SIEM Volume Spike Alerts Using ML
This article covers a brief introduction to SIEM, data engineering problems in log collection, and solutions using the ML approach.
Join the DZone community and get the full member experience.
Join For FreeSIEM stands for Security Information and Event Management. SIEM platforms offer centralized management of security operations, making it easier for organizations to monitor, manage, and secure their IT infrastructure. SIEM platforms streamline incident response processes, allowing security teams to respond quickly and effectively to security incidents. SIEM solutions help organizations achieve and maintain compliance with industry regulations and standards by providing centralized logging and reporting capabilities. SIEM systems enable early detection of security threats and suspicious activities by analyzing vast amounts of log data in real time.
Key Components in SIEM
- Log Collection: SEIM systems collect and aggregate log data from Various sources across an organization’s network, including servers, endpoints, firewalls, applications, and other devices.
- Normalization: The collected logs are normalized into a common format, allowing for easier analysis and correlation of security events.
- Correlation Engine: SIEM systems analyze and correlate the collected data to identify patterns, anomalies, and potential security incidents. This helps in detecting threats and attacks in real time.
- Alerting and Notification: SIEM platforms generate alerts and notifications when suspicious activities or security incidents are detected. Security analysts can then investigate and respond to these alerts promptly.
- Incident Response: SIEM systems facilitate incident response by providing investigation, forensics, and remediation tools. They offer capabilities for tracking and documenting security incidents from detection to resolution.
- Compliance Reporting: SIEM solutions help organizations meet regulatory compliance requirements by providing reporting and audit trail capabilities. They generate reports that demonstrate adherence to security policies and regulations.
Problem Statement
In Data Engineering, the data/log collection is a challenging task for high-volume sources. For example, in big organizations, the Linux logs may be around 10 billion, and firewall logs may be around five billion per day. Volume spikes in log collection result from sudden increases in data, impacting the data ingestion process, impacting the platform at the storage level, and networking.
Solution
Leveraging ML algorithms for identifying volume spikes early enhances the effectiveness and efficiency of log monitoring and enables organizations to stay ahead of scalability issues and operational challenges. Using machine learning (ML) algorithms for identifying volume spikes offers several advantages over traditional monitoring methods:
- Complex Patterns: ML algorithms can identify intricate patterns in log data that may be challenging for traditional monitoring systems to detect. They can analyze multiple variables simultaneously and adapt to changing patterns over time.
- Scalability: ML models can scale to handle large volumes of log data efficiently. They can process vast amounts of information in real time, making them suitable for environments with dynamic and high-volume data streams.
- Anomaly Detection: ML algorithms excel at anomaly detection, making them effective in identifying volume spikes and other unusual patterns that may indicate security threats or operational issues. They can differentiate between normal fluctuations and abnormal behaviors.
- Adaptability: ML models can adapt to evolving data patterns and learn from new information over time. They can dynamically adjust detection thresholds and update their algorithms to improve accuracy and reduce false positives.
- Predictive Capabilities: ML algorithms can forecast future trends and predict potential volume spikes based on historical data patterns. This proactive approach allows organizations to take preemptive measures to mitigate risks and optimize resource allocation.
There are different kinds of supervised and unsupervised algorithms (or homegrown solutions) to choose from for this particular solution. The algorithm used below is the forest isolation algorithm. Isolation Forest offers a lightweight, scalable, and effective approach to anomaly detection, particularly in high-dimensional datasets where traditional supervised learning algorithms may struggle or require extensive preprocessing.
Code Block
from sklearn.ensemble import IsolationForest
import pandas as pd
# Sample data (replace with your actual data)
data = {
'feed_type': ['linux', 'linux', 'linux', 'linux', 'linux', 'PA', 'PA', 'PA', 'PA', 'linux', 'linux', 'linux', 'linux', 'PA', 'PA', 'PA', 'PA', 'PA', 'PA', 'PA', 'PA', 'linux', 'linux', 'linux', 'linux', 'linux', 'PA', 'PA', 'linux', 'linux','PA','PA'],
'volume': [6098989898, 6098989899, 6548989198, 7098989898, 7098989899, 7198989198, 6398989898, 6498989899, 6198989198, 6098989898, 6098989898, 6198989898, 6298989898, 6598989898, 6698989898, 6798989898, 6898989898, 6598989898, 6698989898, 6798989898, 8198989898, 6998989898, 6698989898, 6898989898, 6998989898, 7098989898, 6898989898, 6698989898, 7898989898, 7698989898, 8898989898, 7098989898]
}
# Create a DataFrame
df = pd.DataFrame(data)
# Extract feature names
feature_names = df.columns.tolist()
# Train the model
model = IsolationForest(contamination=0.01) # Adjust contamination based on your dataset
model.fit(df[['volume']])
# Function to detect anomalies
def detect_anomalies(feed_type, volume):
anomaly_prediction = model.predict([[volume]])
return anomaly_prediction[0] == -1, feed_type
# Simulate incoming data
# Sample data (replace with your actual data)
incoming_data = [
{'feed_type': 'linux', 'volume': 8698989898 },
{'feed_type': 'PA', 'volume': 14000000000 }
]
# Check for anomalies for each incoming data point
alerts = []
for data_point in incoming_data:
is_anomaly, feed_type = detect_anomalies(data_point['feed_type'], data_point['volume'])
if is_anomaly:
alerts.append(feed_type)
# Check for anomalies
if alerts:
print(f"Alert: Volume spike detected for {' and '.join(alerts)}!")
# Convert new data to DataFrame
new_df = pd.DataFrame(incoming_data)
# Concatenate existing DataFrame with new DataFrame
df = pd.concat([df, new_df], ignore_index=True)
# Retrain the model with the combined data
model.fit(df[['volume']])
print("Model retrained with new data.")
else:
print("No anomaly detected.")
Sample Results
Normal Volume:
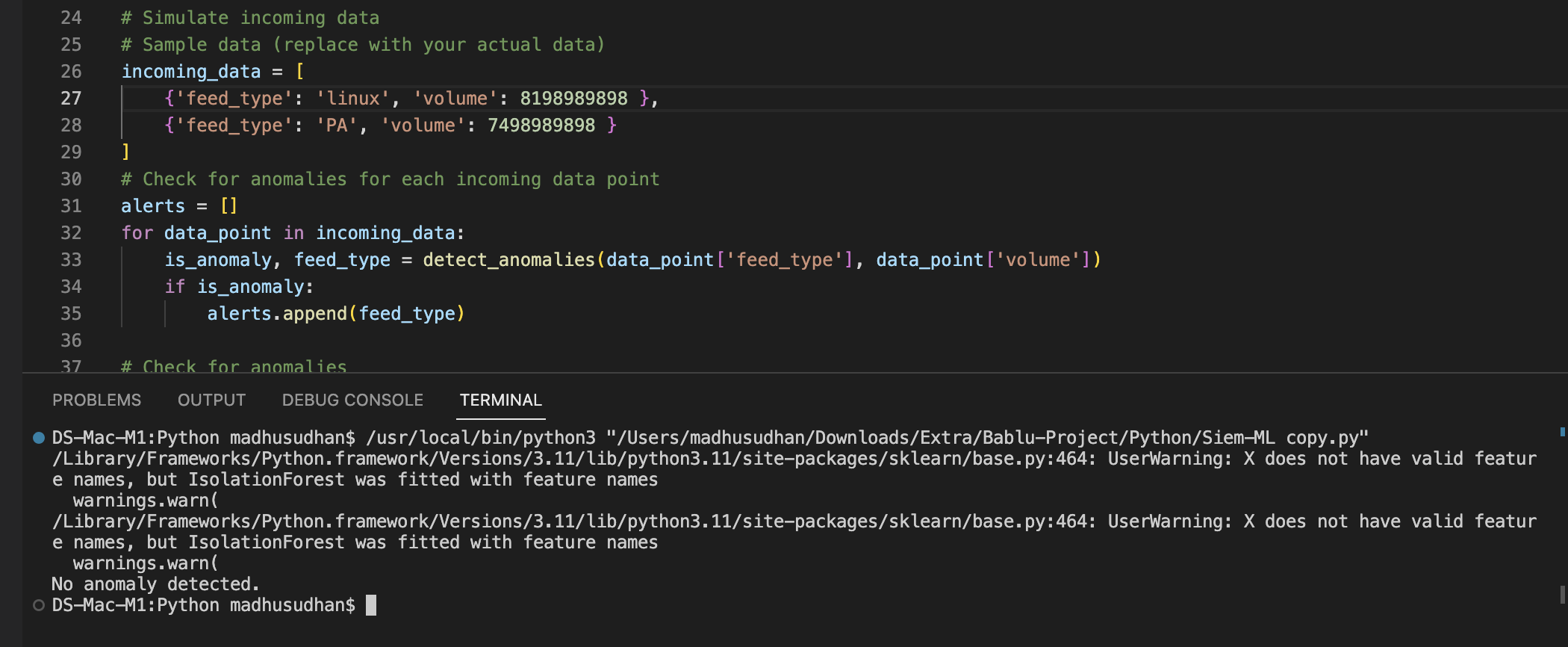
Spike in Volume:

Conclusion
Machine learning algorithms are very useful, particularly in SIEM cyber security space, especially in data engineering, to make organizations proactively address specific problems. Organizations can bolster operational efficiency, enhance system reliability, and fortify their data infrastructure against potential disruptions by leveraging ML for volume spike detection in data ingestion.
Opinions expressed by DZone contributors are their own.
Comments