Ensuring Data Integrity Through Anomaly Detection: Essential Tools for Data Engineers
This article sets out to explore some of the essential tools required by organizations in the domain of data engineering to efficiently improve data quality.
Join the DZone community and get the full member experience.
Join For FreeIn the trending landscape of Machine Learning and AI, companies are tirelessly innovating to deliver cutting-edge solutions for their customers. However, amidst this rapid evolution, ensuring a robust data universe characterized by high quality and integrity is indispensable. While much emphasis is often placed on refining AI models, the significance of pristine datasets can sometimes be overshadowed.
This article sets out to explore some of the essential tools required by organizations in the domain of data engineering to efficiently improve data quality and triage/analyze data for effective business-centric machine learning analytics, reporting, and anomaly detection. To illustrate these tools/frameworks and their importance, let us consider a scenario within the fintech industry.
Scenario
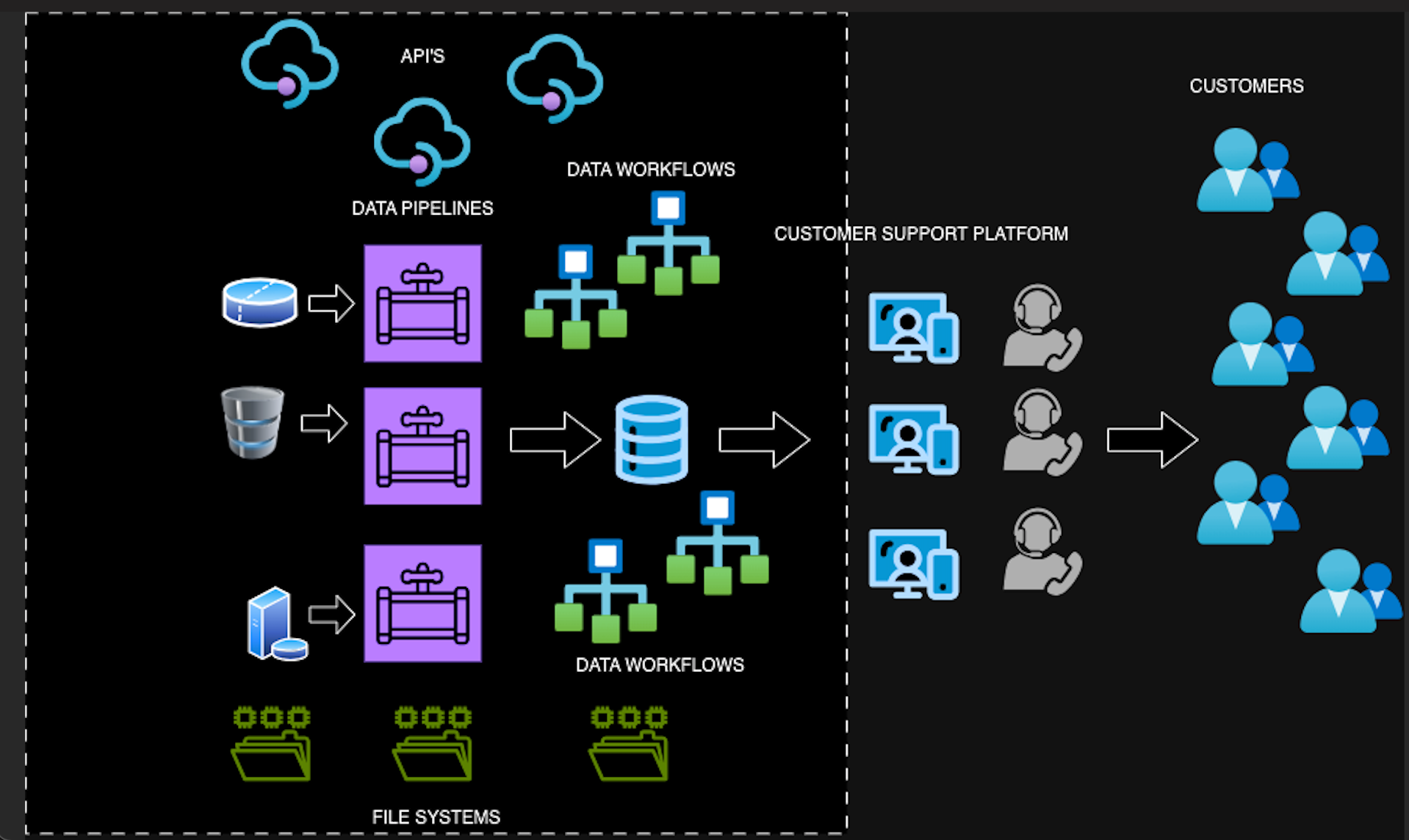
Imagine a customer support team relying on a customer referral platform for sales or marketing leads. These representatives engage with customers over the phone, discussing various offers and programs. Recently, they've encountered instances where recommended phone numbers lead to inaccurate customer details, with no discernible pattern. This challenge not only underscores the importance of data integrity but also highlights the critical role of data engineers in resolving such issues. As stewards of the data universe, primarily data engineering teams are tasked with addressing these challenges by working with the sales team closely.
