Real-Time Data Processing Pipeline With MongoDB, Kafka, Debezium and RisingWave
This article will cover the powerful combination of MongoDB, Kafka, Debezium, and RisingWave to analyze real-time data, how they work together.
Join the DZone community and get the full member experience.
Join For FreeToday, the demand for real-time data processing and analytics is higher than ever before. The modern data ecosystem requires tools and technologies that can not only capture, store, and process vast amounts of data but also it should deliver insights in real time. This article will cover the powerful combination of MongoDB, Kafka, Debezium, and RisingWave to analyze real-time data, how they work together, and the benefits of using these open-source technologies.
Understanding Debezium and RisingWave
Before we dive into the implementation details, it’s important to understand what these two tools are and what they do.
- Debezium: is an open-source distributed platform for change data capture(CDC). CDC is a technique to track data changes written to a source database and automatically sync target databases. For example, Debezium’s MongoDB Connector can monitor for document changes in databases and collections as they occur in real-time, recording those changes as events in Kafka topics.
- RisingWave: is a distributed open-source SQL database for stream processing. Its main goal is to make it easier and cheaper to construct applications that operate in real-time. As it takes in streaming data, RisingWave performs on-the-fly computations with each new piece of data and promptly updates the outcomes. For example, RisingWave accepts data from sources like Kafka, constructs materialized views for complex data, and you can query them using SQL.
Analyzing Real-Time Data: The Pipeline
Once we have knowledge about each tool, let’s discuss how MongoDB, Kafka, Debezium, and RisingWave can work together to create an efficient real-time data analysis pipeline. These technologies are free to use and easy to integrate with each other.
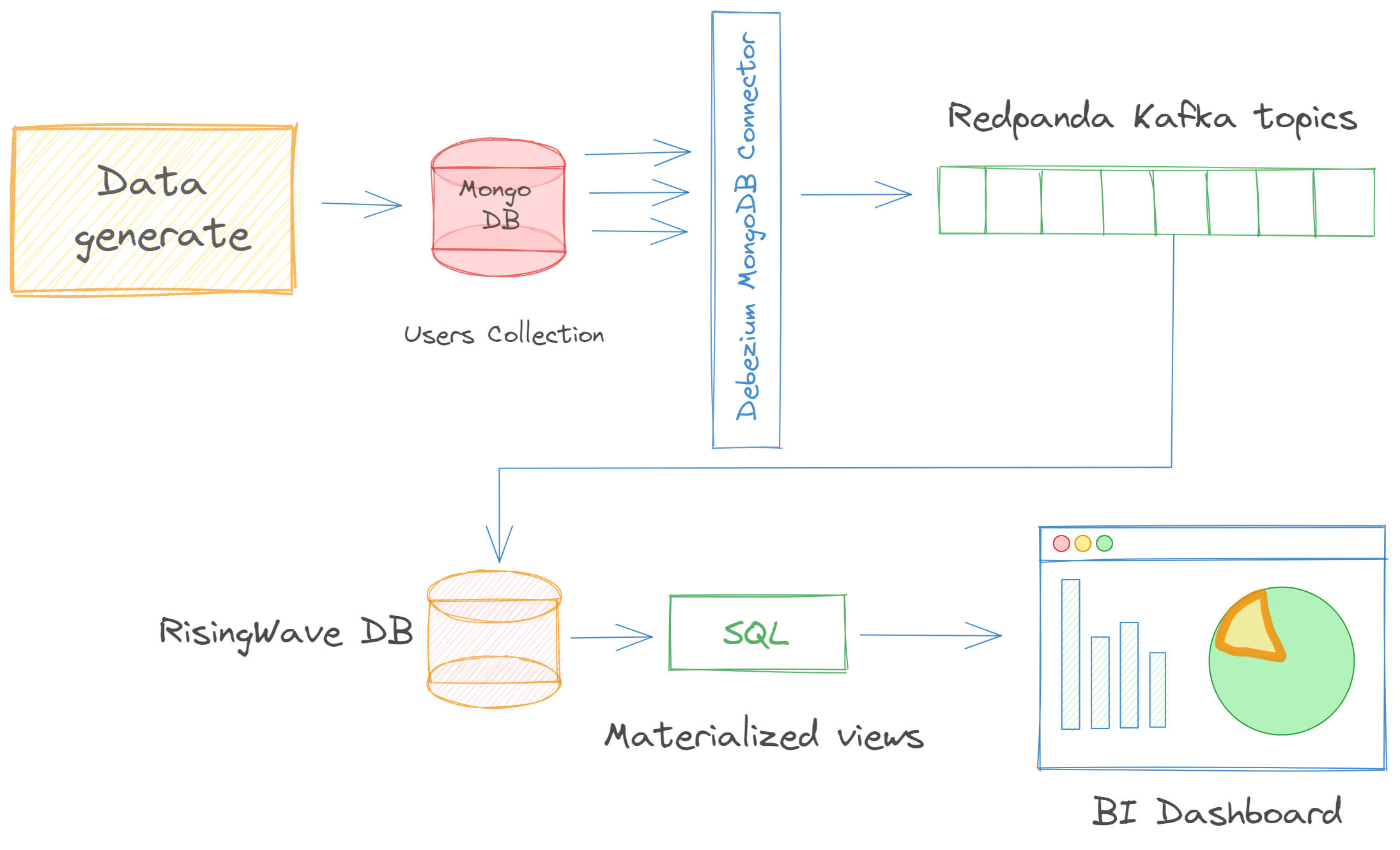
- Data Generation and Storage in MongoDB: Our data pipeline starts with the generation and storage of data in MongoDB. Given MongoDB’s flexible data model, it is possible to store data in multiple formats, making it suitable for diverse data sources.
- Data Capture with Debezium: The next step in the pipeline is the capture of changes (all of the inserts, updates, and deletes) in MongoDB using Debezium. Debezium provides a CDC connector for MongoDB that can capture row-level changes in the database. Once the changes are captured, they are sent to Kafka for processing.
- Data Streaming with Kafka: Kafka receives the data from Debezium and then takes care of streaming it to the consumers. In our case, we consume data with RisingWave.
- Data Processing with RisingWave: Finally, the streamed data is received and processed by RisingWave. RisingWave provides a high-level SQL interface for complex event processing and streaming analytics. The processed data can be passed to BI and Data analytics platforms or used for real-time decision-making, anomaly detection, predictive analytics, and much more.
This pipeline’s key strengths are its ability to handle large volumes of data, process events in real time, and produce insights with minimal latency. For example, this solution can be used for building a global hotel search platform to get real-time updates on hotel rates and availability. When rates or availability change in one of the platform’s primary databases, Debezium captures this change and streams it to Kafka, and RisingWave can do trend analysis. This ensures that users always see the most current information when they search for hotels.
How To Integrate Quickstart
This guide shows you how to configure technically the MongoDB Debezium Connector to send data from MongoDB to Kafka topics and ingest data into RisingWave.
After completing this guide, you should understand how to use these tools to create a real-time data processing pipeline and create a data source and materialized view in RisingWave to analyze data with SQL queries.
To complete the steps in this guide, you must download/clone and work on an existing sample project on GitHub. The project uses Docker for convenience and consistency. It provides a containerized development environment that includes the services you need to build the sample data pipeline.
Before You Begin
To run the project in your local environment, you need the following.
- Git
- Ensure you have Docker installed in your environment.
- Ensure that the PostgreSQL interactive terminal, psql, is installed in your environment. For detailed instructions, see Download PostgreSQL.
Start the Project
The docker-compose file starts the following services in Docker containers:
- RisingWave Database.
- MongoDB, configured as a replica set.
- Debezium.
- Python app to generate random data for MongoDB.
- Redpanda with the MongoDB Debezium Connector installed. We use Redpanda as a Kafka broker.
- Kafka Connect UI to manage and monitor our connectors.
To start the project, simply run the following command from the tutorial directory:
docker compose up
When you start the project, Docker downloads any images it needs to run. You can see the full list of services in docker-compose.yaml file.
Data Flow
App.py generates random user data (name, address, and email) and inserts them into MongoDB users collection. Because we configured the Debezium MongoDB connector to point to the MongoDB database and the collection we want to monitor, it captures data in real time and sinks them to Redpanda into a Kafka topic called dbserver1.random_data.users. Next steps, we consume Kafka events and create a materialized view using RisingWave.
Create a Data Source
To consume the Kafka topic with RisingWave, we first need to set up a data source. In the demo project, Kafka should be defined as the data source. Open a new terminal window and run to connect to RisingWave:
psql -h localhost -p 4566 -d dev -U root
As RisingWave is a database, you can directly create a table for the Kafka topic:
CREATE TABLE users (_id JSONB PRIMARY KEY, payload JSONB) WITH (
connector = 'kafka',
kafka.topic = 'dbserver1.random_data.users',
kafka.brokers = 'message_queue:29092',
kafka.scan.startup.mode = 'earliest'
) ROW FORMAT DEBEZIUM_MONGO_JSON;
Normalize Data With Materialized Views
To normalize user’s data, we create a materialized view in RisingWave:
CREATE MATERIALIZED VIEW normalized_users AS
SELECT
payload ->> 'name' as name,
payload ->> 'email' as email,
payload ->> 'address' as address
FROM
users;
The main benefit of materialized views is that they save the computation needed to perform complex joins, aggregations, or calculations. Instead of running these operations each time data is queried, the results are calculated in advance and stored.
Query Data
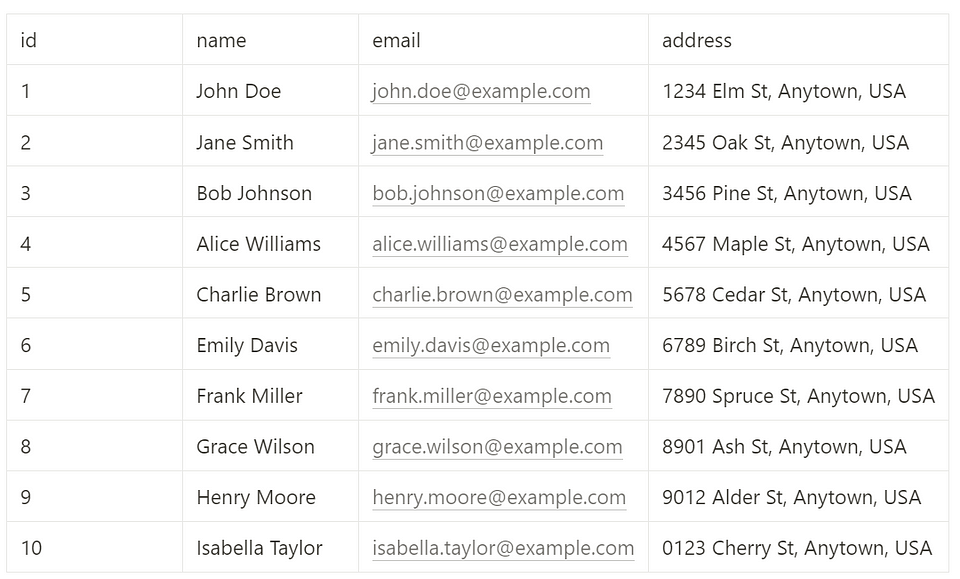
Use the SELECT command to query data in the materialized view. Let's see the latest results of the normalized_users materialized view:
SELECT
*
FROM
normalized_users
LIMIT
10;
In response to your query, a possible result set (with random data) might look like:
Summary
This is a basic setup for using MongoDB, Kafka, Debezium, and RisingWave for a real-time data processing pipeline. The setup can be adjusted based on your specific needs, such as adding more Kafka topics, tracking changes in multiple MongoDB collections, implementing more complex data processing logic, or combining multiple streams in RisingWave.
Related Resources
Recommended Content
Published at DZone with permission of Bobur Umurzokov. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments