Project Loom And Kotlin: Some Experiments
This article will dive into the performance of virtual threading functionality with Project Loom and Kotlin using guide charts and code for readers to follow.
Join the DZone community and get the full member experience.
Join For FreeThe publishing of Java 19 in September 2022 heralded the first public release of the much-awaited Project Loom into the JVM (Java Virtual Machine) ecosystem. A brief description for those who are unaware: Project Loom is an endeavor year in the making by the developers of the Java programming language to enable the use of virtual threads within Java code. Virtual threads are named as such because, although they possess the appearance and behavior of what developers traditionally regard as threads, they are not actual OS (operating system) threads and instead are aggregated together and executed on top of such OS threads.
The primary benefit of this is that OS threads are “heavy” and bound to a relatively-small limit before their memory requirements overwhelm the operating system, whereas virtual threads are “lightweight” and can be used in much higher numbers. While the functionality of Project Loom is still in the preview phase in the Java 19 release—and “full” functionality is not forthcoming until at least the release of Java 21 in 2023 (or even further in the future)—excitement for Project Loom is quite high, and there is already movement underway in major Java ecosystems to accommodate virtual threads to their utmost potential.
Beginning To Weave
Naturally, the first question one would have is how virtual threads compare to traditional threads in the JVM ecosystem. For starters, virtual threads offer improved scalability: as mentioned above, launching a large amount of traditional threads can cause a program to crash due to running out of memory, whereas this limit does not exist (at least at such a level) for virtual threads. In addition, virtual threads provide a performance advantage compared to traditional threads, during “high-traffic” operations. To demonstrate, I created the following JMH (Java Microbenchmark Harness) tests:
import org.openjdk.jmh.annotations.Benchmark
import org.openjdk.jmh.annotations.BenchmarkMode
import org.openjdk.jmh.annotations.Fork
import org.openjdk.jmh.annotations.Mode
import org.openjdk.jmh.annotations.OutputTimeUnit
import org.openjdk.jmh.annotations.Param
import org.openjdk.jmh.annotations.Scope
import org.openjdk.jmh.annotations.State
import org.openjdk.jmh.infra.Blackhole
import java.util.concurrent.*
import kotlin.concurrent.thread
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(1)
open class ThreadVsLoom {
@Param(value = ["10", "100", "1000", "10000"])
private var repeat: Int = 0
// Simulating work in increasingly-heavier loads
@Param(value = ["0", "10", "100"])
private var delay: Long = 0
@Benchmark
fun traditionalThreads(blackhole: Blackhole) {
(0 until repeat).map { i ->
thread {
Thread.sleep(delay)
blackhole.consume(i)
}
}.forEach { it.join() }
}
@Benchmark
fun virtualThreads(blackhole: Blackhole) {
(0 until repeat).map { i ->
Thread.startVirtualThread {
Thread.sleep(delay)
blackhole.consume(i)
}
}.forEach { it.join() }
}
}When this Maven-based Kotlin project—Gradle 7.6, which supports Java 19, has not been released as of the writing of this article—was executed on my computer (Windows 10 with an AMD 2.30Ghz CPU and 16GB of RAM), the following results were produced:
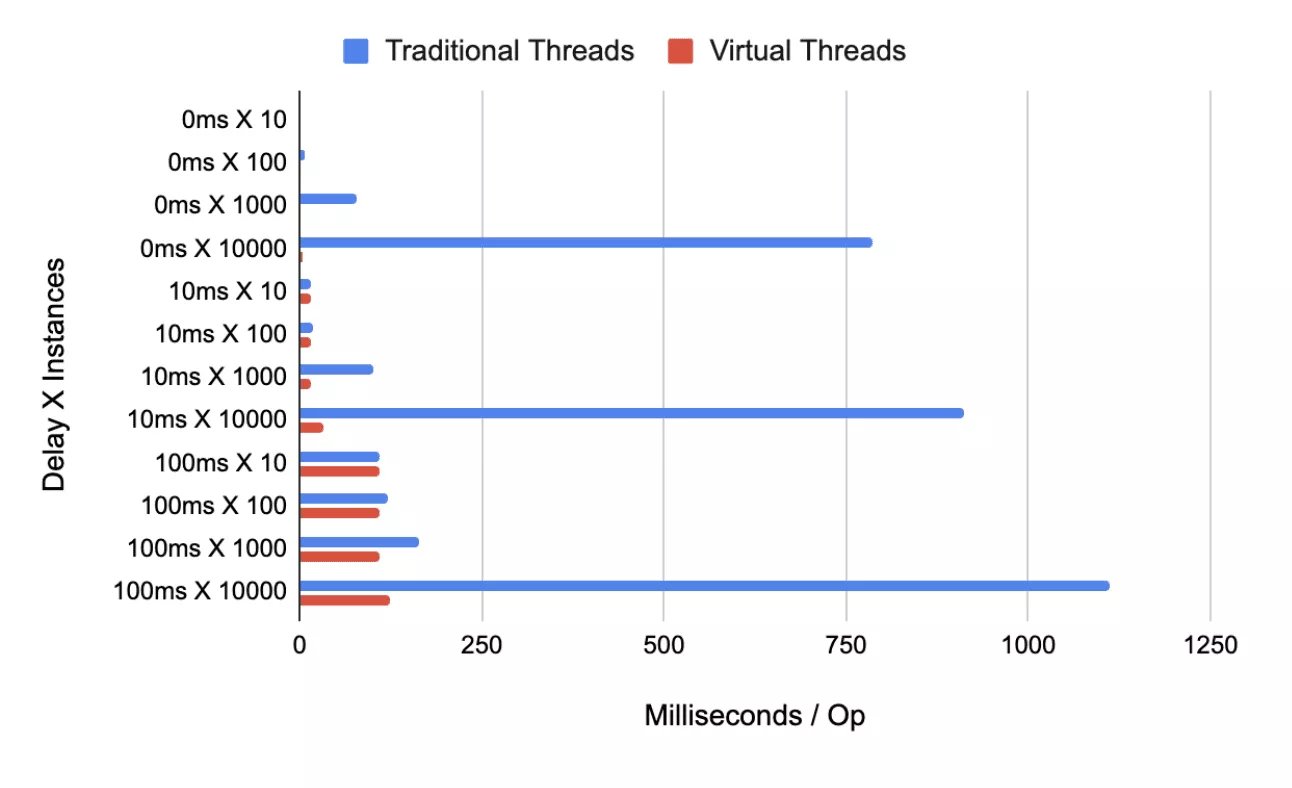
As the test results show, the test operation took much longer for traditional threads to execute compared to virtual threads. This is because traditional threads are “bound” in a one-to-one relationship with OS threads, so context switching between traditional threads is a much more expensive operation compared to context switching between virtual threads.
Kotlin Coroutines
Since its version 1.0 release in the fall of 2018, the Kotlin coroutines library has established itself as an alternative to both the traditional multithreading architecture of Java and the reactive programming paradigm (so much so that the developers of the Spring ecosystem made coroutines a first-class citizen in the reactive WebFlux library).
With the gradual introduction of Project Loom, the availability of a new multithreading mechanism that is more performant than the traditional threads raises the question of whether one should replace coroutine-dependent code with code that leverages virtual threads. After all, Kotlin’s coroutines cause “function coloring” (i.e. they can only be called within a coroutine context or within a function that is prefixed by the suspend keyword)—an issue that is not present in Java’s virtual threading—and one less dependency in a project’s code base results in the task of maintaining dependencies up-to-date for project hygiene purposes being one item lighter. Much digital ink has already been spilled on this subject, and the consensus appears to be “probably not.”