Please refer to the below figure wherein the sales team works with customers to ensure accurate data, the left side represents the data engineering processes, where data is sourced from various systems, including filesystems, APIs, and databases. Data engineers build and manage complex pipelines and workflows to consolidate this data into a final dataset used by customer support teams. Identifying the source of data issues becomes challenging due to the complexity and number of pipelines in an enterprise organization. Thus, simple questions like, "Where are we sourcing this data?" and "What is broken in this data flow?" become a daunting challenge for data engineers, given that an enterprise organization could be maintaining hundreds of pipelines.
Tools
To address this challenge, data engineers need robust tools/frameworks in order to respond to simple customer support inquiries to the highest range of critical leadership insights in a timely manner. These tools should provide capabilities to triage the data flow quickly, witness data values at each layer in the flow easily, and proactively validate data to prevent issues. At a basic level, the three tools/frameworks below would add a lot of value to handle this challenge.
Data Lineage
A tool captures the data flow from its origin through various transformations and finally to its destination. It provides a clear map of where data comes from, how it is processed, and where it goes, helping data engineers quickly identify the lineage of data constructed.
Data Watcher
A data-watching tool allows engineers to monitor data values in real time at different stages of the pipeline. It provides insights into data values, potentially anomalies associated with them and its trends, enabling prompt responses to any irregularities and empowering even business to get involved for triaging.
Data Validator
A data validation tool checks data at various points in the pipeline to ensure it meets predefined standards and rules. This proactive validation helps in catching and correcting data issues before they propagate through the system.
Deeper Dive Into Each Tool
In order to dive deeper into the concept of each of these tools with the challenge posted, we will consider a data structure with a workflow defined. In this case, we have a customer entity represented as a table in which the attributes are fed from a File System and an API.
customer_type - platinum
customer_id - 23456
address_id - 98708512
street address - 22 Peter Plaza Rd
state - New Jersey
country - USA
zip_code - 07090
phone_number - 201-567-5678From a DFD (Data Flow Diagram) standpoint, the workflow would look as below,
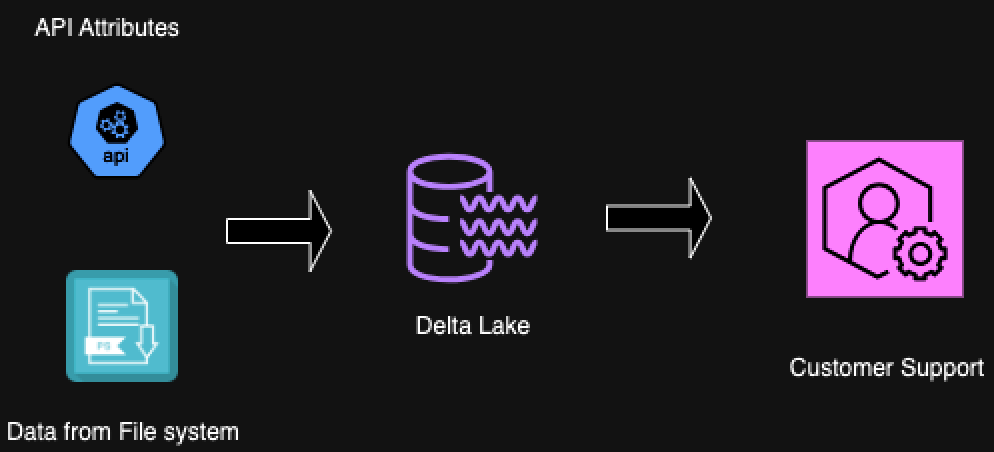
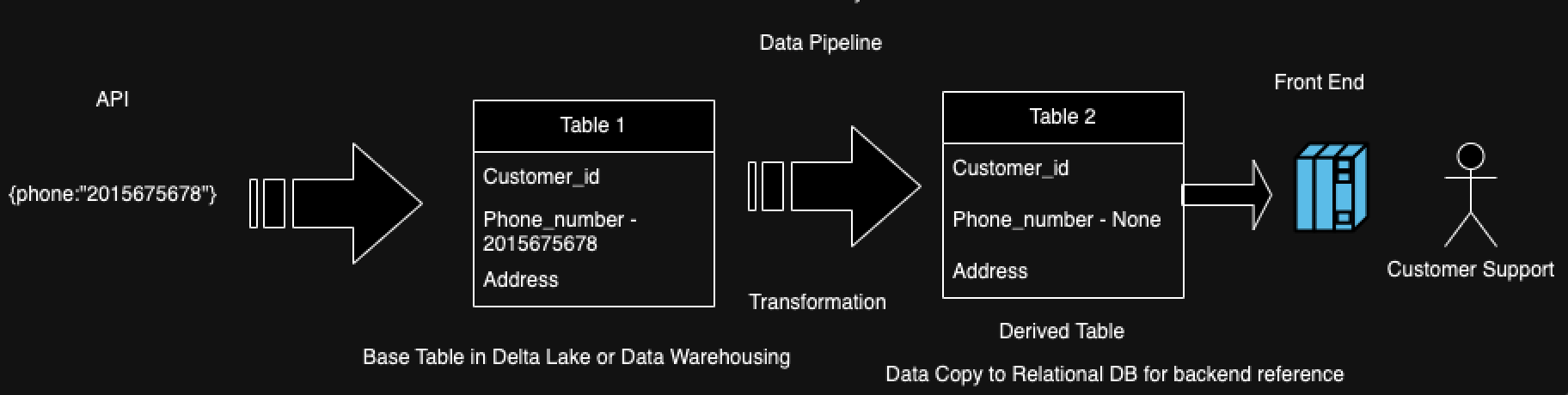
To simplify, consider a scenario where the customer_type and phone numbers are obtained through an API, while address details are sourced from a file system. To re-emphasize the original challenge, the phone number is missing in the final customer support platform. From a data triaging standpoint, a data engineer needs to trace the source of the phone number among numerous data pipelines and tables, find the source of this phone number attribute first, and understand its lineage.
Data Lineage
In any data flow at a given point of time, a set of data elements are persisted and the ETL processes are applied to load the transformed data. For effectively triaging the data and finding its lineage, the following basic setups are required:
1. Configuration Mapping Data Elements to Sources
This involves creating a comprehensive map that links each data element to its respective source. This mapping ensures traceability and helps in understanding where each piece of data originates.
2. Extensible Configuration To Add New Downstream Workflows
As new workflows are introduced, the configuration should be flexible enough to incorporate these changes without disrupting existing processes. This extensibility is crucial for accommodating the dynamic nature of data pipelines.
3. Evolvable Configuration to Accommodate Changes in Source Elements
Data sources can change over time, whether due to schema updates, new data sources, or modifications in data structure. The configuration must be adaptable to these changes to maintain accurate data lineage.
This lineage can mostly be inferred from code if it involves plain SQL by referencing the code bases. However, it becomes more complex when different languages like Python or Scala are involved alongside SQL. In such cases, manual intervention is needed to maintain the configuration and identify the lineage. This can be achieved in a semi-automated fashion. This complexity arises due to the diverse syntax and semantics of each language, making automated inference challenging.
Leveraging GraphQL for Data Lineage
GraphQL can be utilized for maintaining data lineage by using nodes and edges to represent data elements and their relationships. This approach allows for a flexible and queryable schema that can easily adapt to changes and new requirements. By leveraging GraphQL, organizations can create a more interactive and efficient way to manage and visualize data lineage.
Several data lineage tools are available in the market, each offering unique features and capabilities: Alation, Edge, MANTA, Collibra, Apache Atlas and individual cloud providers are providing their own cloud-based lineage.
After identifying the source, now we need to have the ability to see if the phone number that came from the source is actually propagated in each transformation or load without changing its value. Now in order to have this data matching to be observed, we need a very simple unified mechanism that can bring this data together and show it.
Let's dive into data watching.
Data Watcher
The data-watching capability can be achieved by leveraging various database connectors to retrieve and present the data cleanly from distinct data sources. In our example, the phone attribute value is properly ingested from the API to the table, but it is getting lost when writing to the front end. This is a classic case of data loss. By having visibility into this process, data engineers can quickly address the issue.
Below are the noticeable benefits of having a Unified Data Watching Approach.
- Quick identification of discrepancies: Helps data engineers swiftly identify and resolve data discrepancies, ensuring data quality
- Simplified data retrieval and presentation: Streamlines the process of retrieving and presenting data, saving time and effort
- Unified data view: Provides a unified view of data, making it easier for business stakeholders to derive insights and make informed decisions
- Data accuracy and consistency: Empowers end-users to ensure that data from different sources is accurate and consistent
Having the ability to track data sourcing, timeliness, and accuracy enhances confidence across the organization. We have discussed the concepts of data lineage and data watching to understand data sourcing, track data at different ingestion and transformation points, and observe its value at each stage. There are no explicit tools that solely offer data-watching capabilities; these functionalities are often by-products of some of the data discovery or data cataloging tools. Organizations need to develop unified platforms based on their specific requirements. Tools like Retool and DOMO are available to unify data into a single view, providing a consolidated and clear representation of data flow.
In the next section, we will explore how to monitor data quality and notify teams of issues to prevent incorrect data from propagating to final systems. This proactive approach ensures data integrity and reliability, fostering trust and efficiency within the organization.
Data Validator
Data validation is a crucial process in ensuring the quality and integrity of data as it flows through various pipelines and systems. Regularly refreshed data needs to be validated to maintain its accuracy and reliability. Data validation can be performed using different methods and metrics to check for consistency, completeness, and correctness. Below are some of the key metrics for data validation:
- Freshness: Measures how up-to-date the data is; Ensures that the data being processed and analyzed is current and relevant
- Example: Checking the timestamp of the latest data entry
- Missing count: Counts the number of missing or null values in a dataset; Identifies incomplete records that may affect data quality
- Example: Counting the number of null values in a column
- Missing percent: Calculates the percentage of missing values relative to the total number of records; Provides a clearer picture of the extent of missing data in a dataset.
- Example: (Number of missing values/Total number of records) * 100
- Average: Computes the mean value of numerical data; Helps in identifying anomalies or outliers by comparing the current average with historical averages.
- Example: Calculating the average sales amount in a dataset
- Duplicate counts: Counts the number of duplicate records in a dataset; Ensures data uniqueness and helps in maintaining data integrity.
- Example: Counting the number of duplicate customer IDs in a table.
Several libraries provide built-in functions and frameworks for performing data validation, making it easier for data engineers to implement these checks. Please find below some of the libraries and sample code to get a sense of validation and implementation.
- SODA: SODA (Scalable One-stop Data Analysis) is a powerful tool for data validation and monitoring. It provides a comprehensive set of features for defining and executing data validation rules, supports custom metrics, and allows users to create checks based on their specific requirements.
- Great Expectations: Great Expectations is an open-source library for data validation and documentation. Allows users to define expectations, which are rules or conditions that the data should meet. It supports automatic profiling and generating validation reports.
Implementing data validation involves setting up the necessary checks and rules using the chosen library or framework. Here’s an example of how to implement basic data validation using Great Expectations:
import great_expectations as ge
# Load your dataset
df = ge.from_pandas(your_dataframe)
# Define expectations
df.expect_column_values_to_not_be_null("column_name")
df.expect_column_mean_to_be_between("numeric_column", min_value, max_value)
df.expect_column_values_to_be_unique("unique_column")
# Validate the dataset
validation_results = df.validate()
# Print validation results
print(validation_results)In the above example:
- We load a dataset into a Great Expectations DataFrame.
- We define expectations for data quality, such as ensuring no null values, checking the mean value of a numeric column, and ensuring the uniqueness of a column.
- We validate the dataset and print the results.
Conclusion
As part of this article, we explored the options of leveraging data lineage, data watching, and data validation, so that organizations can build a robust data management framework that ensures data integrity, enhances usability, and drives business success. These tools collectively help maintain high data quality, support complex analytics and machine learning initiatives, and provide a clear understanding of data assets across the organization.
In today's data-driven world, the ability to maintain accurate, reliable, and easily discoverable data is critical and these tools enable organizations to leverage their data assets fully, drive innovation, and achieve their strategic objectives effectively. These frameworks, along with a variety of tools like data cataloging and data discovery features, empower business users to have broader visibility of the data, and, thereby, helping in innovation from business and technical arenas.
Opinions expressed by DZone contributors are their own.
Comments