Scale to Zero With Kubernetes
This article reviews how Kubernetes provides the platform capabilities for dynamic deployment, scaling, and management in Cloud-native applications.
Join the DZone community and get the full member experience.
Join For FreeIn the era of web-scale, every organization is looking to scale its applications on-demand, while minimizing infrastructure expenditure. Cloud-native applications, such as microservices are designed and implemented with scale in mind and Kubernetes provides the platform capabilities for dynamic deployment, scaling, and management.
Autoscaling and scale to zero is a critical functional requirement for all serverless platforms as well as platform-as-a-service (PaaS) solution providers because it helps to minimize infrastructure costs.
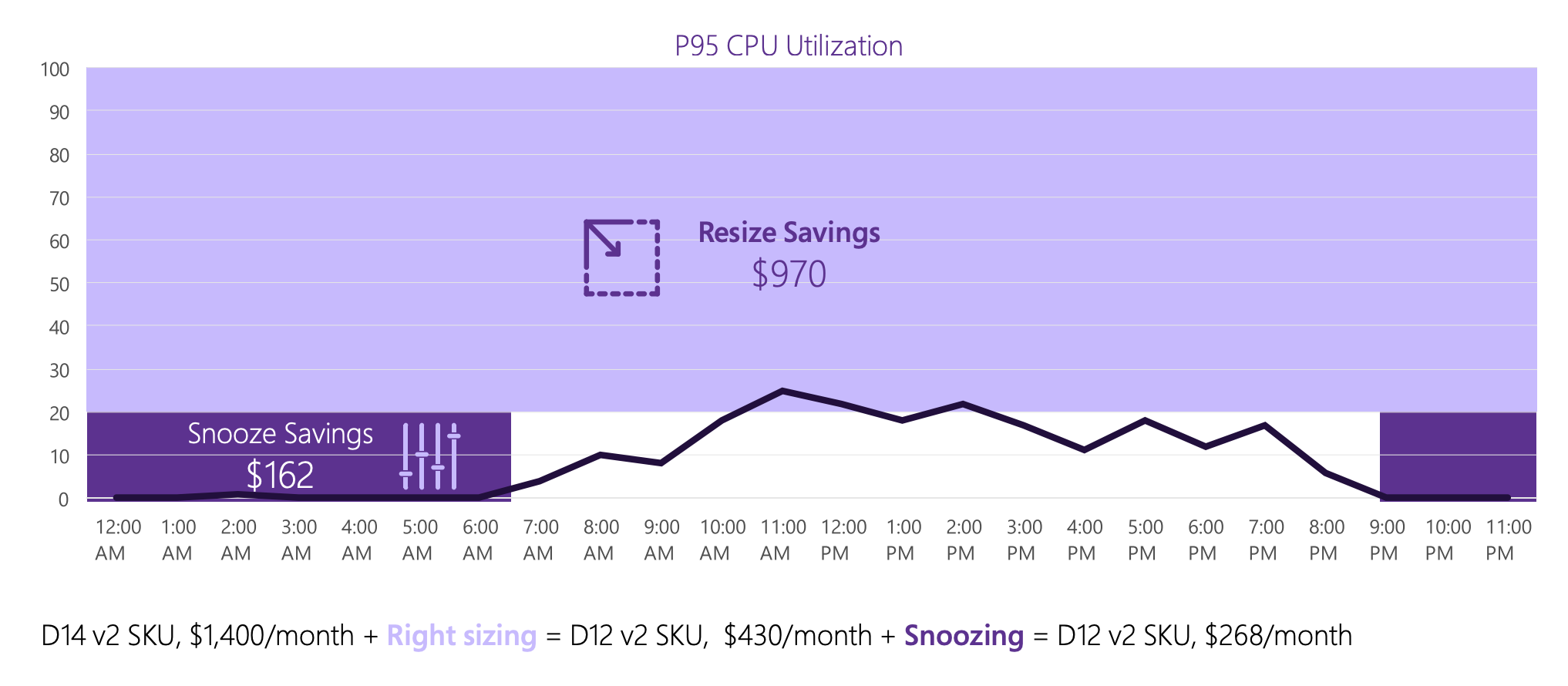
For example, the following graph shows how Microsoft Azure saves money by having autoscaling and snooze (scale to zero) in the Azure PaaS and how their customers have directly benefited from the savings. Even though it is not directly related to Kubernetes deployment, it emphasizes how important to have the autoscaling and scale to zero in your solutions.
Horizontal Pod Autoscaler
Kubernetes’ Horizontal Pod Autoscaler (HPA) automatically scales the application workload by scaling the number of Pods in deployment (or replication controller, replica set, stateful set), based on observed metrics like CPU utilization, memory consumption, or with custom metrics provided by the application.
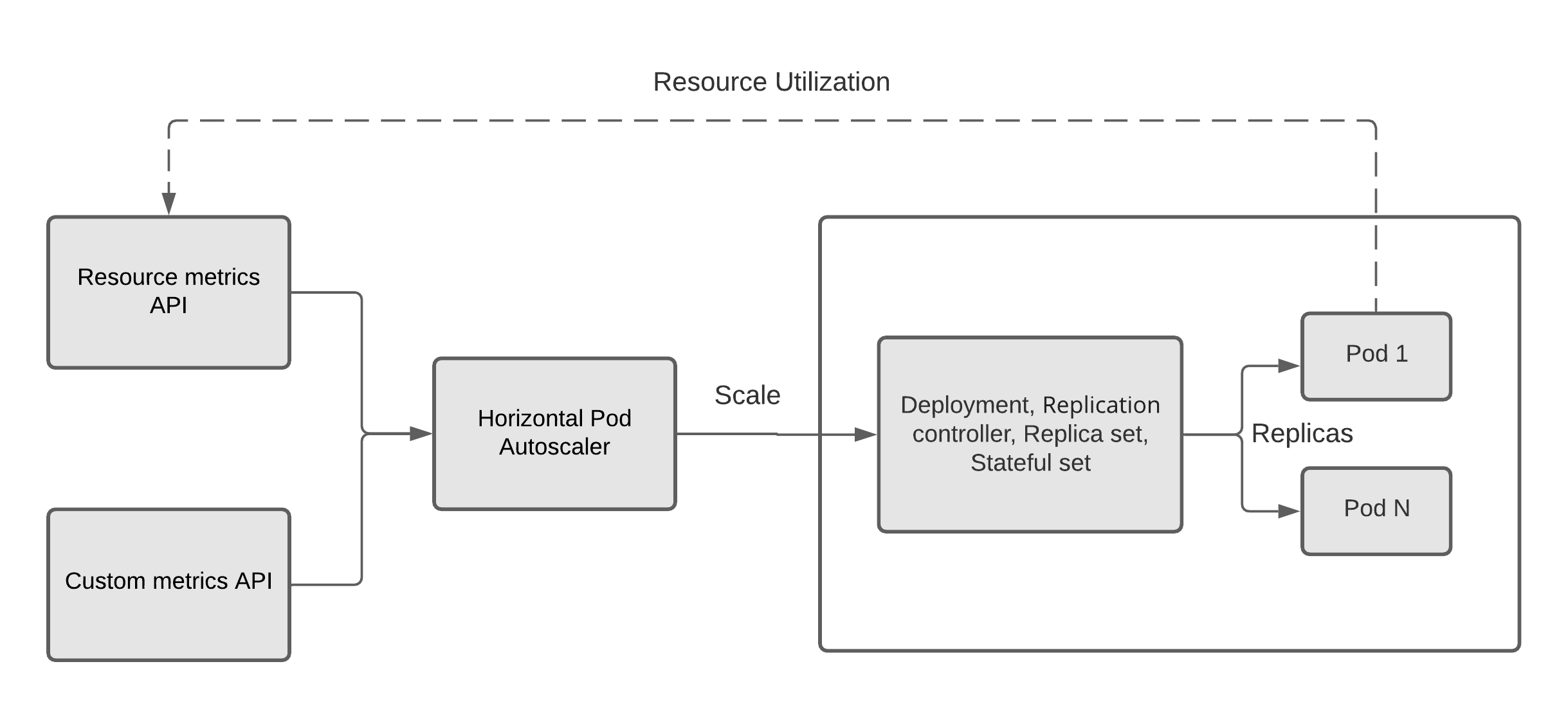
Horizontal Pod Autoscaler
HPA uses the following simple algorithms to determine the scaling decision, and it can scale the deployment within the defined minimum and the maximum number of replicas.
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Kubernetes’ default HPA is based on CPU utilization and desiredReplicas never go lower than 1, where CPU utilization cannot be zero for a running Pod. This is the same behavior for memory consumption-based autoscaling, where you cannot achieve scale to zero. However, it is possible to scale into zero replicas if you ignore CPU and memory utilization and consider other metrics to determine whether the application is idle. For example, a workload that only consumes and processes a queue can scale to zero if we can take queue length as a metric and the queue is empty for a given period of time. Of course, there should be other factors to consider like lower latency sensitivity and fast bootup time (warm-up time) of the workload to have a smooth user experience.
But, the current Kubernetes current stable release (v1.19) does not support scale to zero, and you can find discussions to support this in the Kubernetes enhancements gitrepo. Please refer to the details in issue [1] and pull request [2].
Scale to Zero With Knative
Knative [3] is a serverless platform that is built on top of Kubernetes. It provides higher-level abstractions for common application use cases. One key feature is its ability to run generic (micro) service-based applications as serverless with the help of built-in scale to zero support. Knative has introduced its own autoscaler, Knative Pod Autoscaler (KPA), that supports scale to zero for any service that uses non-CPU-based scaling matrics.
Knative has two main components: Knative Serving and Knative Eventing. Knative Serving focuses on triggering applications using HTTP traffic and Knative Eventing focuses on triggering applications using events.
For autoscaling, Knative Serving automatically scales your application based on the defined maximum number of concurrent requests for that service and to resource conservation. Knative Serving ensures that dormant applications are scaled to zero and ready for the next request. Previously, Knative used Istio Gateway to handle external cluster traffic, but it recently integrated with Kourier, a lightweight ingress based on the Envoy gateway [4].
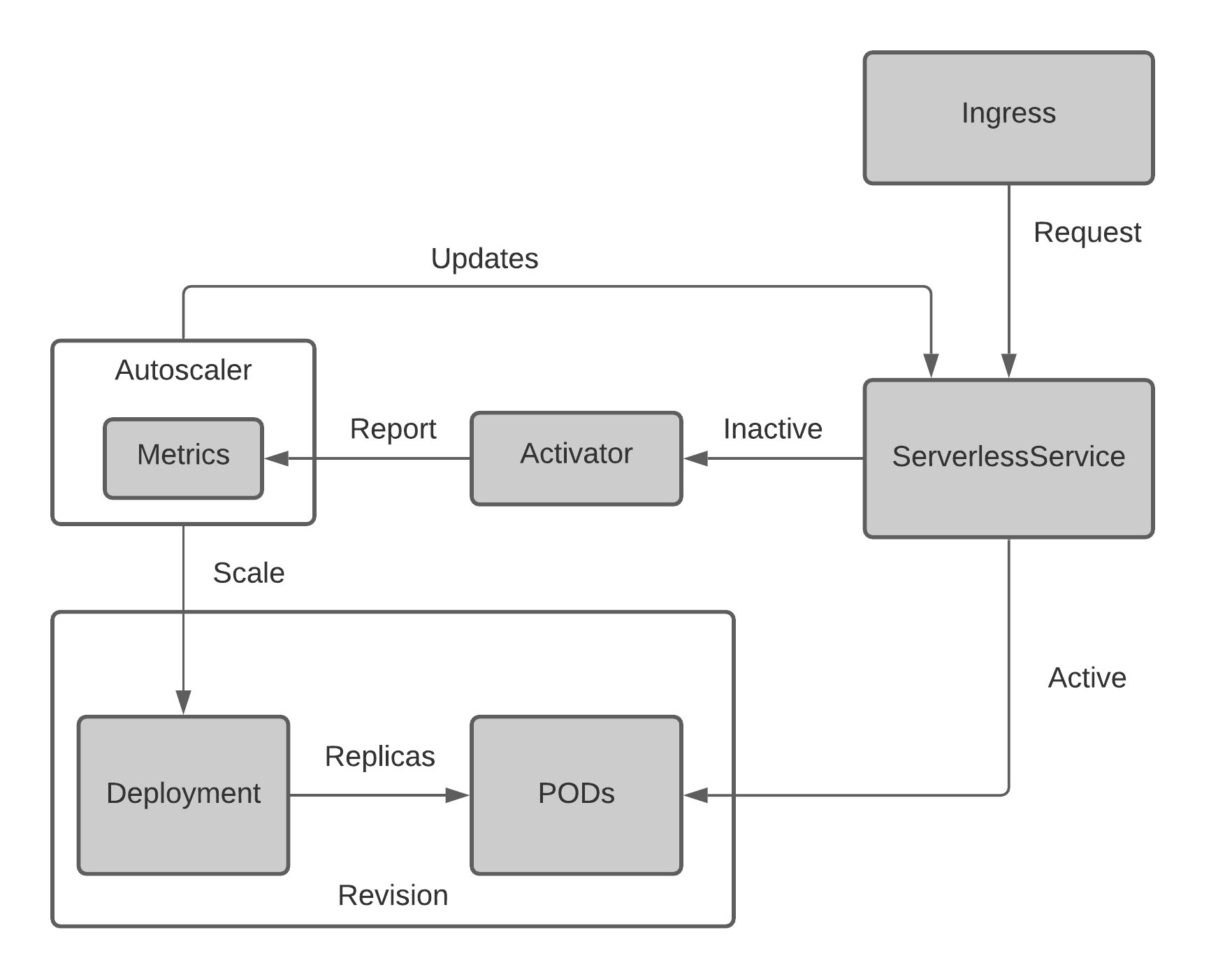
Knative Serving Architecture
HTTP traffic coming through the ingress route to the relevant ServerlessService. If there are no active Pods running, the Knative autoscaler will notify the activator to scale up the deployment in order to have the minimum number of Pods as defined. It will then route the request(s) to the Pods when they are in an active state. If the Pods are already running, the requests will route to the Pods and the metrics will be collected for autoscaling purposes. When ServerlessService/Pods become idle, the autoscaler will scale down the deployment to zero replicas based on the captured metrics from relevant sources and update the ServerlessService component to be ready for the next coming request.
In addition to the Knative Serving HTTP traffic, Knative Eventing is experimenting with the use of KEDA for event source autoscaling and we will explore KEDA in the following section.
Scale to Zero With KEDA
KEDA [5] is a Kubernetes-based Event-Driven Autoscaler. With KEDA, you can drive the scaling of any application in Kubernetes based on the number of events needing to be processed. KEDA acts as an agent to achieve the scale to zero capability by activating and deactivating deployments. It also acts as a Kubernetes metrics server, exposing event data to the HPA.
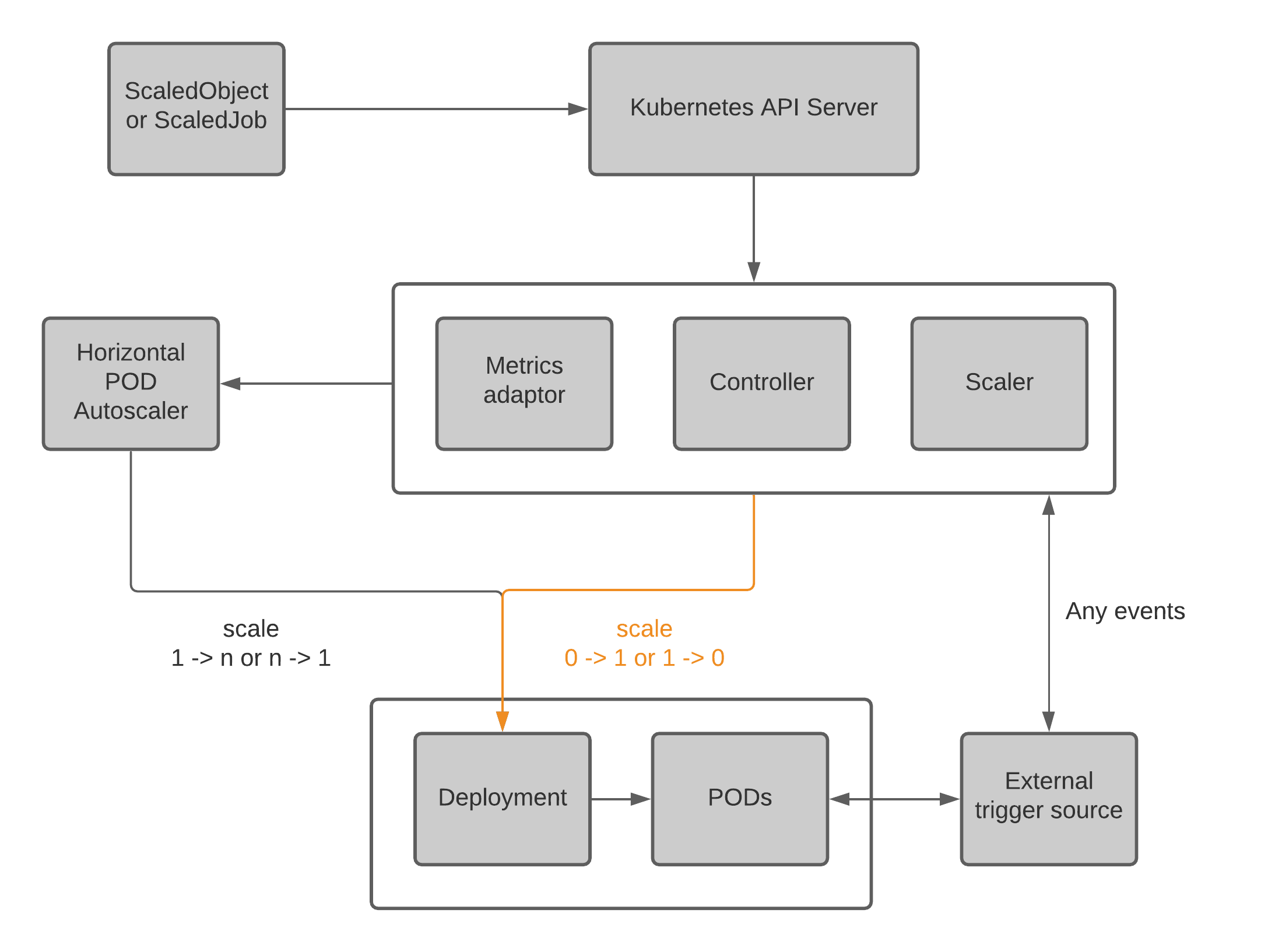
KEDA architecture
KEDA introduces ScaledObject and ScaledJob Custom Resource Definitions (CDRs) to define how KEDA should scale your application with the relevant triggers. In addition to the Kubernetes deployments, you can also run and scale your code as Kubernetes Jobs by defining ScaledJob custom resources.
Other Tools and Platforms
In addition to Knative and KADE, some other serverless platforms and tools support to scale to zero capabilities. However, as far as I discovered, Knative and KADE are the two most mature projects that support scale to zero capability.
Summary
Cloud-native allows organizations to build, deploy, and operate software applications more frequently, resiliently, and reliably. Kubernetes provides a flexible and powerful platform to build many cloud solutions by inheriting cloud-native capabilities. Kubernetes’ autoscaling capabilities allow applications to scale up and down along with the application workload; however, scale to zero does not come out-of-the-box.
Kubernetes-based Event-Driven Autoscaler (KEDA) is a Kubernetes operator that can install on any Kubernetes platform and provide scale to zero by using metrics that expose from event sources. Knative, an open-source serverless platform, supports scale to zero for applications based on metrics captured from HTTP traffic. Knative also supports scale to zero based on metrics captured via event sources by integrating KEDA.
Organizations that are building PaaS and SaaS solutions on top of Kubernetes can reduce infrastructure costs by leveraging scale to zero capabilities and by adopting Knative and KEDA in their solutions.
References
[1] https://github.com/kubernetes/enhancements/issues/2021
[2] https://github.com/kubernetes/enhancements/pull/2022
[4] https://developers.redhat.com/blog/2020/06/30/kourier-a-lightweight-knative-serving-ingress/
Opinions expressed by DZone contributors are their own.
Comments