For one, Kotlin’s coroutines and virtual threads are designed for different tasks, namely “concurrency” and “parallelism,” respectively. To be brief, “concurrency” is the ability to conduct multiple tasks within a given amount of time, whereas “parallelism” is the ability to conduct multiple tasks *at* the same time.
To give an example: tasks A, B, C, and D could be conducted in a concurrent manner if there exists a point in each of the tasks to “suspend” those tasks and work on a different task before returning to the suspended task(s). Those same tasks could be conducted in a parallel manner if there are enough threads to host and execute each of those tasks independently and simultaneously. Given the reduction of the resource and performance costs that virtual threads will bring for parallel programming, this difference might become irrelevant in the grand scheme of things for most developers, but Kotlin’s coroutines library also offers additional functionality beyond simply conducting concurrent work, e.g., the flow mechanism and channels.
For Science
Regardless, the availability of virtual threads in Java 19 provides the opportunity to conduct comparisons between virtual threads and Kotlin’s coroutines in performance testing similar to the tests between traditional and virtual threads described above. It’s possible to go even further, though: the presence of an implementation of ExecutorService designed for virtual threads (i.e., Executors.newVirtualThreadPerTaskExecutor()) presents an opportunity: given that one can convert an ExecutorService implementation into a dispatcher context for Kotlin’s coroutines via the extension function ExecutorService.asCoroutineDispatcher(), why not try “crossing the streams” and combine the virtual thread and coroutine functionalities together?
To test this out, it’d be necessary to ensure that the hybrid approach would still guarantee thread safety. To verify this, the hybrid approach would need to be subjected to a series of tests that mirror the approaches that the Kotlin authors recommend for maintaining thread safety:
import kotlinx.coroutines.asCoroutineDispatcher
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.newSingleThreadContext
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.sync.Mutex
import kotlinx.coroutines.sync.withLock
import kotlinx.coroutines.withContext
import java.util.concurrent.*
import java.util.concurrent.atomic.*
import kotlin.coroutines.CoroutineContext
private const val ROUNDS = 5
private const val REPETITIONS = 10000
private const val DELAY_AMT = 10L
fun main() {
runControlTest()
runPoolTest("Naive") { coroutineContext ->
var counter = 0
runBlocking(coroutineContext) {
repeat(REPETITIONS) {
launch {
delay(DELAY_AMT)
counter++
}
}
}
counter
}
runPoolTest("Atomic Integer") { coroutineContext ->
val counter = AtomicInteger(0)
runBlocking(coroutineContext) {
repeat(REPETITIONS) {
launch {
delay(DELAY_AMT)
counter.incrementAndGet()
}
}
}
counter.get()
}
runPoolTest("Confinement") { coroutineContext ->
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
runBlocking(coroutineContext) {
repeat(REPETITIONS) {
launch {
withContext(counterContext) {
counter++
}
}
}
}
counter
}
runPoolTest("Mutex") { coroutineContext ->
val mutex = Mutex()
var counter = 0
runBlocking(coroutineContext) {
repeat(REPETITIONS) {
launch {
mutex.withLock {
counter++
}
}
}
}
counter
}
}
private fun runControlTest() {
executeTest("Control") {
val counter = AtomicInteger(0)
runBlocking {
repeat(REPETITIONS) {
launch {
delay(DELAY_AMT)
counter.incrementAndGet()
}
}
}
counter.get()
}
}
private fun runPoolTest(title: String, block: (CoroutineContext) -> Int) {
Executors.newVirtualThreadPerTaskExecutor().use { threadPool ->
executeTest(title) {
block.invoke(threadPool.asCoroutineDispatcher())
}
}
}
private fun executeTest(title: String, block: () -> Int) {
println("Test: $title")
val successes = (0 until ROUNDS).sumOf { i ->
val result = block.invoke()
println("Round ${i + 1} result: $result")
if (result == REPETITIONS) 1 else 0L
}
println("Successes: $successes/$ROUNDS\n")
}Executing this test provided results that indicated that thread safety was still being maintained in the hybrid approach:
Test: Control
Round 1 result: 10000
Round 2 result: 10000
Round 3 result: 10000
Round 4 result: 10000
Round 5 result: 10000
Successes: 5/5
Test: Naive
Round 1 result: 9934
Round 2 result: 9753
Round 3 result: 9712
Round 4 result: 9128
Round 5 result: 9319
Successes: 0/5
Test: Atomic Integer
Round 1 result: 10000
Round 2 result: 10000
Round 3 result: 10000
Round 4 result: 10000
Round 5 result: 10000
Successes: 5/5
Test: Confinement
Round 1 result: 10000
Round 2 result: 10000
Round 3 result: 10000
Round 4 result: 10000
Round 5 result: 10000
Successes: 5/5
Test: Mutex
Round 1 result: 10000
Round 2 result: 10000
Round 3 result: 10000
Round 4 result: 10000
Round 5 result: 10000
Successes: 5/5Thus, it’d be possible to proceed to the performance tests:
import kotlinx.coroutines.ExecutorCoroutineDispatcher
import kotlinx.coroutines.asCoroutineDispatcher
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
import org.openjdk.jmh.annotations.Benchmark
import org.openjdk.jmh.annotations.BenchmarkMode
import org.openjdk.jmh.annotations.Fork
import org.openjdk.jmh.annotations.Level
import org.openjdk.jmh.annotations.Mode
import org.openjdk.jmh.annotations.OutputTimeUnit
import org.openjdk.jmh.annotations.Param
import org.openjdk.jmh.annotations.Scope
import org.openjdk.jmh.annotations.Setup
import org.openjdk.jmh.annotations.State
import org.openjdk.jmh.annotations.TearDown
import org.openjdk.jmh.infra.Blackhole
import java.util.concurrent.*
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(1)
open class LoomVsCoroutines {
@Param(value = ["10", "100", "1000", "10000", "100000"])
private var repeat: Int = 0
// Simulating work in increasingly-heavier loads
@Param(value = ["0", "10", "100"])
private var delay: Long = 0
private lateinit var executorService: ExecutorService
private lateinit var executorCoroutineDispatcher: ExecutorCoroutineDispatcher
@Setup(Level.Iteration)
fun setup() {
executorService = Executors.newVirtualThreadPerTaskExecutor()
executorCoroutineDispatcher = executorService.asCoroutineDispatcher()
}
@TearDown(Level.Iteration)
fun teardown() {
executorService.close()
}
@Benchmark
fun loom(blackhole: Blackhole) {
(0 until repeat).map { i ->
executorService.submit {
Thread.sleep(delay)
blackhole.consume(i)
}
}.forEach { it.get() }
}
@Benchmark
fun coroutines(blackhole: Blackhole) {
runBlocking {
(0 until repeat).map { i ->
launch {
delay(delay)
blackhole.consume(i)
}
}.forEach { it.join() }
}
}
@Benchmark
fun hybrid(blackhole: Blackhole) {
runBlocking(executorCoroutineDispatcher) {
(0 until repeat).map { i ->
launch {
delay(delay)
blackhole.consume(i)
}
}.forEach { it.join() }
}
}
}When executed on my computer, the following results were produced:
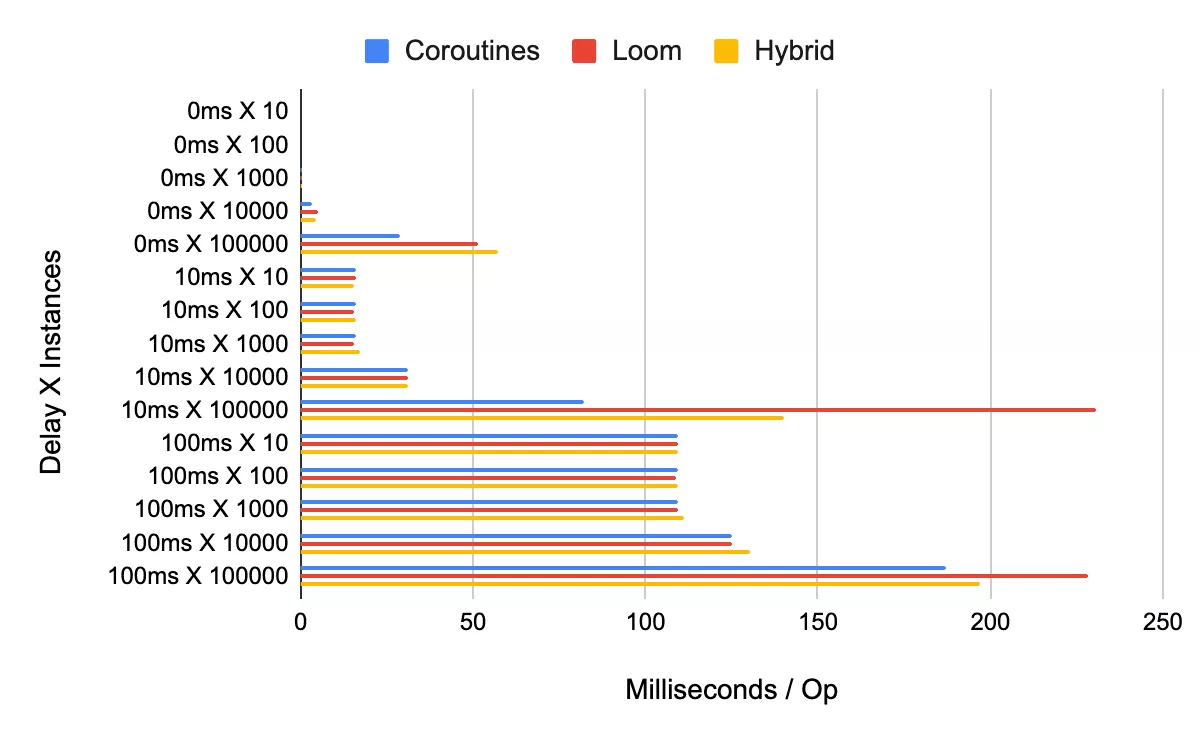
In general, performance remains similar between the three approaches until the amount of launched processes reaches six digits. After which, the virtual thread mechanism begins to perform notably slower than Kotlin’s coroutines, whereas the hybrid approach performed in between the coroutines and virtual thread approaches in the heavier tests. Re-running the “heaviest” test of 100ms of delay for 100000 processes and attaching the GC (garbage collector) profiler to the JMH tests (i.e., passing the -prof gc option into the tests) provided the following information:
Benchmark (delay) (repeat) Mode Cnt Score Error Units
LoomVsCoroutines.coroutines 100 100000 avgt 5 185.955 ± 2.496 ms/op
LoomVsCoroutines.coroutines:·gc.alloc.rate 100 100000 avgt 5 215.787 ± 3.041 MB/sec
LoomVsCoroutines.coroutines:·gc.alloc.rate.norm 100 100000 avgt 5 44184945.652 ± 580.547 B/op
LoomVsCoroutines.coroutines:·gc.churn.G1_Eden_Space 100 100000 avgt 5 215.239 ± 4.958 MB/sec
LoomVsCoroutines.coroutines:·gc.churn.G1_Eden_Space.norm 100 100000 avgt 5 44073520.476 ± 1389017.407 B/op
LoomVsCoroutines.coroutines:·gc.churn.G1_Survivor_Space 100 100000 avgt 5 0.209 ± 0.191 MB/sec
LoomVsCoroutines.coroutines:·gc.churn.G1_Survivor_Space.norm 100 100000 avgt 5 42882.682 ± 39067.969 B/op
LoomVsCoroutines.coroutines:·gc.count 100 100000 avgt 5 45.000 counts
LoomVsCoroutines.coroutines:·gc.time 100 100000 avgt 5 377.000 ms
LoomVsCoroutines.loom 100 100000 avgt 5 236.616 ± 22.316 ms/op
LoomVsCoroutines.loom:·gc.alloc.rate 100 100000 avgt 5 371.661 ± 34.181 MB/sec
LoomVsCoroutines.loom:·gc.alloc.rate.norm 100 100000 avgt 5 96711951.023 ± 127890.736 B/op
LoomVsCoroutines.loom:·gc.churn.G1_Eden_Space 100 100000 avgt 5 373.982 ± 50.011 MB/sec
LoomVsCoroutines.loom:·gc.churn.G1_Eden_Space.norm 100 100000 avgt 5 97301115.701 ± 6349254.933 B/op
LoomVsCoroutines.loom:·gc.churn.G1_Survivor_Space 100 100000 avgt 5 1.096 ± 1.248 MB/sec
LoomVsCoroutines.loom:·gc.churn.G1_Survivor_Space.norm 100 100000 avgt 5 284628.786 ± 317457.123 B/op
LoomVsCoroutines.loom:·gc.count 100 100000 avgt 5 54.000 counts
LoomVsCoroutines.loom:·gc.time 100 100000 avgt 5 822.000 ms
LoomVsCoroutines.hybrid 100 100000 avgt 5 197.307 ± 1.643 ms/op
LoomVsCoroutines.hybrid:·gc.alloc.rate 100 100000 avgt 5 516.078 ± 4.407 MB/sec
LoomVsCoroutines.hybrid:·gc.alloc.rate.norm 100 100000 avgt 5 112129742.369 ± 245613.881 B/op
LoomVsCoroutines.hybrid:·gc.churn.G1_Eden_Space 100 100000 avgt 5 518.893 ± 79.958 MB/sec
LoomVsCoroutines.hybrid:·gc.churn.G1_Eden_Space.norm 100 100000 avgt 5 112736312.220 ± 16726375.440 B/op
LoomVsCoroutines.hybrid:·gc.churn.G1_Survivor_Space 100 100000 avgt 5 6.895 ± 4.176 MB/sec
LoomVsCoroutines.hybrid:·gc.churn.G1_Survivor_Space.norm 100 100000 avgt 5 1497801.004 ± 895068.779 B/op
LoomVsCoroutines.hybrid:·gc.count 100 100000 avgt 5 68.000 counts
LoomVsCoroutines.hybrid:·gc.time 100 100000 avgt 5 690.000 msThe results here suggest that while more object churn is a factor for virtual threads compared to coroutines, there are likely other factors at work here (e.g., code for virtual thread management that could be further optimized), as the virtual thread/coroutines hybrid approach had a significantly-higher GC allocation rate than the virtual thread approach, yet its performance was significantly faster than the latter at heavier loads. Unfortunately, the JFR (Java Flight Recorder) profiler was unable to provide any insight, as the .jfr file produced for the virtual thread approach was over two hundred megabytes in size (compared to just over a megabyte each for the coroutine and hybrid approaches), although because there was such a discrepancy between the virtual thread approach’s file and the remaining two approaches’ files would indeed suggest that there are some inefficiencies in the virtual thread code that the Project Loom developers should address.
Parting Thoughts
Despite the slower performance of the virtual threading compared to Kotlin’s coroutines, it is important to remember that the Project Loom code is very new and “green” compared to the Kotlin Coroutine library. The most recent release of Java (version 19) debuted the functionality strictly as a preview feature—and it will undergo at least another Java release (or more) in preview mode before it is finally upgraded to production-ready—meaning that there is still much work left to be done, including receiving feedback from the Java community and rectifying any issues they identify. This means the performance of the virtual threading functionality is bound to improve in the future, including compared to Kotlin’s coroutines. In any case, virtual threads will provide yet another tool for developers in the JVM ecosystem, and it will be very interesting to see how this functionality will grow and evolve in the years to come.
Published at DZone with permission of Severn Everett. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments