Stateful Microservices With Apache Ignite
This article explains how to implement stateful microservices architecture for Spring Boot applications with distributed database Apache Ignite.
Join the DZone community and get the full member experience.
Join For FreeStateful microservices are not a new concept. They have their pros and cons and can shine in highly loaded systems. There are examples of using stateful microservices with Apache Cassandra on board. In this article, I will describe how you can combine this approach with Apache Ignite.
Stateless Architecture
The traditional microservices architecture is stateless. In this case, the database cluster is deployed away from the application instances, as is the distributed cache. In case of increased load, each of these elements is scaled independently.
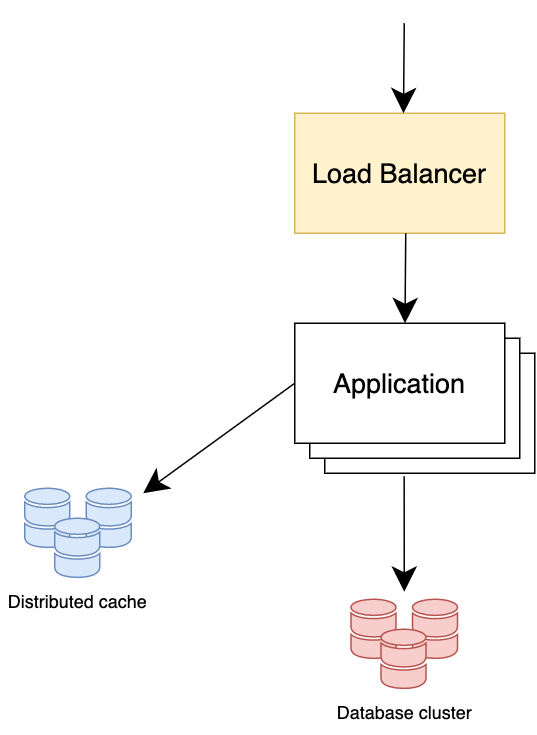
There are two main problems in high-load systems:
- Network latency takes up a significant part of the response time.
- Message marshaling and unmarshalling is the primary consumer of the CPU. Not to mention, often, clients are interested in only a small part of the returned data.
Stateful Architecture
A stateful architecture was invented to solve these problems, where database and cache are started in the same process as applications. There are several databases in the Java world that we can run in embedded mode. One of them is Apache Ignite. Apache Ignite supports full in-memory mode (providing high-performance computing) as well as native persistence.
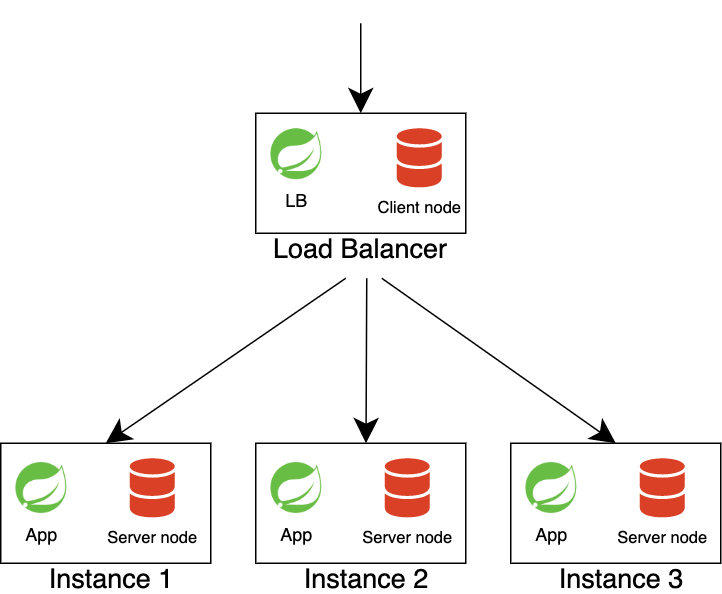
This architecture requires an intelligent load balancer. It needs to know about the partition distribution to redirect the request to the node where the requested data is actually located. If the request is redirected to the wrong node, the data will come over the network from other nodes.
Apache Ignite supports data collocation, which guarantees to store information from different tables on the same node if they have the same affinity key. The affinity key is set on table creation. For example, the Users table (cache in Ignite terms) has the primary key userId, and the Orders table may have an affinity key - userId. Thus, data about a specific user and all its orders will be stored on one node (as well as replicas on other nodes).
However, there are also downsides. For example, scaling down is problematic because you have to scale down the database, which is always tricky.
Implementation
Load Balancer
We are interested in the following components:
- Service Discovery to keep track of which instances are online now.
- Partition distribution mapping to know which instances have requested data
- An intelligent load balancer that knows precisely where to send requests to nodes as close to the data as possible.
Let's use Spring Cloud Load Balancer project for our implementation. We need to define two beans:
@Bean
@Primary
public ServiceInstanceListSupplier serviceInstanceListSupplier(IgniteEx ignite) {
return new IgniteServiceInstanceListSuppler(ignite);
}
@Bean
public ReactorLoadBalancer<ServiceInstance> reactorServiceInstanceLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RoundRobinLoadBalancer(
loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}IgniteServiceInstanceListSuppler will return instances based on the request key.
We may not use Spring Cloud Eureka for the Discovery Service since we already have this component implemented in Apache Ignite. Similarly, the partition distribution mapper can also be reused from Ignite itself if the load balancer runs a thick client node.
We can subscribe to discovery events to timely respond to changes in the cluster topology:
public IgniteServiceInstanceListSuppler(IgniteEx ignite) {
this.ignite = ignite;
ignite.context().event().addDiscoveryEventListener(this::topologyChanged, EVTS_DISCOVERY);
updateInstances(ignite.cluster().nodes());
}Load balancer extracts two parameters from request headers:
affinity-cache-name- to get the name of the Apache Ignite cache from which we will take the affinity function.affinity-key- data sharding key.
Since we set up data sharding based on userId, we can use UserCache to get the actual affinity function.
@Override
public Flux<List<ServiceInstance>> get(Request req) {
if (req.getContext() instanceof RequestDataContext) {
HttpHeaders headers = ((RequestDataContext)req.getContext()).getClientRequest().getHeaders();
String cacheName = headers.getFirst("affinity-cache-name");
String affinityKey = headers.getFirst("affinity-key");
Affinity<Object> affinity = affinities.computeIfAbsent(
cacheName, k -> ((GatewayProtectedCacheProxy)ignite.cache(cacheName)).context().cache().affinity()
);
ClusterNode node = affinity.mapKeyToNode(affinityKey);
if (node != null)
return Flux.just(singletonList(toServiceInstance(node)));
}
return get();
}Application
The code of the microservice itself will practically not differ from how if we had a cluster with data aside from services. The only difference is that instead of client nodes, we will run embedded server nodes.
@Bean(IGNITE_NAME)
public Ignite ignite() {
IgniteConfiguration cfg = new IgniteConfiguration()
.setConsistentId(consistentId)
.setUserAttributes(U.map(
"load_balancing_host", host,
"load_balancing_port", port
))
.setDiscoverySpi(new TcpDiscoverySpi()
.setIpFinder(new TcpDiscoveryMulticastIpFinder()
.setAddresses(adresses)));
return Ignition.start(cfg);
}Using user attributes, we can pass node parameters for the load balancer, such as host and port.
Thereby, we will significantly increase performance since the data will be located directly in the same JVM where we have run the business logic. Marshaling overhead and network latency are kept to a minimum.
We can also use Apache Ignite as a cache by simply creating a separate in-memory data region with the same affinity keys.
You can find the complete application code in GitHub.
Opinions expressed by DZone contributors are their own.
Comments