taught us that this would be a laborious process. We started looking for a new multi-master capable database with the criteria that we had to make sure that we stick to a relational database due to the existing nature of the application. This narrowed down the criteria, and after some internal research and POCs we narrowed it down to a new player in the database space called YugabyteDB."
- Quote from a Paramount+ team member
So how can you achieve this level of app scalability and high availability across multiple regions? In this blog, I’ll use a sample application to analyze how services like Paramount+ can scale in a multi-region setup.
The Key Component to Getting a Multi-Region Architecture Right
Scaling the application tier across multiple regions is usually a no-brainer. Simply pick the most suitable cloud regions, deploy application instances there, and use a global load balancer to automatically route and load balance user requests.
Things get more complicated when dealing with a multi-region database deployment, especially for transactional applications requiring low latency and data inconsistency.
It is possible to achieve global data consistency by deploying a database instance with a single primary that handles all the user read and write requests.

However, this approach means that only users near the cloud region with the database (US East above) will experience low latency for read-write requests.
Users farther from the database’s cloud region will face higher latency since their requests travel longer distances. Additionally, an outage on the server, data center, or region hosting the database can make the application unavailable.
Therefore, getting the database right is crucial when designing a multi-region service or application.
Now, let’s experiment using YugabyteDB, the distributed database Paramount+ used for the Super Bowl and their global streaming platform.
Two YugabyteDB Design Patterns for Multi-Region Applications
YugabyteDB is a distributed SQL database built on PostgreSQL, essentially acting as a distributed version of PostgreSQL. Usually, the database is deployed in a multi-node configuration spanning several servers, availability zones, data centers, or regions.
The Yugabyte database shards data across all nodes and then distributes the load by having all the nodes process read and write requests. Transactional consistency is ensured with the Raft consensus protocol that replicates changes synchronously among the cluster nodes.
In multi-region database deployments, the latency between regions has the biggest impact on application performance. While there is no one-size-fits-all solution for multi-region deployments (with YugabyteDB or any other distributed transactional database), you can pick from several design patterns for global applications and configure your database so that it works best for your application workloads.
YugabyteDB offers eight commonly used design patterns to balance read-write latency with two key aspects of highly available systems: the recovery time objective (RTO) and recovery point objective (RPO).
Now, let’s review two of the design patterns from our list of eight — global database and follower reads — by looking into the latency of our sample multi-region application.
Design Pattern #1: Global Database
The global database design pattern assumes that a database is spread across multiple (i.e., three or more) regions or zones. If there’s a failure in one zone/region, the nodes in other regions/zones will detect the outage within seconds (RTO) and continue serving application workloads without any loss of data (RPO=0).
With YugabyteDB, you can reduce the number of cross-region requests by defining a preferred region. All the shards/Raft leaders will be located in the preferred region, delivering low-latency reads for the users near the region and predictable latency for those further away.
I provisioned a three-node YugabyteDB cluster (below) across the US East, Central, and West, with the US East region configured as the preferred region. Each region hosts an application instance that is connected to the node in the preferred region (US East).
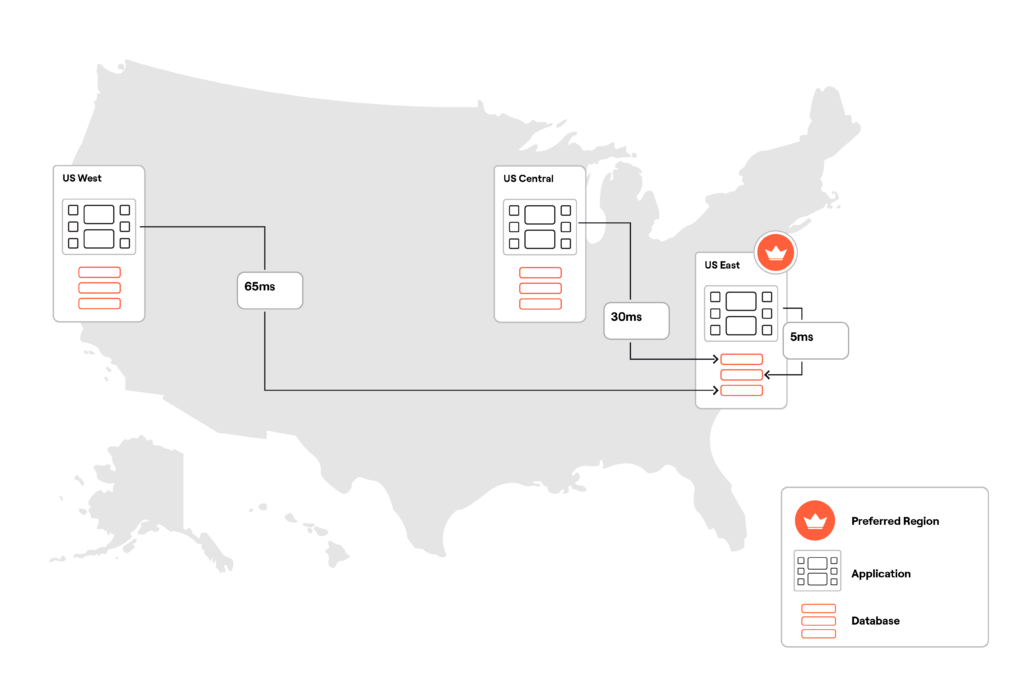 In this configuration, the round-trip latency between an application instance and the database varies by distance from the preferred region. For example, the app instance from the US East is 5 ms away from the preferred region, while the instance from the US West is 65 ms away. The US West and Central app instances are not connected to the database nodes in their local regions directly, because those nodes will still automatically route all the requests to the leaders in the preferred region.
In this configuration, the round-trip latency between an application instance and the database varies by distance from the preferred region. For example, the app instance from the US East is 5 ms away from the preferred region, while the instance from the US West is 65 ms away. The US West and Central app instances are not connected to the database nodes in their local regions directly, because those nodes will still automatically route all the requests to the leaders in the preferred region.
Our sample application is a movie recommendation service that takes user questions in plain English and uses a generative AI stack (OpenAI, Spring AI, and the PostgreSQL pgvector extension) to provide users with relevant movie recommendations.
Suppose you are in the mood for a space adventure movie with an unexpected ending. You connect to the movie recommendation service and send the following API request:
http GET {app_instance_address}:80/api/movie/search \
prompt=='a movie about a space adventure with an unexpected ending' \
rank==7 \
X-Api-Key:superbowl-2024The application performs a vector similarity search by comparing an embedding generated for the prompt parameter to the embeddings of the movie overviews stored in the database. It then identifies the most relevant movies and sends back the following response (below) in JSON format:
{
"movies": [
{
"id": 157336,
"overview": "Interstellar chronicles the adventures of a group of explorers who make use of a newly discovered wormhole to surpass the limitations on human space travel and conquer the vast distances involved in an interstellar voyage.",
"releaseDate": "2014-11-05",
"title": "Interstellar",
"voteAverage": 8.1
},
{
"id": 49047,
"overview": "Dr. Ryan Stone, a brilliant medical engineer on her first Shuttle mission, with veteran astronaut Matt Kowalsky in command of his last flight before retiring. But on a seemingly routine spacewalk, disaster strikes. The Shuttle is destroyed, leaving Stone and Kowalsky completely alone-tethered to nothing but each other and spiraling out into the blackness of space. The deafening silence tells them they have lost any link to Earth and any chance for rescue. As fear turns to panic, every gulp of air eats away at what little oxygen is left. But the only way home may be to go further out into the terrifying expanse of space.",
"releaseDate": "2013-09-27",
"title": "Gravity",
"voteAverage": 7.3
},
{
"id": 13475,
"overview": "The fate of the galaxy rests in the hands of bitter rivals. One, James Kirk, is a delinquent, thrill-seeking Iowa farm boy. The other, Spock, a Vulcan, was raised in a logic-based society that rejects all emotion. As fiery instinct clashes with calm reason, their unlikely but powerful partnership is the only thing capable of leading their crew through unimaginable danger, boldly going where no one has gone before. The human adventure has begun again.",
"releaseDate": "2009-05-06",
"title": "Star Trek",
"voteAverage": 7.4
}
],
"status": {/i>
"code": 200,
"success": true
}
}The response speed of the application and the read latency of this API call depend on which application instance received and processed your request:

If the request originates from US East, the latency can be as low as 9 ms since the database leaders are just a few milliseconds away from the US East-based application instance. However, latency is much higher for application instances in the US Central and West. This is because they must perform the vector similarity search on the US East database leaders and then receive/process a large result set with detailed information about suggested movies.
Note: The numbers above are not meant as the baseline of a performance benchmark. I ran a simple experiment on commodity VMs with a handful of shared vCPUs and didn’t perform any optimizations for software stack components. The results were just a quick functional test of this multi-region deployment.
Now, what if you want the application to generate movie recommendations at low latency regardless of the users’ location? How can you achieve low-latency reads across all regions? YugabyteDB supports several design patterns that can achieve this, including follower reads.
Design Pattern #2: Follower Reads
The follower reads pattern lets the application instances in secondary regions read from local nodes/followers instead of going to the database leaders in the preferred region. This pattern speeds up the reads to match those from the leaders, although the followers may not hold the most current data at the time of the request.
To use this pattern, I had to:
- Connect the application instances from US Central and West to the database nodes from their respective regions.
- Allow follower reads by setting the following flags for the database session.
SET session characteristics as transaction read only;
SET yb_read_from_followers = true;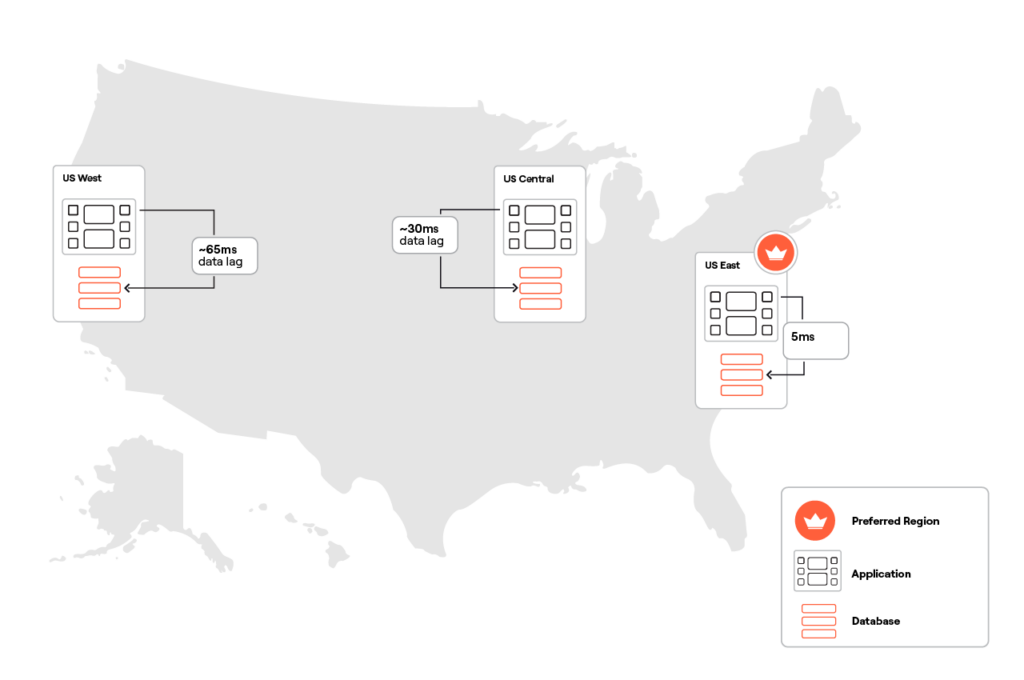
With this configuration, read latency is similar across all the regions. There might be a 30 ms data lag on the database node in the US Central and a 65 ms data lag on the US West node. Why? My multi-region cluster is configured with a replication factor of 3. This means that a transaction would be considered committed once two nodes out of three confirm the changes. So, if the US East and Central nodes have acknowledged a transaction, the US West node might still be recording the change, explaining the lag during follower reads.
Despite potential data lags, the entire data set on the followers always remains in a consistent state (across all tables and other database objects). YugabyteDB ensures data consistency through its transactional sub-system and the Raft consensus protocol, which replicates changes synchronously across the entire multi-region cluster.
Now, let’s use follower reads to send the same HTTP request to US Central and West instances:
http GET {app_instance_address}:80/api/movie/search \
prompt=='a movie about a space adventure with an unexpected ending' \
rank==7 \
X-Api-Key:superbowl-2024Now, the read latency across all the regions is consistently low and comparable:

Note: The application instance from US East doesn’t need to use the follower reads pattern as long as it can work directly with the leaders from the preferred region.
A Quick Note on Multi-Region Writes
So far, we’ve used the global database with the preferred region and follower reads design patterns to ensure low latency reads across distant locations. This configuration can tolerate region-level outages with RTO measured in seconds and RPO=0 (no data loss).
In this configuration, there is a tradeoff with write latency. If YugabyteDB has to keep a consistent copy of data across all regions, cross-region latency will affect the time needed for the Raft consensus protocol to synchronize changes across all locations.
For example, suppose you want to watch the movie “Interstellar." You add it to your watch list with the following API call to the movie recommendations service (Note: 157336 is Interstellar’s internal ID):
http PUT {app_instance_address}:80/api/library/add/157336 X-Api-Key:superbowl-2024The latency in my application setup is:

Write latency was lowest for requests originating from the US East-based application instance directly connected to the database node in the preferred region (US East). Latency for writes from other locations was higher because their requests had to travel to leaders in the preferred region before a transaction could be executed and replicated across the entire cluster.
Does this mean that the write latency is always high in a multi-region configuration? Not necessarily.
YugabyteDB offers several design patterns that allow you to achieve low-latency reads and writes in a multi-region setting. One such pattern is latency-optimized geo-partitioning, where user data is pinned to locations closest to the users, resulting in single-digit millisecond latency for reads and writes.
Video
Summary
Paramount+ successfully transitioning to a multi-region architecture shows that with the right design patterns, you can build applications that tolerate region-level outages, scale, and perform at low latencies across distant locations.
The Paramount+ tech team learned the art of scaling by creating a streaming platform that accommodates millions of users during peak periods, with low latency and uninterrupted service. Implementing a multi-region setup correctly is essential. If you pick the right design pattern, you, too, can build multi-region applications that scale and tolerate all sorts of possible outages.
Published at DZone with permission of Denis Magda. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments