Efficient Artificial Intelligence: Training to Production
With the advancements in artificial intelligence, the models are getting increasingly complex, resulting in increased size and latency.
Join the DZone community and get the full member experience.
Join For FreeWith the advancements in artificial intelligence (AI), the models are getting increasingly complex, resulting in increased size and latency, leading to difficulties in shipping models to production. Maintaining a balance between performance and efficiency is often a challenging task, and the faster and more lightweight you make your models, the further along they can be deployed into production. Training models on massive datasets with over a billion parameters results in high latency and is impractical for real-world use.
In this article, we will be delving into techniques that can help make your model more efficient. These methods focus on reducing the models’ size and latency and making them ready for deployment without any significant degradation in performance.
1. Pruning
One of the first methods we would discuss is model pruning. More often than not, deep learning models are trained on extensive datasets, and as the neural networks keep getting trained, there are connections within the network that are not significant enough for the result. Model pruning is a technique to reduce the size of the neural networks by removing such less important connections. Doing this results in a sparse matrix, i.e., certain matrix values are set to 0. Model pruning helps not only in reducing the size of the models but also in inference times.
Pruning can be broadly classified into two types:
- Structured pruning: In this method, we remove entire groups of weights from the neural networks for acceleration and size reduction. The weights are removed based on their L-n norm or at random.
- Unstructured pruning: In this method, we remove individual connections of weights. We zero out the units in a tensor with the lowest L-n norm or even at random.
Additionally, we also have magnitude pruning, wherein we remove a percentage of weights with the smallest absolute values. But, to get an ideal balance between performance and efficiency, we often follow a strategy called iterative pruning as shown in the figure below.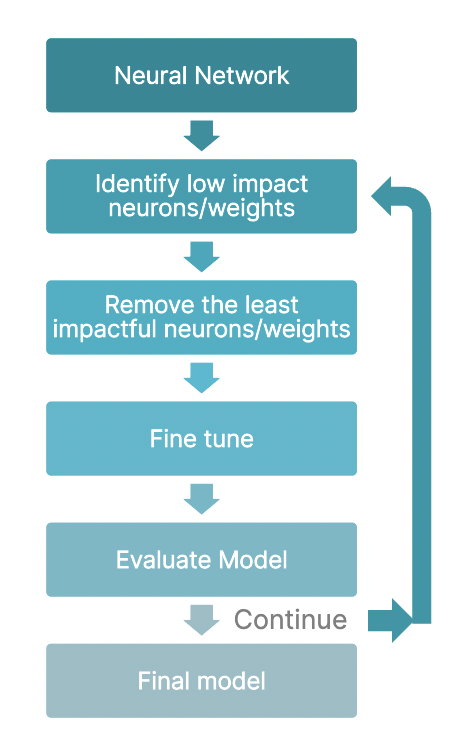
It's important to note that sparse matrix multiplication algorithms are critical in order to maximize the benefits of pruning.
2. Quantization
Another method for model optimization is quantization. Deep learning neural networks are often comprised of billions of parameters, and by default, in machine learning frameworks such as PyTorch, these parameters are all stored as 32-bit floating precision, which leads to increased memory consumption and increased latency. Quantization is a method that lowers the precision of these parameters to lower bits, such as floating-point 16-bit or 8-bit integers. Doing this reduces the computational costs and memory footprint for the model as 8 8-bit integer takes four times less space as compared to FP32.
We can broadly classify quantization as follows:
- Binary quantization: By representing weights and activations as binary numbers (that is, -1 or 1), you may significantly reduce the amount of memory that is required and the amount of computation that is required.
- Fixed-point quantization: Decrease numerical precision to a predetermined bit count, such as 8-bit or 16-bit, facilitating efficient storage and processing at the expense of some degree of numerical accuracy.
- Dynamic quantization: Modifying numerical precision in real-time during inference to balance model size and computing accuracy.
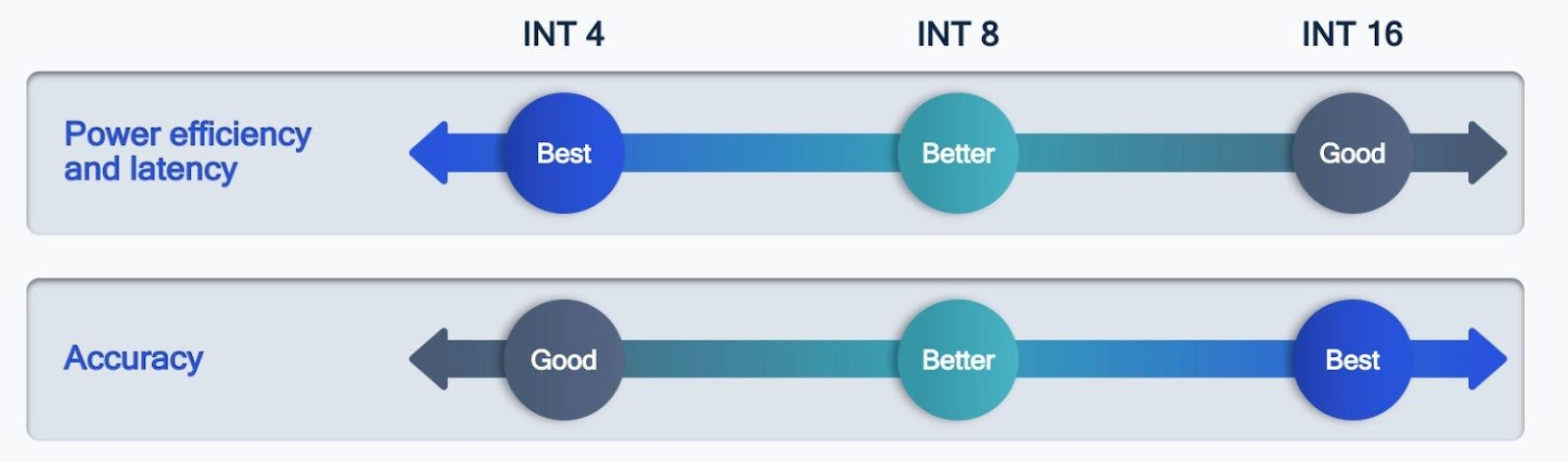
Source: Qualcomm
3. Knowledge Distillation
In the domain of model optimization, another effective methodology is knowledge distillation. The basic idea behind knowledge distillation is how a student learns from its teacher. We have an original pre-trained model which has the entire set of parameters, and this is known as the teacher model. Then, we have a student model that directly learns from the teacher model’s outputs rather than from any labeled data. This allows the student model to learn much faster as it learns from a probability distribution known as soft targets over all possible labels.
- In knowledge distribution, the student model need not have an entire set of layers or parameters, thereby making it significantly smaller and faster and, at the same time, providing similar performance as compared to the teacher model.
- KD has been shown to reduce model size by 40% while maintaining ~97% of the teacher model’s performance.
![Diagram
Description automatically generated]()
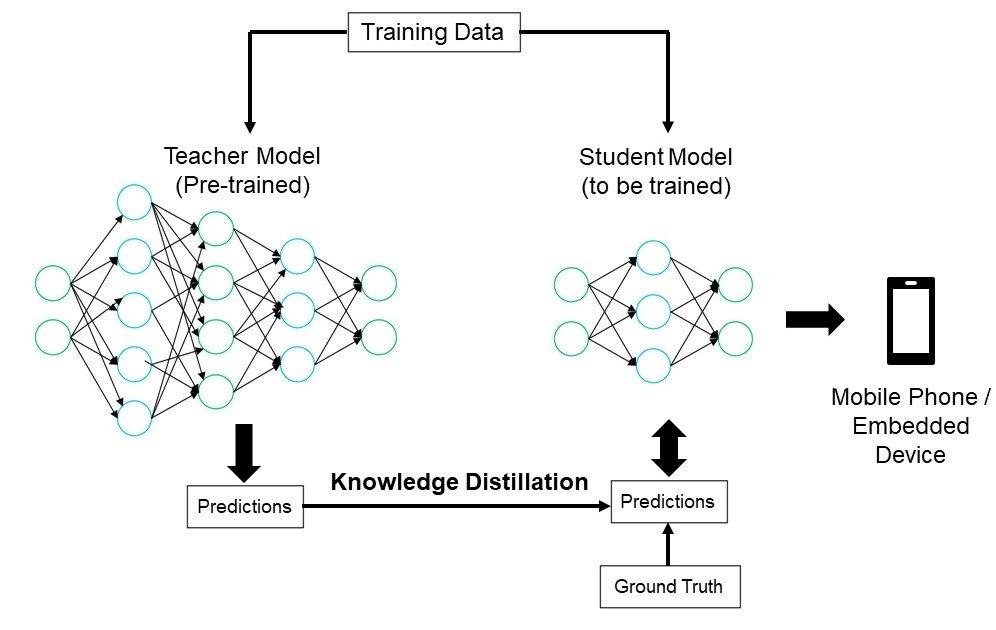
Implementing knowledge distillation can be resource-intensive. Training a child model for a complex network such as BERT typically takes 700 GPU hours, whereas training it from scratch or the teacher model would take around 2400 GPU hours. However, given the performance retention by the child model and efficiency gains, knowledge distillation is a sought-after method for optimizing large models.
Conclusion
The advancement of deep neural networks has resulted in heightened complexity of the models employed in deep learning. Currently, models may possess millions or even billions of parameters, necessitating substantial computational resources for training and inference. Model optimization solutions aim to reduce the computational requirements of complex models while enhancing their overall efficiency.
Numerous applications, especially those implemented on edge devices, possess limited access to computational resources such as memory, computing power, and energy. This is particularly applicable to edge devices. Optimizing models for these resource-constrained environments is essential for facilitating efficient deployment and real-time inference. Methods such as pruning, quantization, and knowledge distillation are some of the model optimization methods that can help achieve it.
Opinions expressed by DZone contributors are their own.
Comments