6 Pre-Trained DL Models to Digitize and Extract Features from Imagery
Here are 6 pre-trained deep learning models that you can use for everything from extracting building footprints to detecting shipwrecks.
Join the DZone community and get the full member experience.
Join For FreeWith the firehose of imagery that’s streaming down daily from a variety of sensors, the need for using AI to automate feature extraction is only increasing. Deep learning models can be readily used to automate the tedious task of digitizing and extracting geographical features from satellite imagery and point cloud datasets. Here are six pre-trained models that you can use for everything from extracting building footprints to detecting shipwrecks.
Building Footprint Extraction
The Building Footprint Extraction model is the most popular model so far. This deep learning model is used to extract building footprints from high-resolution (10–40 cm) imagery. Building footprint layers are useful in preparing base maps and analysis workflows for urban planning and development, insurance, taxation, change detection, infrastructure planning, and a variety of other applications.

While it's designed for the contiguous United States, it also performs well in other parts of the globe. Here’s a story map presenting some of the results. This model has been updated and trained on more data. This new model works well even when buildings are in close proximity–something that the original model did not. See the difference in the results in the following images:

You’ll also notice a significant drop in false positives over water, dockyards, and places where buildings typically don’t exist.
Road Extraction
The new Road Extraction model is used to extract roads from satellite imagery. Roads are one of the primary GIS layers required by any county, city, state, or country governmental agency for infrastructure planning, urban planning, and developing an effective, efficient information model. Digitizing and updating roads can be time-consuming. This model automates most of the digitizing process. It is based on the MultiTaskRoadExtractor in arcgis.learn model, which is a state-of-the-art model that provides connected road segments such as those shown in the following image:
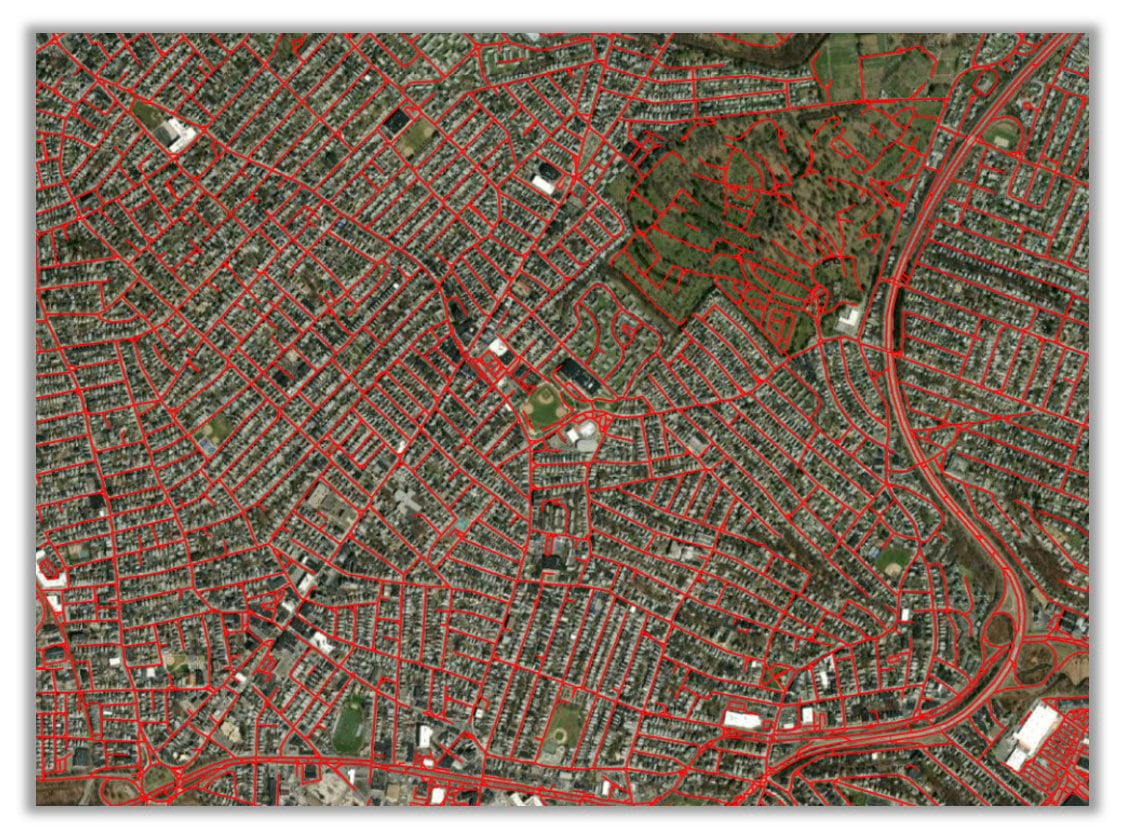
Extracting road networks from satellite images often produces fragmented road segments when a semantic segmentation model such as U-Net is used. This is because satellite images pose difficulties in road extraction due to occlusion caused by trees, buildings (in off-nadir imagery), and shadows. This model uses multitask learning, which is inspired by how humans annotate roads by tracing them at specific orientations.
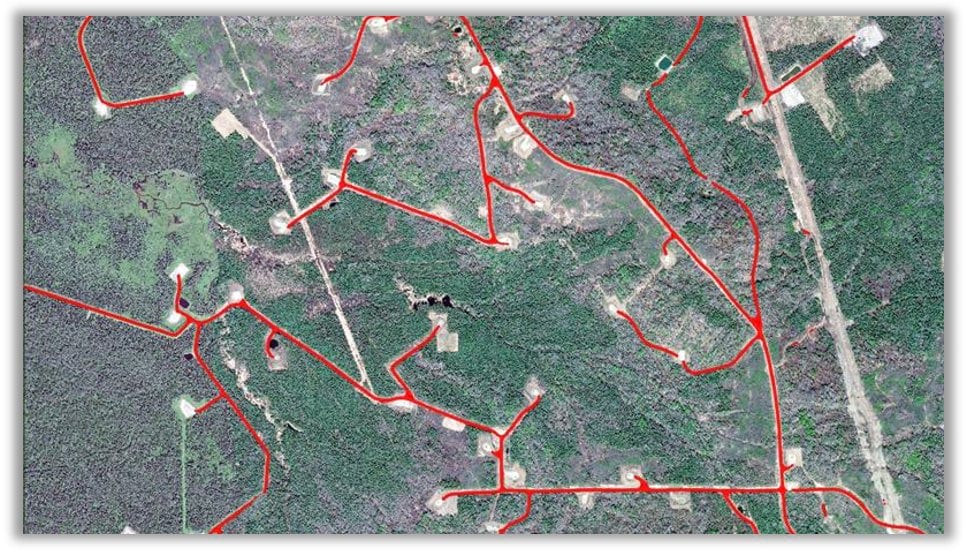
This model also works on dirt roads and well pad access roads such as those shown in the following image:
Land Cover Classification
In October 2020, Esri released its first land cover model that was trained on the National Land Cover Database (NLCD) dataset in the United States and works on Landsat-8 scenes. The resultant land cover maps can be used for understanding urban planning, resource management, change detection, agriculture, and a variety of other applications in which information related to the earth's surface is required.
Today, a new Land Cover Classification model is being released that has higher resolution, as it works with Sentinel-2 imagery. This model works across Europe. It is trained on CORINE Land Cover (CLC) 2018 with the same Sentinel-2 scenes that were used to produce the database. Land cover classification is a complex exercise and is difficult to capture using traditional methods. Deep learning models have a high capacity to learn these complex semantics and provide superior results, as shown below.
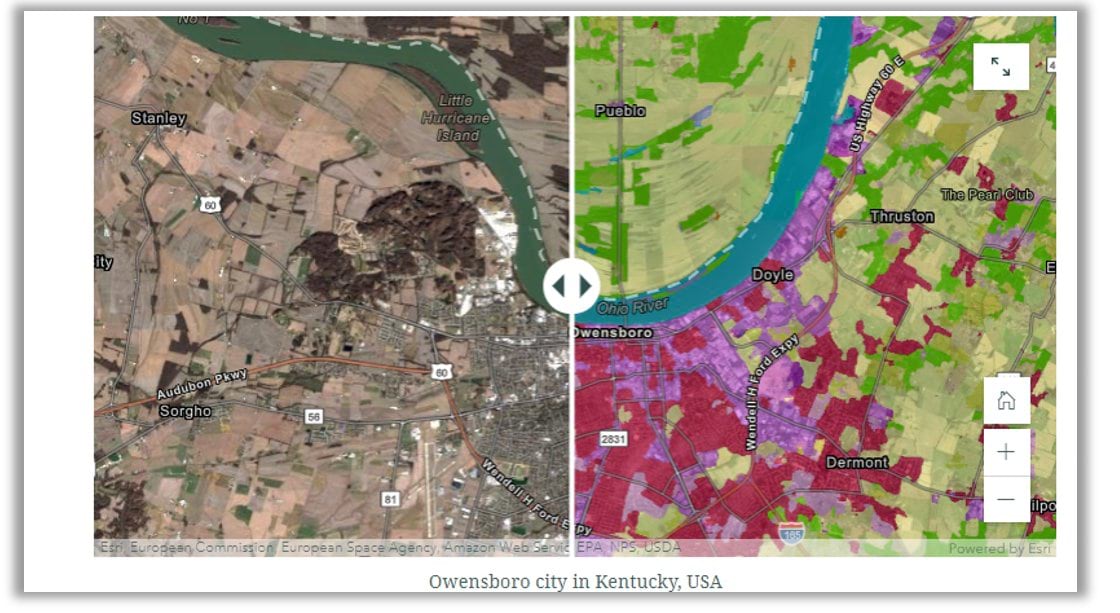
This story map shows the results of this model across several geographies.
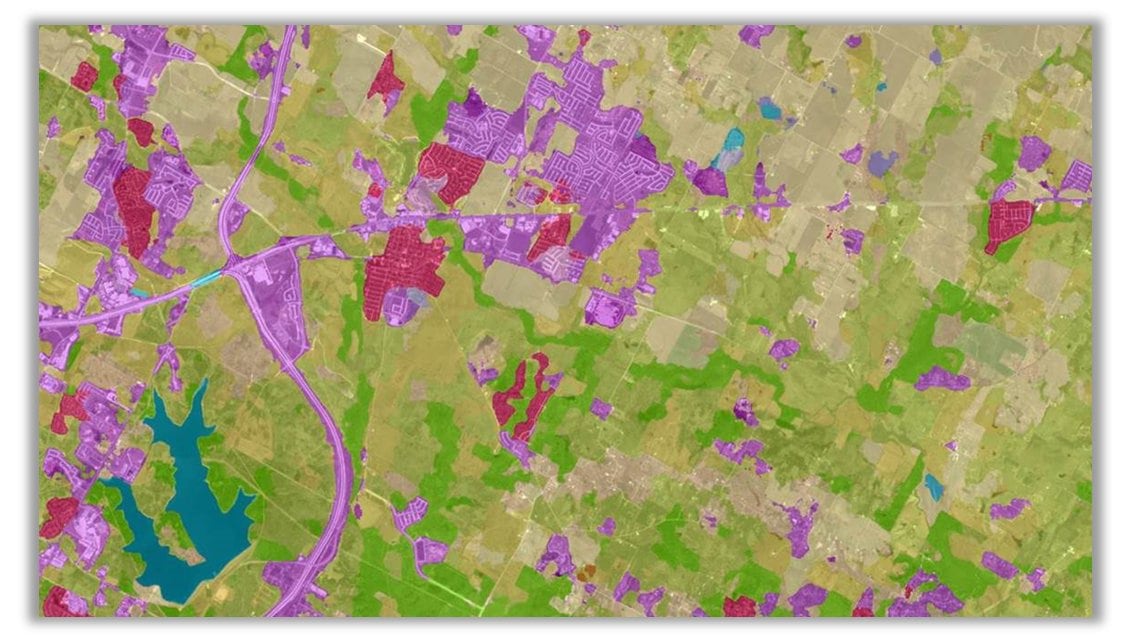
This model can also be used for change detection, as you can run it on imagery from two different times and see the change in land cover, such as that caused by a wildfire. In the image below, you can see the growth of urbanization. New residential areas are shaded in red.
Human Settlements
While high-resolution maps provide value in understanding human settlement patterns, creating small-scale maps derived from relatively lower resolution satellite imagery brings its own value to understanding regional or global growth patterns, population distribution, resource management, change detection, and a variety of other statistics. One example is vaccination planning; only by finding all the unmapped villages can you be sure that your vaccine is reaching all the people that need it.
The following image shows the results from the new Human Settlements model that works on Landsat 8 imagery and extracts such settlements:

You can see how urbanization is affecting areas across the globe with this model. For example, you can see how the human footprint has increased around Sharjah in the UAE from 2015 to 2021 in the following images:
 We have also released a Human Settlements Extraction model that works on Sentinel imagery.
We have also released a Human Settlements Extraction model that works on Sentinel imagery.
Shipwreck Detection
In addition to aerial imagery, these new models include one that detects shipwrecks using bathymetric data. Albeit a niche industry, it is a critical requirement to keep S57 nautical charts up to date. Unmarked shipwrecks can lead to disasters damaging vessels or ports resulting in loss of life and property.

This model includes a geoprocessing tool that provides the necessary preprocessing steps and simplifies the process.
License Plate Blurring and Face Blurring
With the increasing number of sensors, the influx of data, and the democratization of a lot of that data, issues such as privacy are of concern. We have released two models to address this need. These models are used to anonymize or redact faces and car license plates from street-view imagery. You can use these models with the Classify Pixels Using Deep Learning tool in ArcGIS Pro.
Sample results from the model are shown in the following image:

These are just a few of the models that have been developed over the past few months to automate and simplify your workflows. Try them out.
Published at DZone with permission of David Cardella. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments