Prometheus Monitoring With Grafana
How you construct your Prometheus monitoring dashboard involves trial and error. Grafana makes this exploration very easy and Prometheus has good built-in functionality.
Join the DZone community and get the full member experience.
Join For Freethe combination of prometheus and grafana is becoming a more and more common monitoring stack used by devops teams for storing and visualizing time series data. prometheus acts as the storage backend and grafana as the interface for analysis and visualization.
prometheus collects metrics from monitored targets by scraping metrics from http endpoints on these targets. but what about monitoring prometheus itself?
like any server running processes on a host machine, there are specific metrics that need to be monitored such as used memory and storage as well as general ones reporting on the status of the service. conveniently, prometheus exposes a wide variety of metrics that can be easily monitored. by adding grafana as a visualization layer, we can easily set up a monitoring stack for our monitoring stack.
let’s take a closer look.
installing prometheus and grafana
for this article, i’m using a dockerized deployment of prometheus and grafana that sets up prometheus , grafana , cadvisor , nodeexporter , and alerting with alertmanager .
the default configuration used in this image already defines prometheus as a job, with a scraping interval of 15 seconds, so the server is set to monitor itself.
- job_name: 'prometheus'
scrape_interval: 10s
static_configs:
- targets: ['localhost:9090']to install this stack, use these commands:
git clone https://github.com/stefanprodan/dockprom
cd dockprom
docker-compose up -dopen up grafana at http://<serverip>:3000 and use admin and changeme as the password to access grafana.
defining the prometheus datasource
our next step is to define prometheus as the data source for your metrics. this is easily done by clicking creating your first datasource .
the configuration for adding prometheus in grafana is as follows:
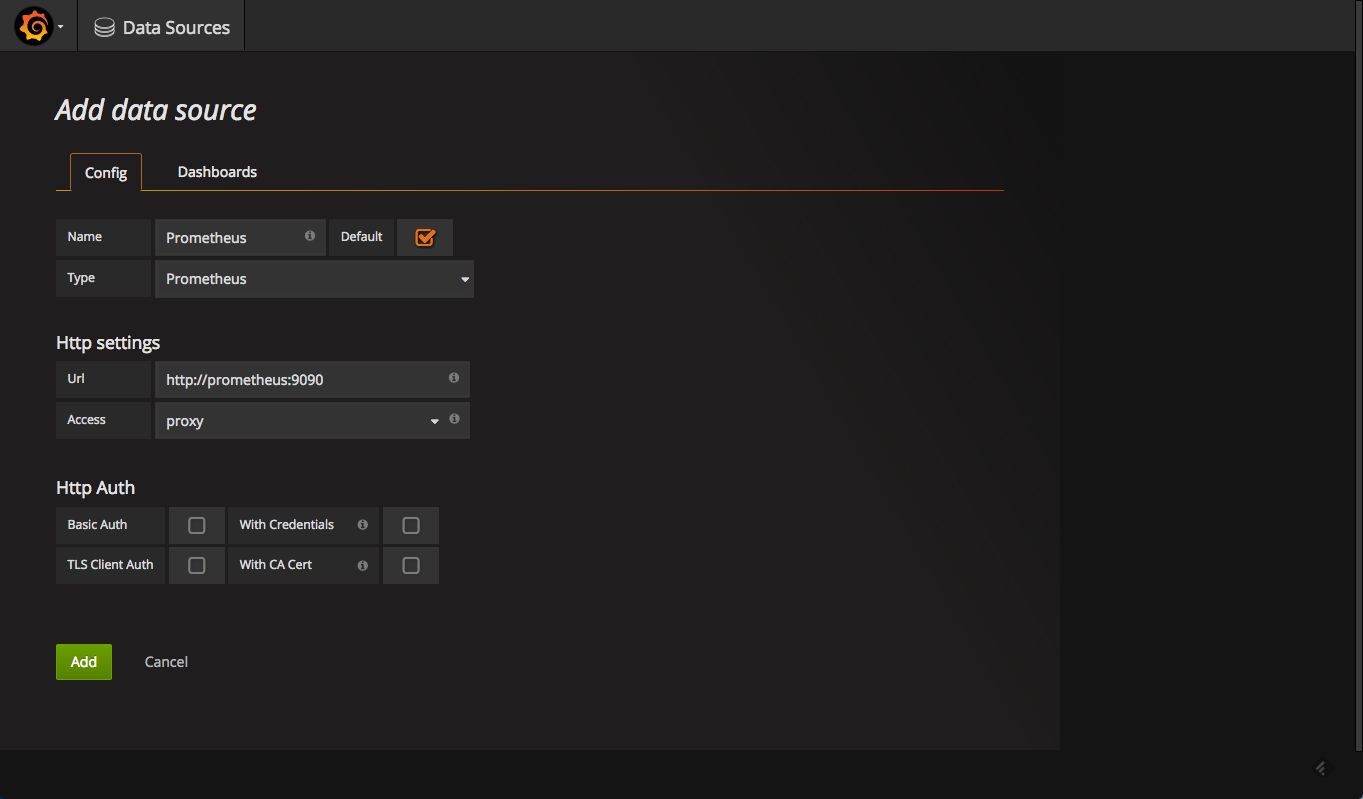
once added, test and save the new data source.
what to monitor
now that we have prometheus and grafana set up, we can begin to set up monitoring.
prometheus ships a number of useful metrics that can be monitored. for example, since prometheus stores all chunks and series in memory, we can build a panel based on the
prometheus_local_storage_memory_chunks
and
prometheus_local_storage_memory_series
metrics.
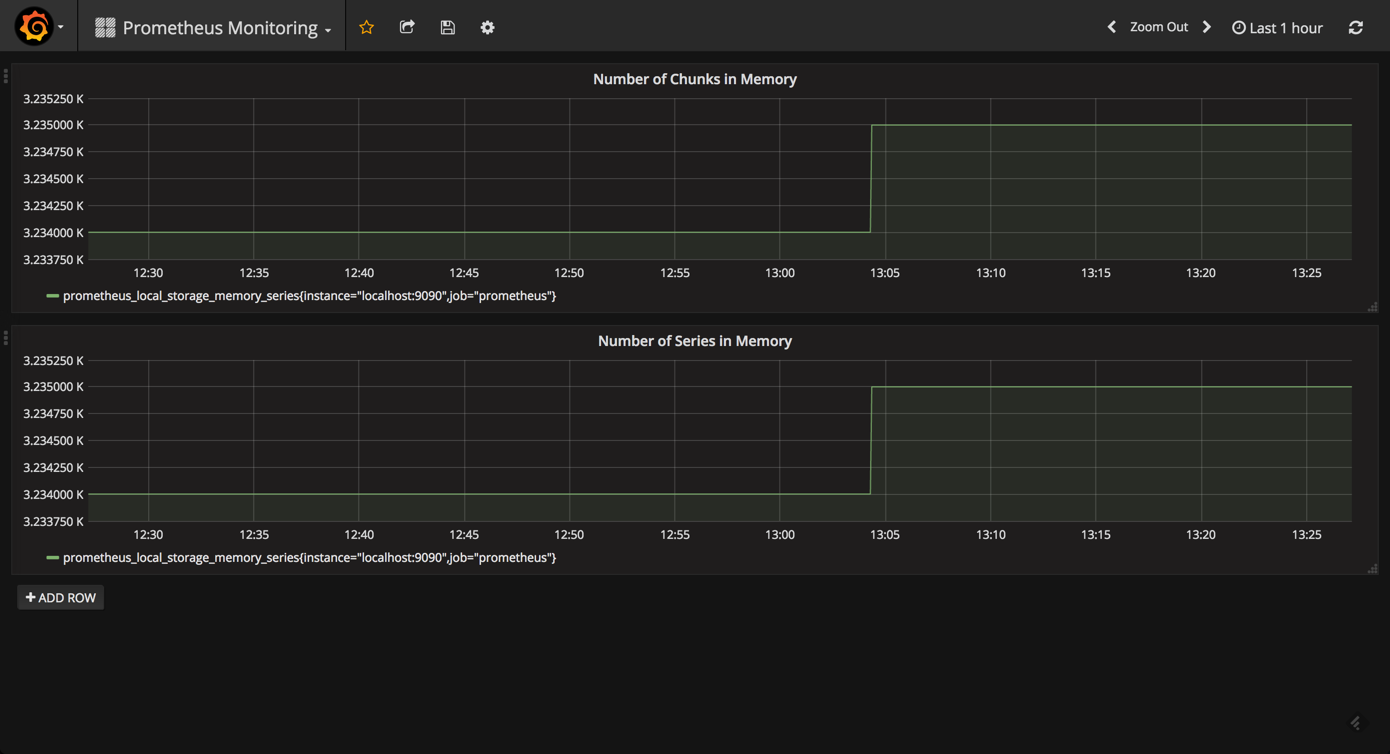
based on your ram, you will want to monitor these panels for any specific thresholds passed. you can fine-tune the amount of ram using the
storage.local.memory-chunks
configuration directive, while
prometheus recommends
that you have at least three times more ram available than needed by the memory chunks alone.
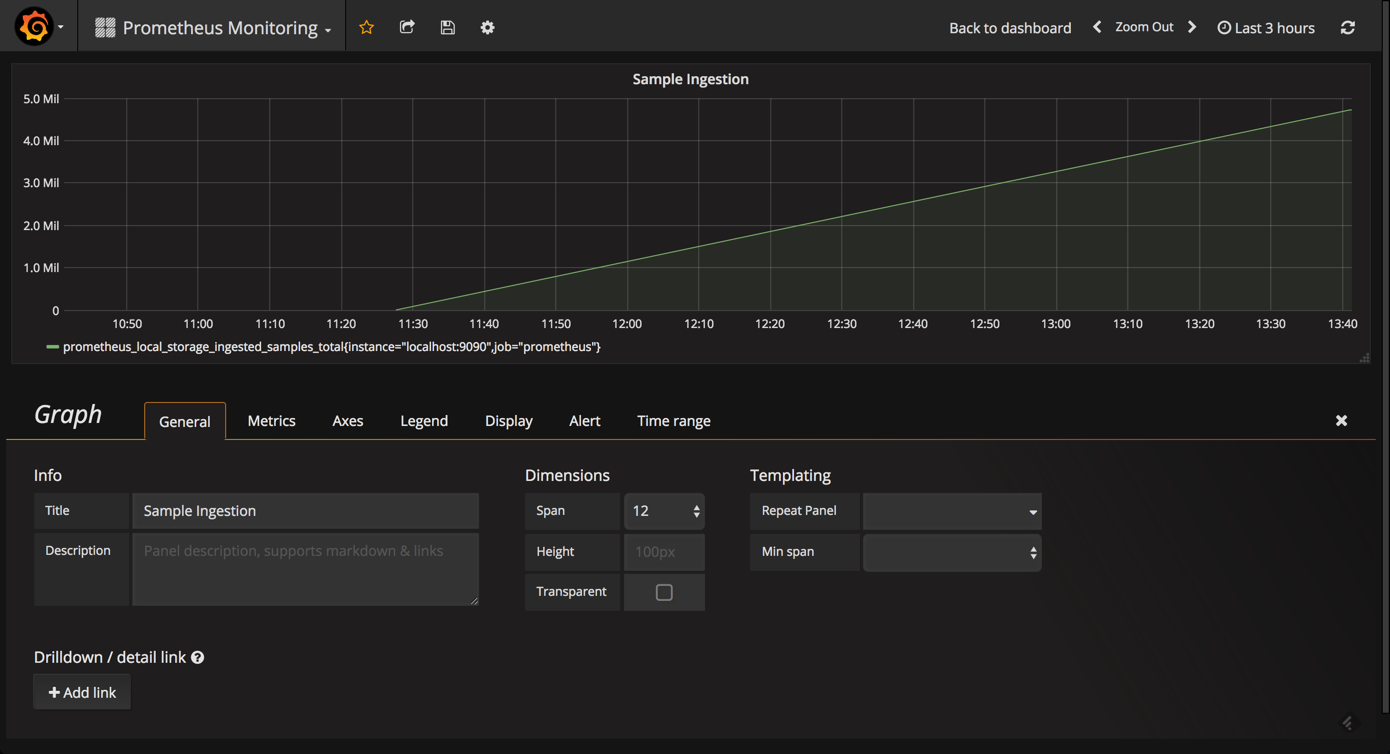
to get an overview of how well prometheus is performing, we can measure the ingestion rate for the samples using the
prometheus_local_storage_ingested_samples_total
metric. what you need to monitor is whether the rate displayed aligns with a number of metrics you know you are ingesting.
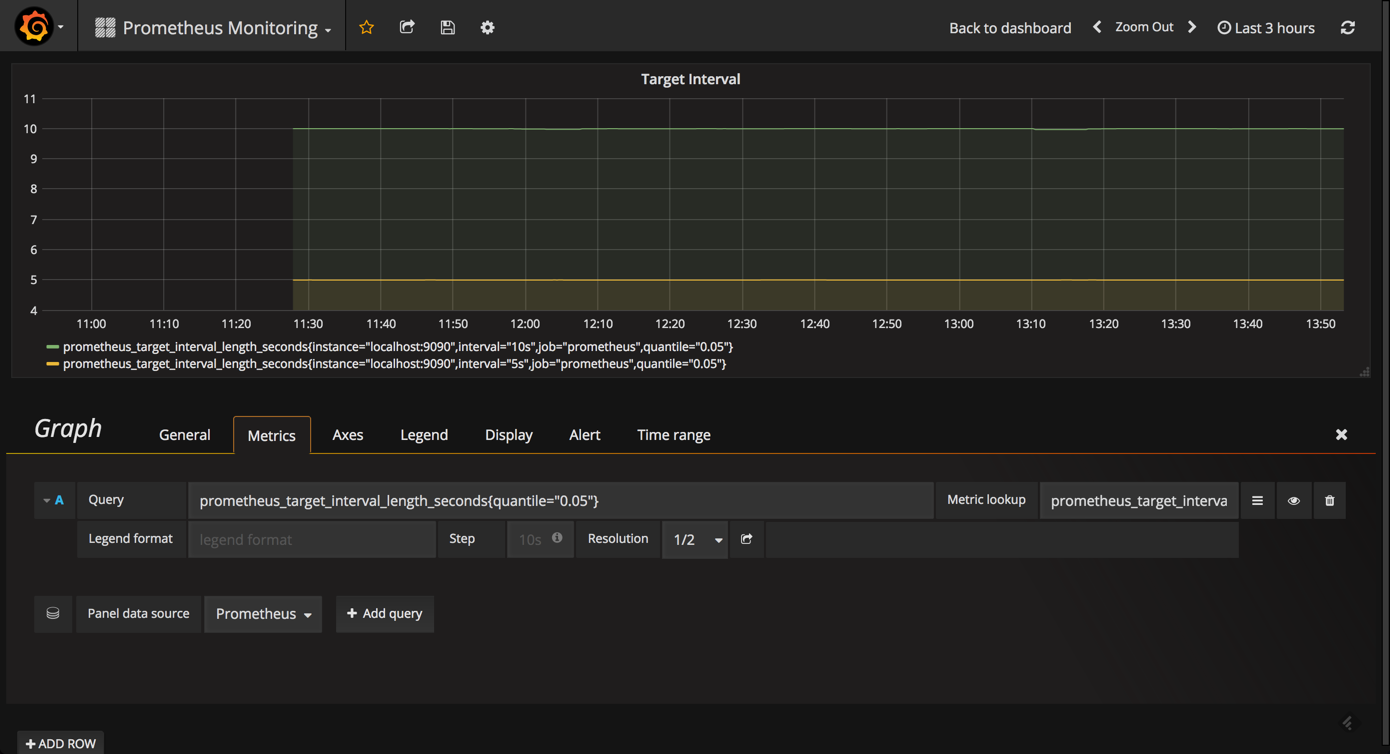
likewise, it can be useful to monitor the actual amount of time between target scrapes that you have configured for prometheus using the
prometheus_target_interval_length_seconds
metric. this will help you to identify latency issues whenever a sudden rise in latency is something that you will want to explore.
another useful metric to query and visualize is the
prometheus_local_storage_chunk_ops_total
metric that reports the per-second rate of all storage chunk operations taking place in prometheus.
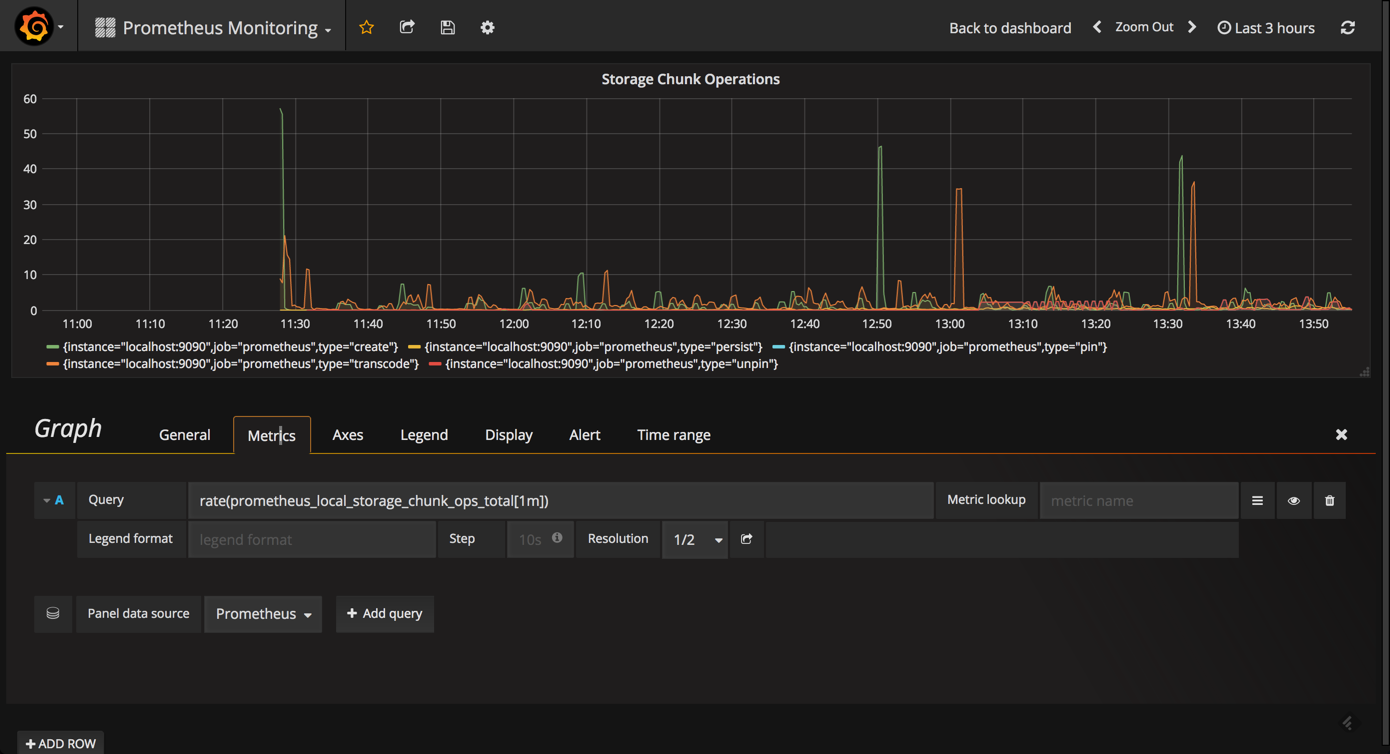
using the prometheus stats dashboard
grafana comes with a built-in official dashboard for prometheus called prometheus stats that was developed together with the prometheus team. after you set up prometheus as the datasource, simply select the dashboards tab and import the listed dashboard.
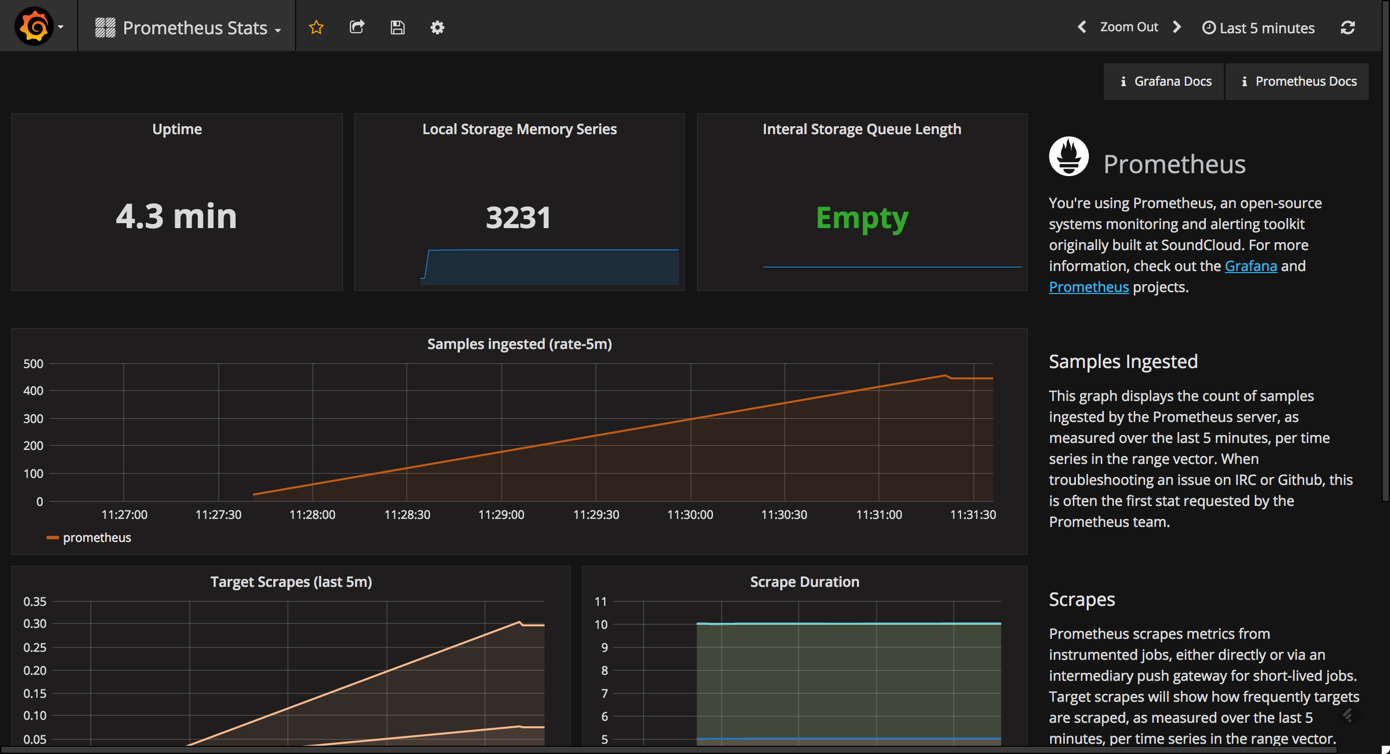
as you can see, this dashboard contains the following visualizations (some are similar to the ones described above):
- uptime : the total amount of time since your prometheus server was started.
- local storage memory series : the current number of series held in memory.
- internal storage queue length : ideally, this queue length should be “empty” (0) or a low number.
- sample ingested : displays the samples ingested by prometheus.
- target scrapes : displays the frequency that the target — prometheus, in this case — is scraped.
a prometheus benchmark dashboard
while designed for benchmarking prometheus servers, the prometheus benchmark dashboard can be used to get a sense of the additional metrics that should be monitored.
to install and use this dashboard, simply go to dashboards > import and paste the url for the dashboard.
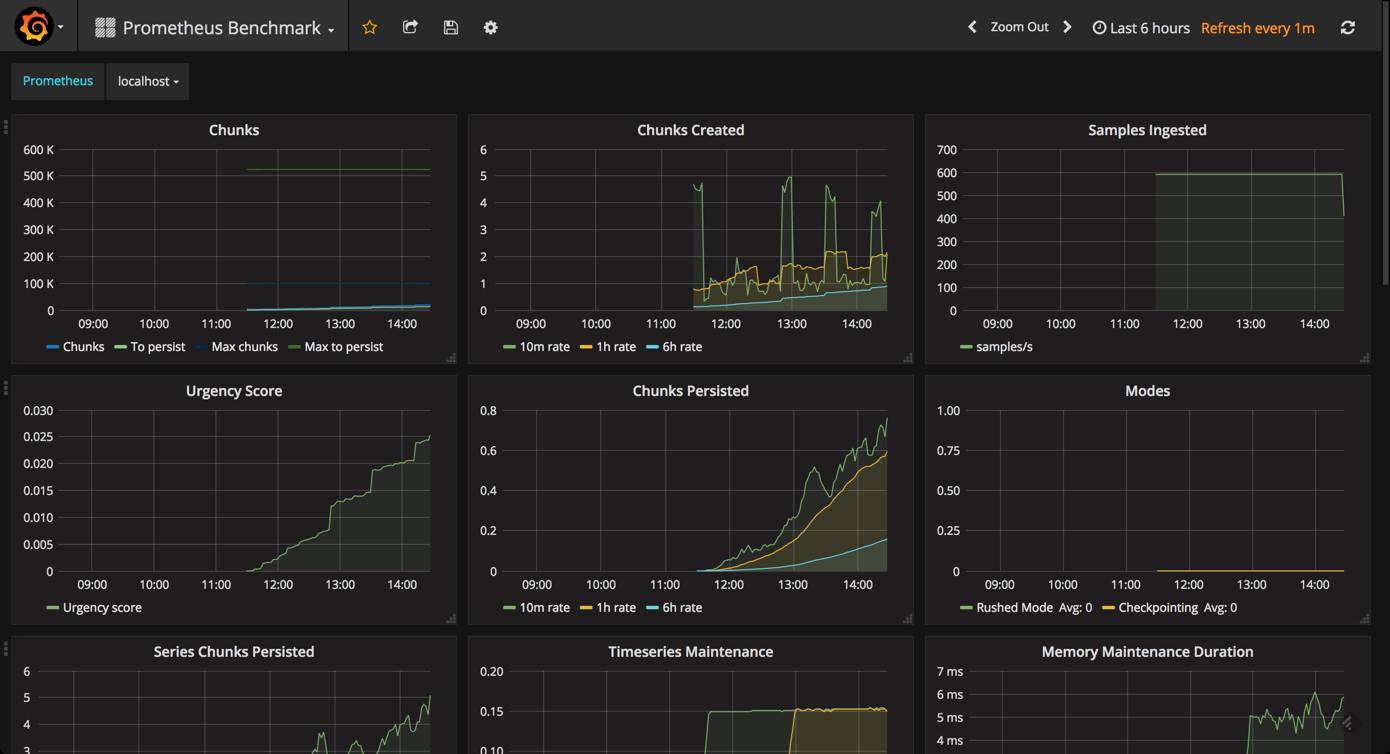
while this is probably overkill for the day-to-day monitoring of your instance, this advanced dashboard includes some useful panels that are not displayed in the prometheus stats dashboard.
for example, the memory graph gives you an idea of the memory consumed by prometheus (same goes for the cpu graph).
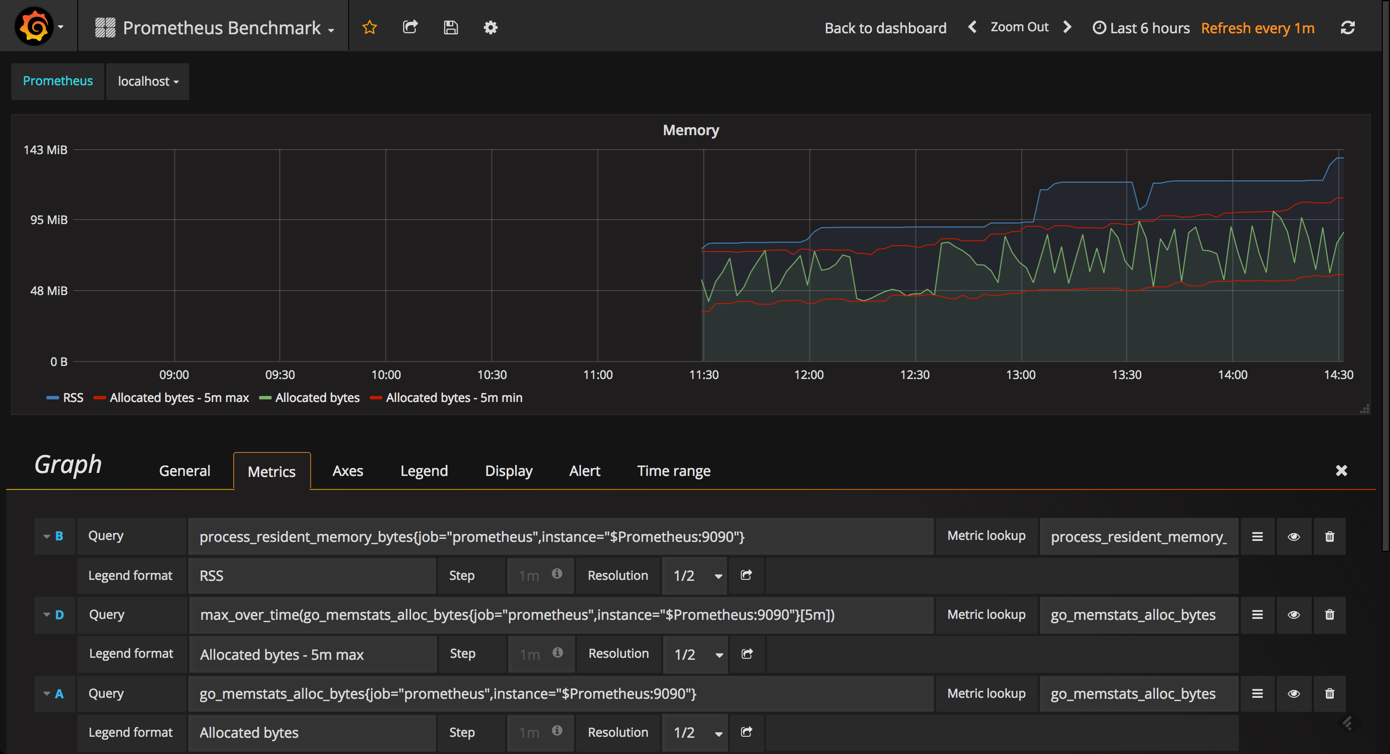
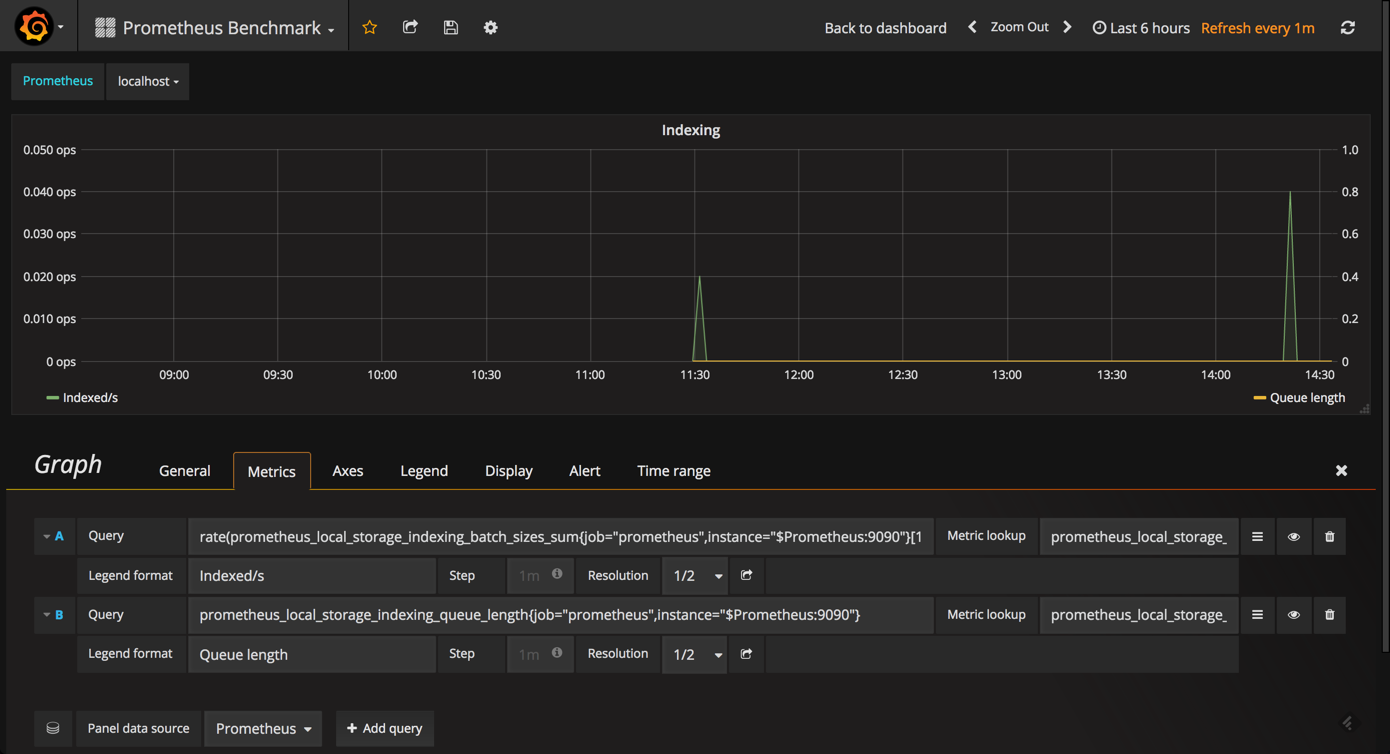
the indexing graph gives you a good picture of the indexing rates for your prometheus instance.
endnotes
you can slice and dice the various metrics that prometheus self-reports about itself any way you want. prometheus exports a long list of metrics that can be seen by browsing to http://<serverip>:9090/metrics . you can experiment with the various queries in the graph editor at http://<serverip>:9090/graph .
so, how you construct your prometheus monitoring dashboard will ultimately involve quite a lot of trial and error. the good news is that the combination with grafana makes this exploration extremely easy, and prometheus has some good built-in functionality to help you along the way.
Published at DZone with permission of Daniel Berman, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments