Implementing MongoDB to Elastic Search 7.X Data Pipeline
In this article, we will see how to implement a data pipeline from an application to Mongo DB database and from there into an Elastic Search.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will see how to implement a data pipeline from an application to Mongo DB database and from there into an Elastic Search keeping the same document ID using Kafka connect in a Microservice Architecture. In recent days and years, all the microservices architectures are asynchronous in nature and are very loosely coupled. At the same time, the prime approach to have minimum code (minimum maintenance and cost), no batch systems (real-time data), and promising performance without data loss fear. Keeping all the features in mind Kafka and Kafka connect is the best solution so far to integrate different sources and sinks in one architecture to have very robust and reliable results.
We will Depp drive and implement such a solution using Debezium Kafka connect to achieve a very robust pipeline of data from one application into Mongo and then into Elastic cluster.
We are using here Debezium Kafka and Kafka connect, MongoDB 4.0.4, Elastic Search 7.7.0.
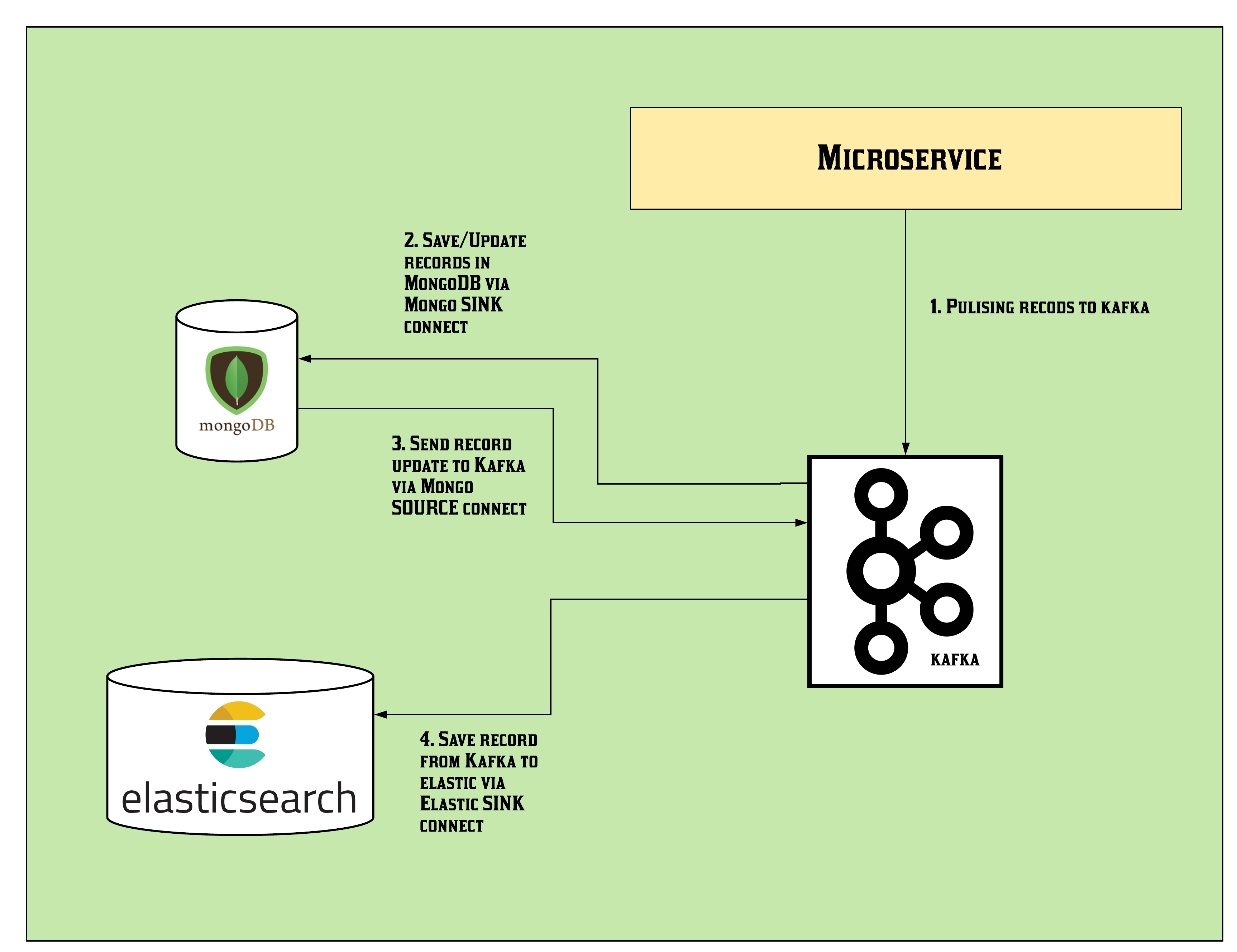
The step by step solution of the use case is given below,
1. Run Zookeeper and Kafka
docker run -d --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper:0.9
docker run -d --name kafka -p 9092:9092 --link zookeeper:zookeeper debezium/kafka:0.9
2. Run Elastic Search and Mongo DB (With Replication)
docker run -d --name elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.7.0
To Use Mongo 4.X for data pipeline, first we need to implement replica features in Mongo. Step by step solution for the same is given below,
sudo su (For windows Run as Admin)
docker run --name mongodb -v /home/data/db:/data/db -p 27018:27018 -d mongo:4.0.4 --replSet replica0
docker exec -it mongodb bash
mongo
> rs.initiate({_id: "replica0", members:[{_id: 0, host: "172.17.0.5:27017"}]})

replica0:SECONDARY> use admin
switched to db admin
replica0:PRIMARY> db.createUser({user: "abc",pwd: "abc",roles: ["dbOwner"]})
Successfully added user: { "user" : " abc ", "roles" : [ "dbOwner" ] }
replica0:PRIMARY> use mediastream
switched to db mediastream
Now, any operation under this mediastream database will be qualified for the CDC approach. The topic name will be – “mongodb.mediastream.<collection-name>”. Also, this will be the index name for Elastic Search.
3. Run an “Enriched Kafka Connect” Which Will Integrate the Microservice Application To MongoDB and Then MongoDB With Elastic Search Keeping the Document ID the Same.
Here I am using an enriched Kafka Connect image from Debezium which is capable enough to solve the statement.
docker run -d --name connect -p 8083:8083 -e GROUP_ID=1 -e CONFIG_STORAGE_TOPIC=my_connect_configs -e OFFSET_STORAGE_TOPIC=my_connect_offsets -e STATUS_STORAGE_TOPIC=my_connect_statuses --link zookeeper:zookeeper --link elastic:elastic --link mongodb:mongodb --link kafka:kafka swarnavac/connect:1.0
4. Implementing Source and Sink Connectors.
Once all these components are ready, we need to connect these by Kafka Connect Rest APIs one by one. First Create a topic with the collection name in Kafka,
[kafka@2c0cf1ca7b0b ~]$ ./bin/kafka-topics.sh --create --zookeeper 172.17.0.2:2181 --replication-factor 1 --partitions 1 --topic test
The first one is Mongo Sink Connector which will sink data into Mongo DB from Microservices via Kafka,
POST: http://<HostIP>:8083/connectors/
xxxxxxxxxx
{
"name": "mongo-sink",
"config": {
"name": "mongo-sink",
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"tasks.max": "1",
"topics": "test",
"connection.uri": "mongodb://abc:abc@172.17.0.5:27017",
"database": "mediastream",
"collection": "test",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInValueStrategy",
"writemodel.strategy": "com.mongodb.kafka.connect.sink.writemodel.strategy.UpdateOneTimestampsStrategy"
}
}
Here, mongodb://abc:abc@172.17.0.5:27017 is the connection string, and abc:abc is the username and password for your case.
Also, 172.17.0.5 is the host IP for Mongo DB. This might change in your case. The second one is the Mongo Source connector which will publish data into Kafka from Mongo,
POST: HTTP://<HostIP>:8083/connectors/
xxxxxxxxxx
{
"name": "mongo-source",
"config": {
"name": "mongo-source",
"connector.class": "io.debezium.connector.mongodb.MongoDbConnector",
"mongodb.name": "mongodb",
"mongodb.hosts": "replica0/172.17.0.5:27017",
"mongodb.user": "abc",
"mongodb.password": "abc",
"tasks.max": "1",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.mediastream",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.connector.mongodb.transforms.ExtractNewDocumentState"
}
}
The last one is the Elastic Sink which will update the data from Kafka into Elastic Search.
POST: http://<HostIP>:8083/connectors/
xxxxxxxxxx
{
"name": "elastic-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "mongodb.mediastream.test",
"connection.url": "http://elastic:9200",
"transforms": "unwrap,key",
"transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope",
"transforms.key.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.key.field": "id",
"type.name": "_doc",
"key.ignore": "false"
}
}
We can see all the created connectors by,
GET http://<HostIP>:8083/connectors/
[
"mongo-sink",
"elastic-sink",
"mongo-source"
]
We can also see the newly created index in Elastic Search,
http://<HostIP>:9200/mongodb.mediastream.test/
xxxxxxxxxx
{"mongodb.mediastream.test":{"aliases":{},"mappings":{},"settings":{"index":{"creation_date":"1604676478948","number_of_shards":"1","number_of_replicas":"1","uuid":"TgWV0PaYSBe1P3IGrl0eaw","version":{"created":"7070099"},"provided_name":"mongodb.mediastream.test"}}}}
5. Testing the Implementation.
Creating a result in Mongo in the test collection,

Created same in Elastic,
http://<HostIP>:9200/mongodb.mediastream.test/_search?pretty=true

Updating the same result in Mongo,

Also updated in Elastic,

That's All! Similarly, if you publish a record in Kafka with the topic “test” (This should be from Microservice) it will go via MongoSink -> MongoSource -> ElasticSink.
Opinions expressed by DZone contributors are their own.
Comments