Stateful Stream Processing With Memphis and Apache Iceberg
In this article, readers will use a tutorial to learn how to use Apache Iceberg on AWS S3 to process and enrich large scale data, including code and images.
Join the DZone community and get the full member experience.
Join For FreeAmazon Web Services S3 (Simple Storage Service) is a fully managed cloud storage service designed to store and access any amount of data anywhere. It is an object-based storage system that enables data storage and retrieval while providing various features such as data security, high availability, and easy access. Its scalability, durability, and security make it popular with businesses of all sizes.
Apache Iceberg is an open-source tabular format for data warehousing that enables efficient and scalable data processing on cloud object stores, including AWS S3. It is designed to provide efficient query performance and optimize data storage while supporting ACID transactions and data versioning. The Iceberg format is optimized for cloud object storage, enabling fast query processing while minimizing storage costs.
Memphis is a next-generation alternative to traditional message brokers.
A simple, robust, and durable cloud-native message broker wrapped with an entire ecosystem that enables cost-effective, fast, and reliable development of modern queue-based use cases.
The common pattern of message brokers is to delete messages after passing the defined retention policy, like time/size/number of messages. Memphis offers a second storage tier for longer, possibly infinite retention for stored messages. Each message that expels from the station will automatically migrate to the second storage tier, which, in that case, is AWS S3.
AWS S3 Benefits
- Scalability: AWS S3 is highly scalable and can store and retrieve any data, from a few gigabytes to petabytes.
- Durability: S3 is designed to provide high durability, ensuring your data is always available and secure.
- Safety: S3 offers various security features, such as encryption and access control, so you can protect your data.
- Accessibility: S3 is designed for easy access, making it easy to store and access your data from anywhere in the world.
- Cost efficient: S3 is designed to be a cost-effective solution with usage-based pricing and no upfront costs.
The purpose of processing data using Apache Iceberg is to optimize query performance and storage efficiency for large-scale data sets, while also providing a range of features to help manage and analyze data in the cloud. Here are some of the key benefits of using Apache Iceberg for data processing:
- Efficient query performance: Apache Iceberg is designed to provide efficient query performance for large amounts of data by using partitioning and indexing to read only the data needed for a particular query. This enables faster and more accurate data processing, even for huge amounts of data.
- Data versioning: Apache Iceberg supports data versioning, so you can store and manage multiple versions of your data in the same spreadsheet. This allows you to access historical data at any time and easily track changes over time.
- ACID transactions and flexibility: Apache Iceberg supports ACID transactions to ensure data consistency and accuracy at all times. This is especially important when working with mission-critical data, as it ensures your data is always reliable and up-to-date.
- Optimized data storage: Apache Iceberg optimizes data storage by only reading and writing the data needed for a given query. This helps minimize storage costs and ensures you’re only paying for the data you’re actually using.
Overall, the purpose of processing data with Apache Iceberg is to provide a more efficient and reliable solution for managing and processing large amounts of data in the cloud. With Apache Iceberg, you can optimize query performance, minimize storage costs, and ensure data consistency and freshness at all times.
Setting Up Memphis
- To get started, first install Memphis.
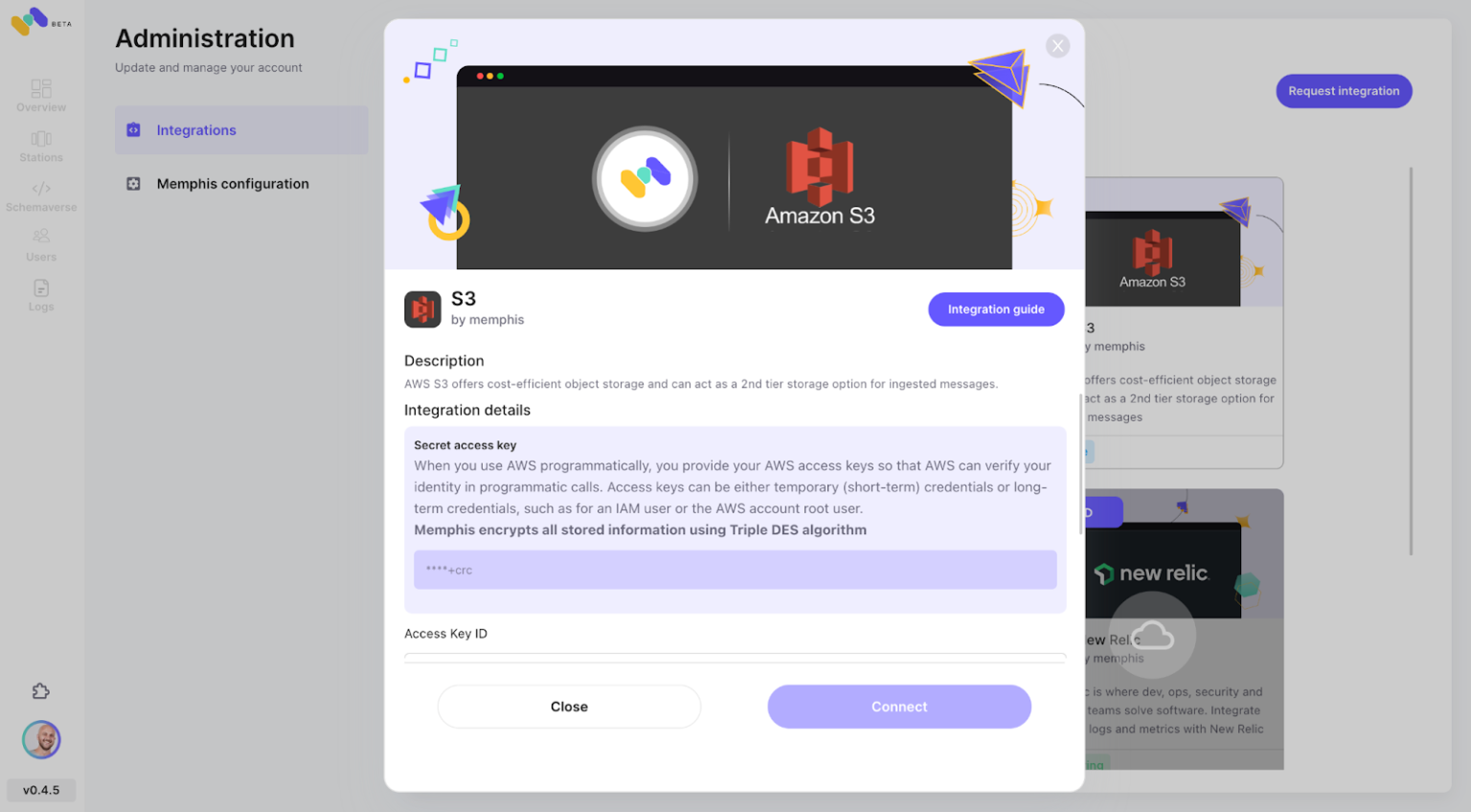
- Enable AWS S3 integration via the Memphis “integration center.”
![Memphis Integration Center]()
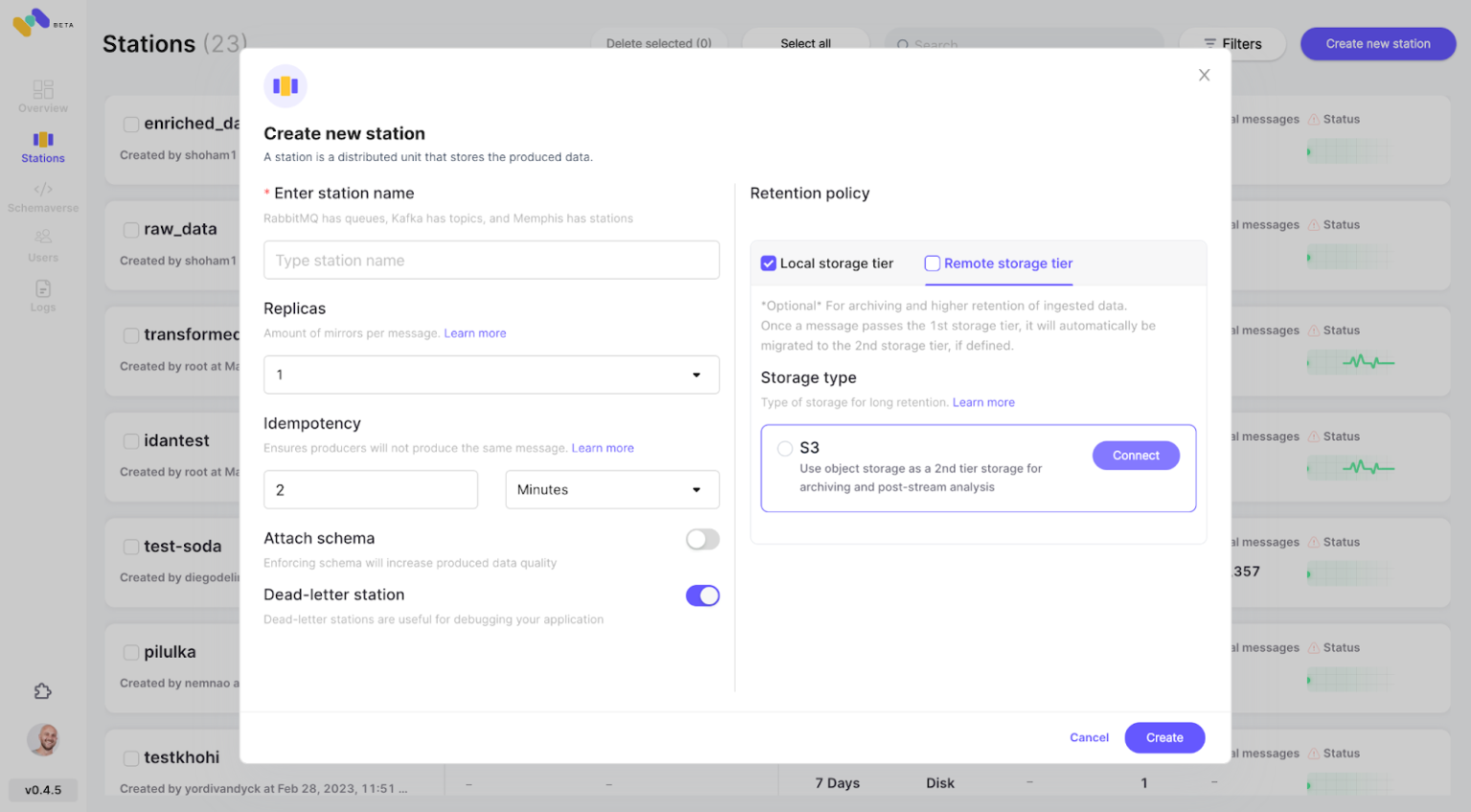
- Create a station (topic), and choose a retention policy. Each message passing the configured retention policy will be offloaded to an S3 bucket.
![Stations]()
- Check the newly configured AWS S3 integration as second storage class by clicking “Connect.”
- Start producing events into your newly created Memphis station.
Setting Up AWS S3 and Apache Iceberg
To get started, you’ll need an AWS S3 account. Creating an AWS S3 account is a simple process. Here are the steps to follow:
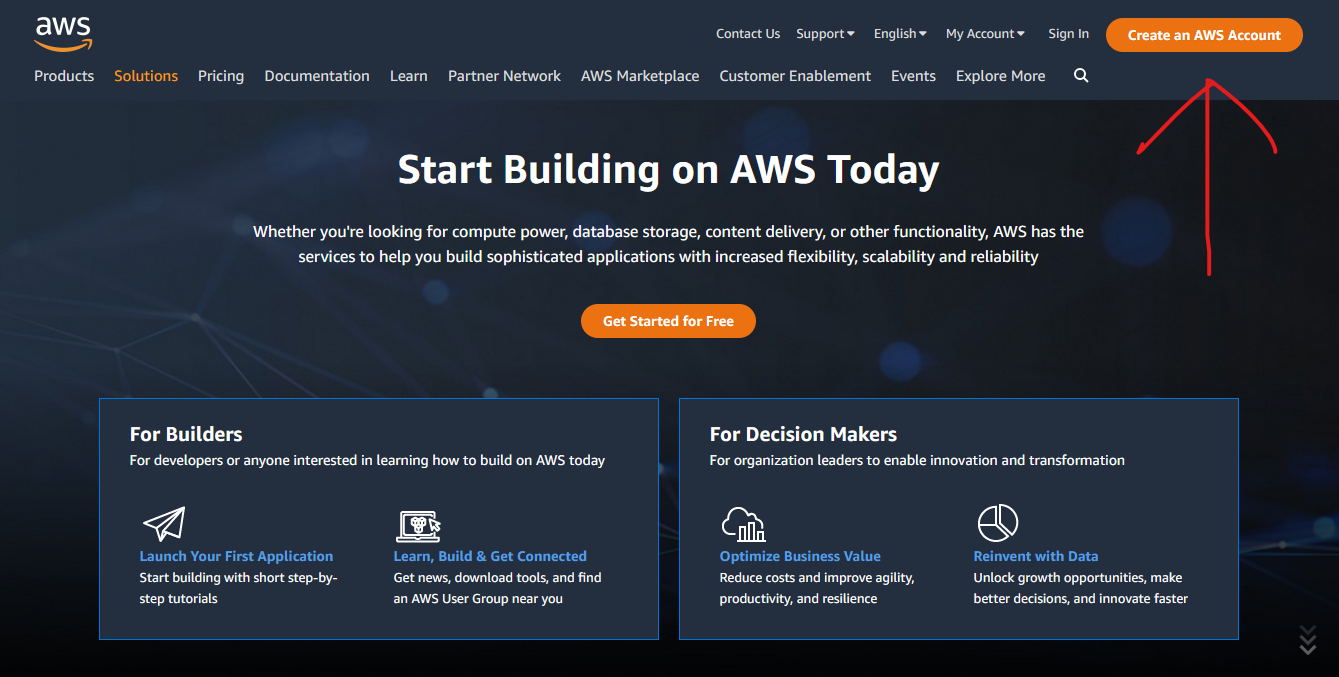
- Go to the AWS homepage and click on the “Sign In to the Console” button in the top right corner.
![Create Account]()
- If you already have an AWS account, enter your login details and click “Sign In.” If you don’t have an AWS account, click “Create a new AWS account” and follow the instructions to create a new account.
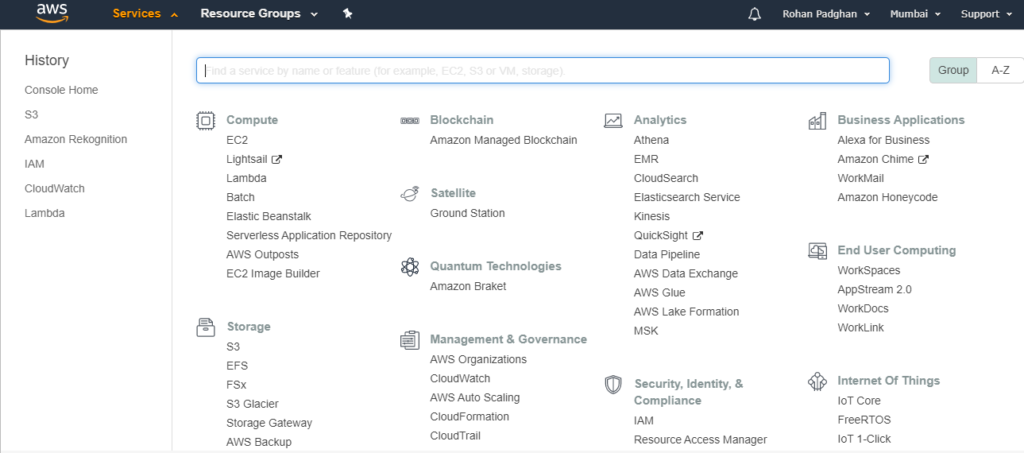
- Once you’re logged into the AWS console, click on the “Services” dropdown menu in the top left corner and select “S3” from the “Storage” section.
![Step 3]()
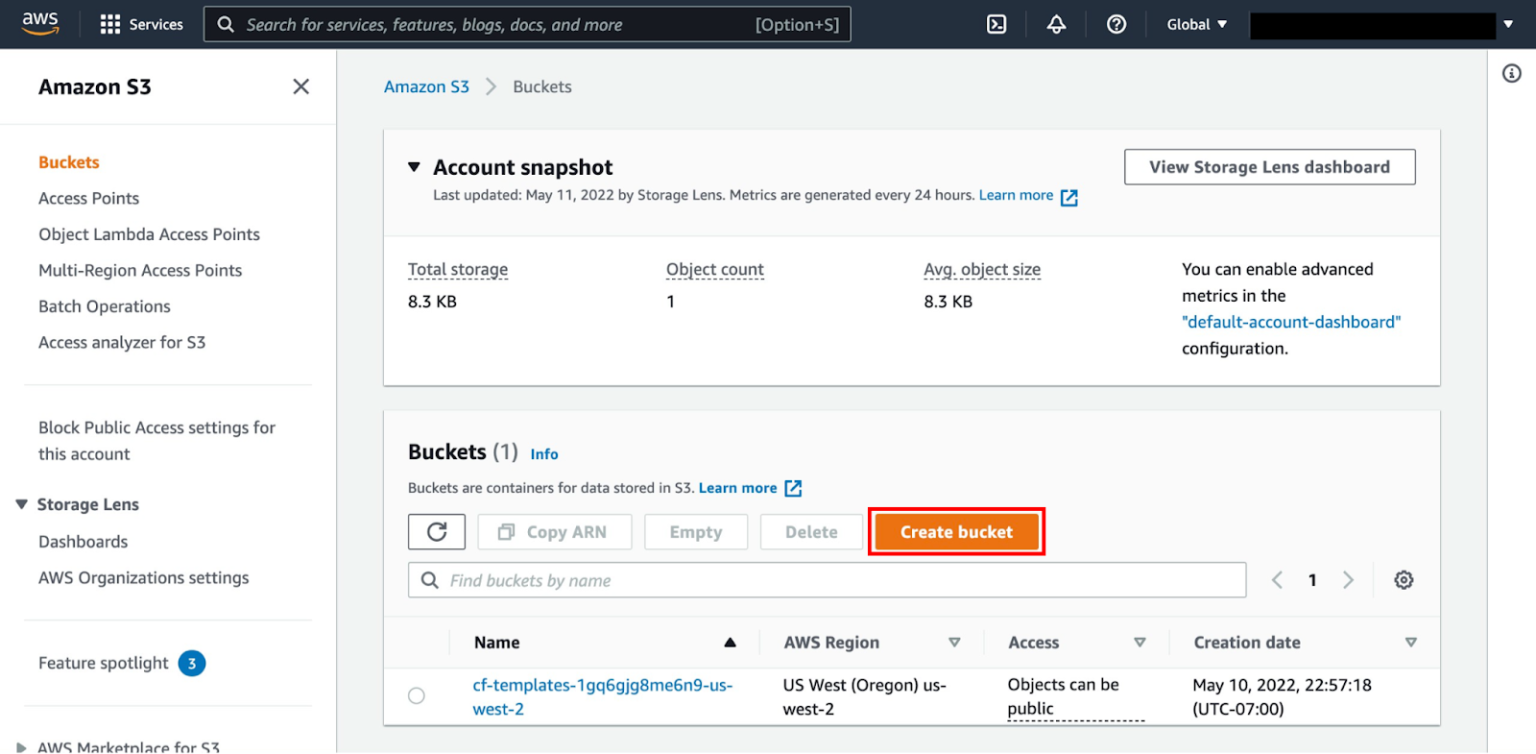
- You’ll be taken to the S3 dashboard, where you can create and manage your S3 buckets. To create a new bucket, click the “Create bucket” button.
![Create Bucket]()
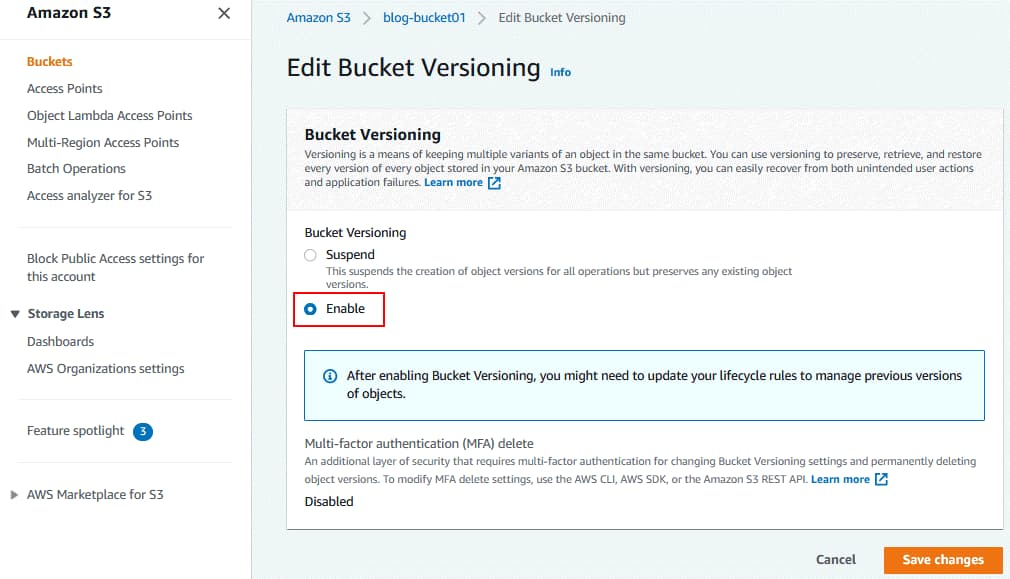
- Enter a unique name for your bucket (bucket names must be unique across all of AWS) and select the region where you want to store your data.
- You can choose to configure additional settings for your bucket, such as versioning, encryption, and access control. Once you’ve configured your settings, click “Create bucket” to create your new bucket.
That’s it! You’ve created an AWS S3 account and created your first S3 bucket. You can use this bucket to store and manage your data in the cloud and you must have installed Apache Iceberg on your system. You can download Apache Iceberg from the official website, or you can install it using Apache Maven or Gradle.
Once you have Apache Iceberg installed, create an AWS S3 bucket where you can store your data. You can do this using the AWS S3 web console, or you can use the AWS CLI by running the following command:
aws s3 mb s3://bucket-nameand replacebucket-namewith the name of your bucket.
After creating the bucket, to create a table using Apache Iceberg, you can use the Iceberg Java API or the Iceberg CLI. Here’s an example of how to create a table using the Java API:
1. First, you need to add the Iceberg library to your project. You can do this by adding the following dependency to your build file (e.g. Maven, Gradle):
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-core</artifactId>
<version>0.11.0</version>
</dependency>2. Create a schema object that defines the columns and data types for your table:
Schema schema = new Schema(
required(1, "id", Types.IntegerType.get()),
required(2, "name", Types.StringType.get()),
required(3, "age", Types.IntegerType.get()),
required(4, "gender", Types.StringType.get())
);In this example, the schema defines four columns:
- id (an integer)
- name (a string)
- age (an integer)
- gender (a string)
3. Create a PartitionSpec object that defines how your data will be partitioned. This is optional, but it can improve query performance by allowing you to only read the data that’s relevant to a given query. Here’s an example:
PartitionSpec partitionSpec = PartitionSpec.builderFor(schema)
.identity("gender")
.bucket("age", 10)
.buildIn this example, we’re partitioning the data by gender and age. We’re using bucketing to group ages into ten buckets, which will make queries for specific age ranges faster.
4. Create a “table object” that represents your table. You’ll need to specify the name of your table and location where the data will be stored (in this example, we’re using an S3 bucket):
Table table = new HadoopTables(new Configuration())
.create(schema, partitionSpec, "s3://my-bucket/my-table");This will create a new table with the specified schema and partitioning in the S3 bucket. You can now start adding data to the table and running queries against it.
Alternatively, you can use the Iceberg CLI to create a table. Here’s an example:
- Open a terminal window and navigate to the directory where you want to create your table.
- Run the following command to create a new table with the specified schema and partitioning:
iceberg table create \
--schema "id:int,name:string,age:int,gender:string" \
--partition-spec "gender:identity,age:bucket[10]" \
s3://my-bucket/my-tableThis will create a new table with the specified schema and partitioning in the S3 bucket. You can now start adding data to the table and running queries against it and that’s how you can create a table using Apache Iceberg.
Converting Data to String or JSON
Converting data to strings or JSON is a common task when processing data with Apache Iceberg. This is useful for various reasons to prepare data for downstream applications, to export data to other systems, or simply make it easier for humans to read. The method is as follows:
- Identify the data to transform.
- Before converting data to string or JSON, you need to identify the data to convert. This can be the entire table, a subset of the table, or a single row.
- Once the data is identified, it can be converted to strings or JSON using the Apache Iceberg API.
- Convert data to string or JSON using Apache Iceberg API.
Expressions and row classes can be used to convert data to strings or JSON in Apache Iceberg. Here’s an example of how to convert a line to a JSON string:
Row row = table.newScan().limit(1).asRow().next();
String json = JsonUtil.toJson(row, table.schema());This example scans a table and returns the first row as a row object. Then, use the JsonUtil class and table’s schema to convert the row to a JSON string. You can use this approach to convert a single line to a JSON string or convert multiple lines to an array of JSON objects.
Here is an example of converting a table to a CSV string:
String csv = new CsvWriter(table.schema()).writeToString(table.newScan());
This example uses the CsvWriter class to convert the entire table to a CSV string. The CsvWriter class takes the table’s schema as a parameter and allows you to specify additional options such as delimiters and double quotes.
Save the transformed data to AWS S3. After converting the data to string or JSON, you can save it to AWS S3 using the HadoopFileIO class. Here’s an example of how to save a JSON string to an S3 bucket:
byte[] jsonBytes = json.getBytes(StandardCharsets.UTF_8);
HadoopFileIO fileIO = new HadoopFileIO(new Configuration());
try (OutputStream out = fileIO.create(new Path("s3://my-bucket/my-file.json"))) {
out.write(jsonBytes); }This example converts a JSON string to a byte array, creates a new HadoopFileIO object, and writes the byte array to an S3 file. You can use this approach to store any type of transformed data (CSV, TSV, etc.) in S3.
Flattening Schema
Schema flattening is the process of converting a nested schema into a flat schema with all columns at the same level. This helps facilitate data querying and analysis. To flatten the schema using Apache Iceberg:
- Before simplifying the schema, you must identify the schema to simplify. This can be a schema that you have created yourself or a schema that is part of a larger dataset that you extract and analyze.
- Once you have identified a schema to simplify, you can simplify it using the Iceberg Java API. Here’s an example of how to simplify the schema:
Schema nestedSchema = new Schema(
required(1, "id", Types.LongType.get()),
required(2, "name", Types.StringType.get()),
required(3, "address", Types.StructType.of(
required(4, "street", Types.StringType.get()),
required(5, "city", Types.StringType.get()),
required(6, "state", Types.StringType.get()),
required(7, "zip", Types.StringType.get())
))
);
Schema flattenedSchema = new Schema(
required(1, "id", Types.LongType.get()),
required(2, "name", Types.StringType.get()),
required(3, "address_street", Types.StringType.get()),
required(4, "address_city", Types.StringType.get()),
required(5, "address_state", Types.StringType.get()),
required(6, "address_zip", Types.StringType.get())
);
Transform flatten = new Transform(
OperationType.FLATTEN,
ImmutableMap.of(
"address.street", "address_street",
"address.city", "address_city",
"address.state", "address_state",
"address.zip", "address_zip"
)
);
Schema newSchema = new Schema(flattenedSchema.columns());
newSchema = newSchema.updateMetadata(
IcebergSchemaUtil.TRANSFORMS_PROP,
TransformUtil.toTransformList(flatten).toString()
);
Table table = new HadoopTables(conf).create(
newSchema, PartitionSpec.unpartitioned(), "s3://my-bucket/my-table"
);In this example, we have a nested schema with a name and address field. We want to flatten the address field into separate columns for street, city, state, and zip.
To do this, we first create a new schema that represents the flattened schema. We then create a “Transform” that specifies how to flatten the original schema. In this case, we’re using the FLATTEN operation to create new columns with the specified names. We then create a new schema that includes the flattened columns and metadata that specifies the transformation that was applied. Once you’ve flattened the schema, you can save it to AWS S3 using the table object you created. Here’s an example:
table.updateSchema()
.commit();This will save the flattened schema to the S3 bucket you specified when you created the table. That’s how you can flatten a schema using Apache Iceberg and save it to AWS S3.
Conclusion
Processing and managing large amounts of data in AWS S3 can be challenging, especially when dealing with nested schemas and complex queries. Apache Iceberg provides a powerful and efficient solution to these challenges, giving users a scalable and cost-effective way to process and query large amounts of data. This tutorial showed how to use Apache Iceberg on AWS S3 to process and manage data. We’ve seen how to create tables, convert data to strings or JSON, and simplify schemas to make data more accessible. Armed with this knowledge, you can now use Apache Iceberg to process and manage large amounts of data on AWS S3.
Published at DZone with permission of Idan Asulin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments