RPA + Machine Learning = Intelligent Automation
In this article, take a look at robotic process automation, machine learning, intelligent automation, and how they relate to one another.
Join the DZone community and get the full member experience.
Join For Free
Robotic process automation has generated a lot of buzz across many different industries. As businesses focus on digital innovation, automation of repetitive tasks to increase efficiency while decreasing human errors is an attractive proposition.
Robots will not tire, will not get bored, and will perform tasks accurately to help their human counterparts improve productivity and free them up to focus on higher level tasks.
Beyond simple RPA, intelligent automation can be achieved by integrating machine learning and artificial intelligence with robotic process automation to achieve automation of repetitive tasks with an additional layer of human-like perception and prediction.
The Difference Between RPA and Artificial Intelligence
By design, RPA is not meant to replicate human-like intelligence. It is generally designed simply to mimic rudimentary human activities. In other words, it does not mimic human behavior, it mimics human actions. Behavior implies making intelligent choices among a spectrum of possible options, whereas action is simply movement or process execution. RPA processes are most often driven by pre-defined business rules that can be narrowly defined thus RPA has limited abilities to deal with ambiguous or complex environments.
Artificial intelligence, on the other hand, is the simulation of human intelligence by machines, which requires a broader spectrum of possible inputs and outcomes. AI is both a mechanism for intelligent decision making and a simulation of human behaviors. Meanwhile, machine learning is a necessary stepping stone to artificial intelligence, contributing deductive analytics and predictive decisions that increasingly approximate the outcomes that can be expected from humans.
The IEEE Standards Association published its IEEE Guide for Terms and Concepts in Intelligent Process Automation in June 2017. In it, robotic process automation is defined as a “preconfigured software instance that uses business rules and predefined activity choreography to complete the autonomous execution of a combination of processes, activities, transactions, and tasks in one or more unrelated software systems to deliver a result or service with human exception management.”
In other words, RPA is simply a system that can perform a defined set of tasks repeatedly and without fail because it has been specifically programmed for that job. But it cannot apply the function of learning to improve itself or adapt its skills to a different set of circumstances, that’s where machine learning and artificial intelligence are increasingly contributing to building more intelligent systems.
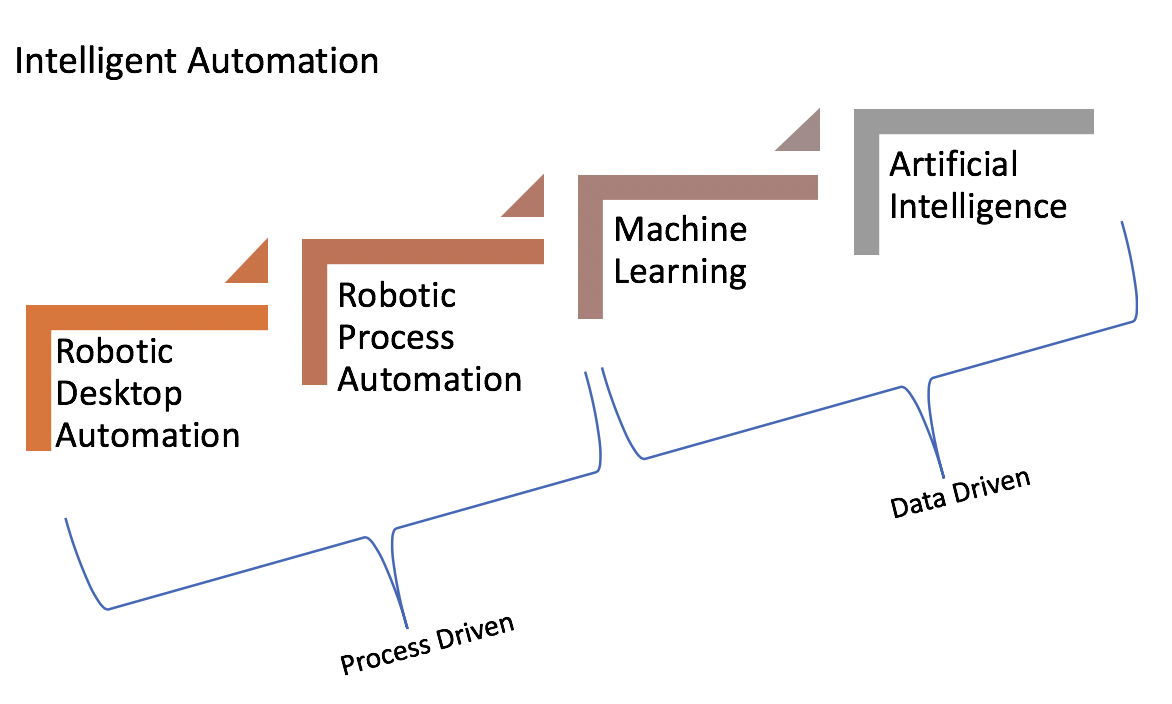
Process-Driven vs Data-Driven
Intelligent Automation is a term that can be applied to the more sophisticated end of the automation-aided workflow continuum consisting of Robotic Desktop Automation, robotic process automation, machine learning, and artificial intelligence. Depending on the type of business, companies will often employ one or more types of automation to achieve improved efficiency and effectiveness. As you move along the spectrum from process-driven automation to more adaptable data-driven automation, there are additional costs in the form of training data, technical development, infrastructure, and specialized expertise. But the potential benefits in terms of additional insights and financial impact can be greatly magnified.
To remain competitive and efficient, businesses now must contemplate adding machine learning and artificial intelligence to traditional RP in order to achieve intelligent automation.
Intelligent Automation Relies on Data Integrity
In the Intelligent Automation framework, training data is a central component on which all else depends. In industries such as autonomous driving and healthcare, where decisions made by AI/ML can have serious repercussions, the accuracy of training data that informs these types of decisions is critical. As the accuracy of modern AI and machine learning models utilizing neural networks and deep learning progress toward 100%, these engines are working more autonomously than ever to make decisions without human intervention. Small variations or inaccuracies in training data can have dramatic and unintended effects. Data integrity and accuracy thus become increasingly more important as humans come to rely on the decisions made by intelligent machines for complicated tasks.
Accurate ML Models Require Accurate Training Data
Data integrity involves starting with representative source data then accurately labeling this data prior to the training, testing, and deployment of machine learning models. An iterative workflow of data preparation, feature engineering, modeling, and validation is the standard Data Science playbook.
Any data scientist will explain that the availability of accurately labeled training data is perhaps the most important ingredient in their recipes. Examples of “dirty” data include missing, biased, and outlier data or simply data sets that are not representative of the future data to be processed in production. Feature engineering is also an important step in the machine learning process i.e. selecting the data features that are likely to be the most critical in informing the predictive accuracy of a given model. In a neural network, where parameters are stacked one on top of the other, correct identification of key features in each iteration is critical to the success of the model-building exercise. Poor training data can cause incorrect features to be selected or weighted, thus leading to models that cannot be generalized to a broader population of production data.
For instance, for a model that detects specific organs in MRI images, choosing representative training images from a particular MRI machine then accurately isolating the relevant boundaries of specific regions of interest for each organ will lead to better detection results than simply using photos of those organs from public sources. Another example can be seen in accounts payable systems using optical character recognition (OCR) to programmatically extract relevant information from invoices. Key fields in each invoice such as “Address”, “Name,” and “Total” must be accurately distinguished from the body of different types of invoices in order to create an effective and accurate model. If these items are labeled incompletely or incorrectly, the accuracy of the resulting model will suffer.
The Issue of Bias
Current AI and machine learning models differ from human intelligence in part because they depend entirely on their initial training data and usually do not have an automatic and recursive mechanism to absorb and process new data for course correction i.e. continuous retraining. This means that poorly balanced data introduced during training may have the potential to cause unexpected bias over time and can produce unexpected (and sometimes offensive) results. When a significant amount of bias is introduced into a system, it becomes difficult to rely on decisions made by these systems.
Good Data Annotation Leads to High-Quality Intelligent RPA
Accurate training data is the foundation of most successful data science projects. With accurate data annotation, machine learning models and AI models can make increasingly accurate decisions, and when combined with the fundamental processes of RPA, businesses can achieve truly intelligent automation.
Published at DZone with permission of Maggie Chan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments