Session Management in Distributed Databases
Session management in distributed databases is fundamental to ensuring data consistency. In this article, learn about session consistency and session tokens.
Join the DZone community and get the full member experience.
Join For FreeDistributed databases partition the data across several nodes, spreading across regions depending on the database configuration. Such partitioning is fundamental to achieving scalability. All such cloud-native databases have some sort of a session management layer. A session, in plain terms, is the span of communication between a database client and server. It can span multiple transactions. I.e., in a given session, a client can do many writes and reads. The session management layer is usually responsible for guaranteeing “read your own writes”. I.e., data written by a user must be available for reading in the same session.
Session Consistency
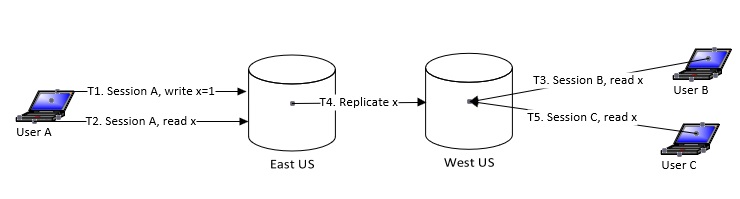
In the distributed database world, with many regions serving the database, reads can happen from anywhere. There is fundamentally a need to distinguish between “Not Found” and “Not Available” scenarios. I.e. in the former case data does not exist while in the latter case, data is yet to be seen by the region. This is important to provide a “read your own write” guarantee. For example, let’s look at the time steps that happen in the below picture.
- T1: User A using session A is writing the value of x as 1.
- T2: User A using the same session A is attempting to read the value of x. The returned output will be 1.
- T3: User B in session B is reading a value of x but will get “Not Found” since the West US region has not yet seen the data.
- T4: The value of x is replicated from the East US to the West US region.
- T5: User C in session C when reading the value of x will now see the value as 1.
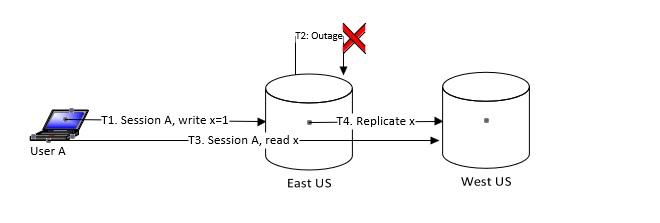
Now let’s look at the scenario of the outage, as shown in the picture below.
- T1: User A using session A is writing the value of x as 1.
- T2: Outage happens at East US, and User A is not able to connect to East US.
- T3: The user using the same session A is attempting to read the value of x. Now, the call may get routed to another available region (West US). Note that replication has not been completed. So the user must not be returned “Not Found.” Otherwise, it would break the “read your own write” guarantee.
![outage]()
Session Token
In the outage example shown above, one might wonder what the West US region should do in this case. There are two sub-problems:
- How does a region know it can’t return “Not Found”?
- What action should it alternatively take if it can’t return “Not Found”?
This is where session tokens are useful. A session token contains information about a region’s progress. In the above example, Session A has seen more progress than West US. In that case, by inspecting the session token West US region can determine that it is lagging behind and can’t serve this request. Instead, it can reroute the request back to East US. In such a case, a session token can look like “[East US: 1, West US:0],” indicating East US has progressed by one operation and West US has not seen any operations. To generalize, a typical breakdown of session tokens will look like this:
Session token = “{region1: progress1, region2:progress2 …}”
Conclusion
In conclusion, session management in distributed databases is fundamental to ensuring data consistency. Different databases could implement a session token differently than what is described here but fundamentally they are designed to provide “read your own write” guarantees. In addition, a session token can encode additional information as well, for example, if it has partition information, then the request can be routed to the correct partition within the same region.
Further Reading
Opinions expressed by DZone contributors are their own.
Comments