Stream Analytics and Workflow Engines
The following article will show you how to solve some of the challenges related to stream analytics and workflow engines with the help of workflow technology.
Join the DZone community and get the full member experience.
Join For FreeThe real-time processing of a continuous stream of business data and events is becoming increasingly important in modern IT architectures. This type of architecture, in which events are building the center of data processing, is also known as a Reactive Streaming Architecture. In the following, I will show how to solve some of the related challenges with the help of workflow technology.
Let’s take a closer look at this type of architecture first. Basically, the event-based processing of data is not new and has actually been developed for decades in various specialized domains, such as the financial sector. But, since the last few years, new standards for processing data streams have emerged. Technologies like Apache Kafka, Storm, Flink, or Spark are gaining popularity and pushing a new hype.
From industrial production systems to multiplayer computer games, so-called Streaming Architectures are used more and more frequently in order to be able to process big data in real-time. Streaming architectures have developed into a central architectural element of modern technology companies. In many companies, real-time streams have become the core system in their architecture.
The goal is to be able to integrate new system solutions more quickly and to connect any kind of data streams. The streaming architecture is not only found at technology giants such as eBay, Netflix, or Amazon but, today, in every modern technology company that is working on the digitization of its business processes. So, what are the main challenges in building such an architecture?
Processing Data Streams
In the early days of event streaming, data streams were recorded and subsequently analyzed (batch processing), whereby the actual business logic remained completely unaffected. But, as the business logic becomes more complex, it becomes more difficult to process the data. The general task of processing data streams, therefore, poses many different challenges.
Data from different sources (Producer) need to be sorted, categorized, and dispatched to the different targets (Consumer). Producers can generate different kinds of events and consumers are typically only interested in specific events which may be created by different consumers. Systems must be able to partition, structure, and distribute data in a coordinated manner.
In order to guarantee a high data throughput, such systems have to scale horizontally. Apache Kafka has meanwhile become the de facto standard for this type of technology. It offers a great deal of flexibility and can be integrated into other systems in many different ways.
Stream Analytics and Business Processing
But, capturing the data streams is only one part of the challenge. Some data processing has to be performed simultaneously with the incoming data to be able to use the results promptly for decision-making. For example, a selection of products in a shopping cart system can be the trigger for a recommendation system to be executed in parallel. This type of requirement creates another building block in the streaming architecture – called Stream Analytics.
Sometimes a single event from the data stream is enough to trigger a predefined business logic. However, it is often necessary to be able to recognize connections between different events in order to run a high-level business process generating real business value. Such a connection can be established between time-shifted similar events by accumulating them over a given period of time. For example, short-term increased demand for a certain product in an online shop system could trigger the start of an additional production line. In other cases, it may be necessary to correlate certain events of different types and merge the data to trigger the corresponding business process. These methods are also known as Windowing and Joining.
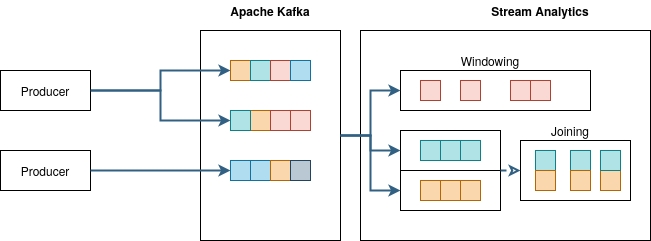
In all these cases, so-called Micro-Batches are implemented to run the business logic within the stream analytics module. Apache Kafka Streams is an extension within the Kafka-Stack providing many of these functionalities. It allows the development of micro-batches in different programming languages like Java or Scala. In the current edition 2021/03 of JavaSpektrum magazine, George Mamaladze from Siemens AG describes this concept in a broader approach.
However, micro-batching creates new challenges. Business logic can no longer be described as a simple function. Stateful algorithms are required, for example, to keep data aggregated over a period of time. Another requirement is the parallel execution of these algorithms with corresponding state management. It is, therefore, necessary to persist the states and, in case of an error, to resume the business process at the point where it was last interrupted. The implementation of such business logic is complex and often time-consuming.
To be able to manage more complex long-running business processes, Workflow Engines become an important building block to achieve the separation between the data streams and the business logic. Workflow engines are optimized in processing complex business logic and in persisting business states over a long period of time. The main difference lies in state management across all running micro-batches. The model-driven architecture of a workflow engine allows adapting to changing requirements and technologies quickly.
Based on a new incoming event (created by a Micro-Batch), the workflow engine can start a new business process or continue an already started process instance. The workflow engine will automatically persist the state of the business process and can collect events from different producers. However, also the results of a single processing step or the completion of a business process can produce a new event.
So, within a Reactive Streaming Architecture, the Workflow Engine takes the role of a Consumer and a Producer controlling the whole life cycle of a business process.
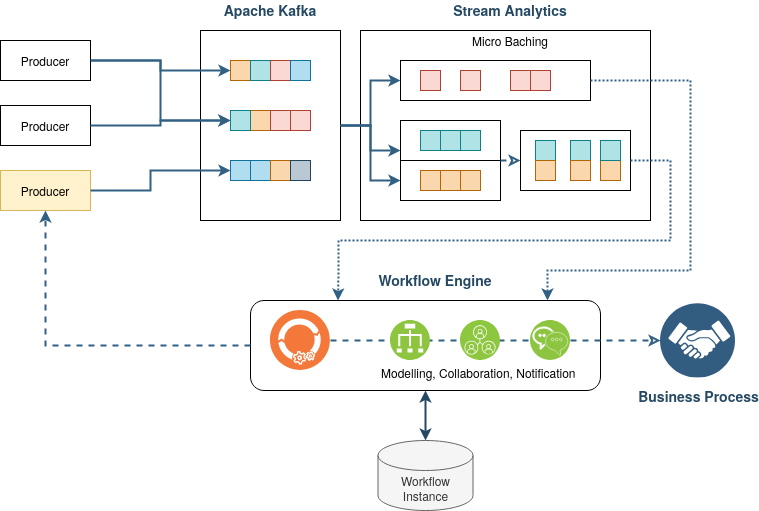
Stream Analytics With Imixs-Workflow
Imixs-Workflow is an open-source workflow engine offering a wide range of functionality to control complex business processes. The event-based workflow engine can run as a Microservice and is extensible via its micro-kernel architecture. Imixs-Workflow already comes with an Apache Kafka adapter which makes it easy to start processing events from a reactive streaming platform.
The Imixs-Kafka Adapter acts as a consumer of events generated within the Kafka Stack. With its Autowire functionality, Imixs-Workflow can also send Workflow Messages automatically during the processing life-cycle. This allows building more complex business processes in a distributed microservice architecture.
Model-Driven Business Logic
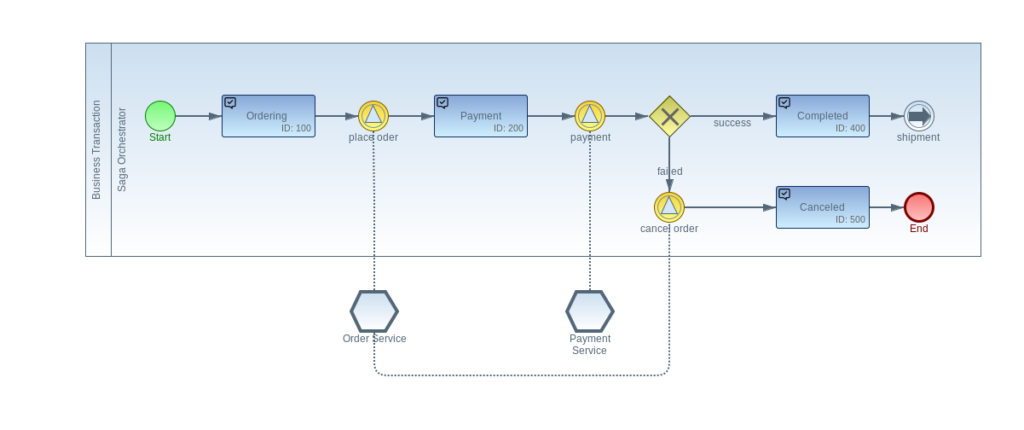
The Business Process Modelling Notation (BPMN) – today’s standard for the modeling of business processes – can help to build a flexible architecture in a model-driven way. BPMN 2.0 is an XML-based extensible modeling standard allowing the modeling, analyzing, and execution of complex business processes.
In an event-based workflow engine like Imixs-Workflow, the different states of a business process are described as Tasks. The transition from one state to the next is described by Event elements. Events can be triggered by consuming a Kafka streaming event, as also by external services or human actors. By combining Tasks and Events with a Gateway element, business rules can be modeled to make decisions and react to different situations based on the collected data.
Aggregating Streaming Events
The advantage of consuming event streams with a workflow engine is the ability to aggregate data over a long period of time within a specific context. The data can be aggregated and transformed from different sources and combined with already existing business data.
For example in a shopping system, the registration of a new customer can trigger a VIP-Membership Process. The workflow engine is first reacting only on new customer registrations to start the VIP-Membership business process. From this moment on, the workflow engine reacts to certain events within the shopping system that enable the VIP membership. This can be, for example, the purchase of certain products or taking out a subscription.
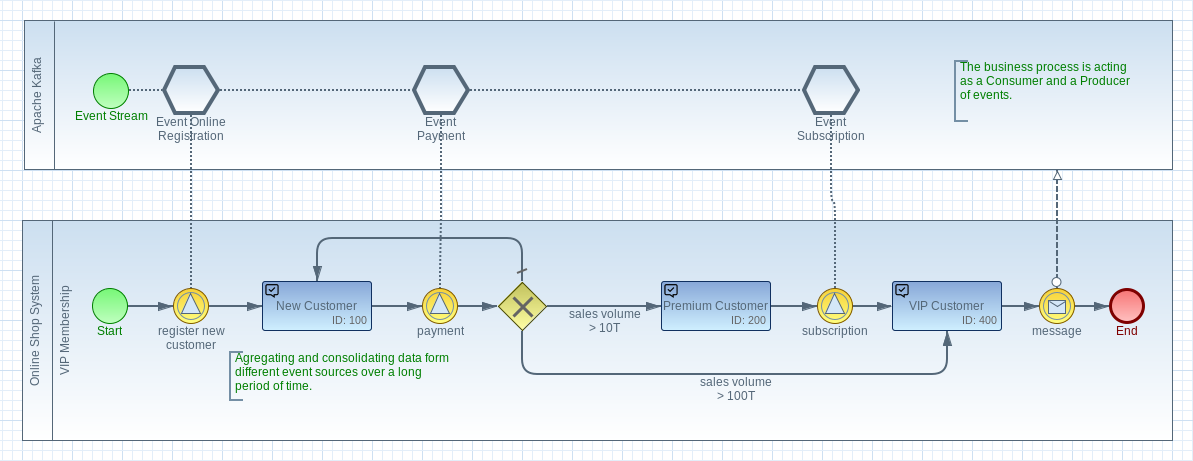
Changing the business logic does not require any changes on the code base or implementing new micro-batches. Also, new additional business workflows can be adapted during runtime without changing the architecture.
Artificial Intelligence
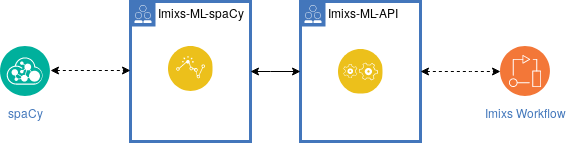
Based on the Imixs micro-kernel architecture a business process can be extended with various adapter or plug-in modules providing additional functionality. The Imixs-ML Adapter for example provides a generic API to integrate various ML frameworks like spaCy or Apache mxnet. With this adapter technology, business processing can be enriched with artificial intelligence.
The core concept of Imixs-ML is based on Natural language processing (NLP), which is a subfield of machine learning. With the Named entity recognition (NER) a given stream of text can be analyzed and text entities such as people, places, or even invoice data such as dates and invoice totals can be extracted from any kind of streaming events. The results of such a machine learning process can be used to model more complex business logic and making business discussions based on various training models.
Continual Learning
Continual learning is the ability of an ML training model to learn continually from a stream of data. In practice, this means supporting the ability of a model to autonomously learn and adapt in production as new data comes in. With the Imixs-ML adapter, this concept is integrated into the live cycle of a business process. The Imixs-Workflow engine can automatically refine an ML training model based on the results of a business process. In this way, data from an event streaming platform can be used to generate new training models for future processing. But also the decisions made by human operators can be used for refining existing ML training models.
Conclusion
In combining a reactive streaming architecture with the concept of modern business process management, highly complex business processes can be realized in a very short time. Thanks to the model-driven approach of modern BPMN 2.0 based workflow technologies, even complex business processes can be designed and executed without changing the overall architecture. This type of architecture opens up completely new possibilities for dealing with continuous data streams.
Published at DZone with permission of Ralph Soika. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments