Programmers in the Era of Large Models
Lare models have completely altered developers' processes. After reading this, you'll likely have a whole new perspective on how AIGC enhances development efficiency.
Join the DZone community and get the full member experience.
Join For FreeThe following video showcases a snippet of the Apache SeaTunnel developer's daily workflow, aided by Co-Pilot. If you haven't yet embraced tools like Co-Pilot, ChatGPT, or private large-scale models for development assistance, you might find yourself quickly outpaced by the industry over the next five years. Those skilled in leveraging AI-powered coding can accelerate their development speed tenfold compared to those without this skill. This isn't an exaggeration — after reading this, you'll likely have a whole new perspective on how AIGC enhances development efficiency.
Disrupting Traditional Junior Programmer Training With Large Models: Empowering Skills and Experience
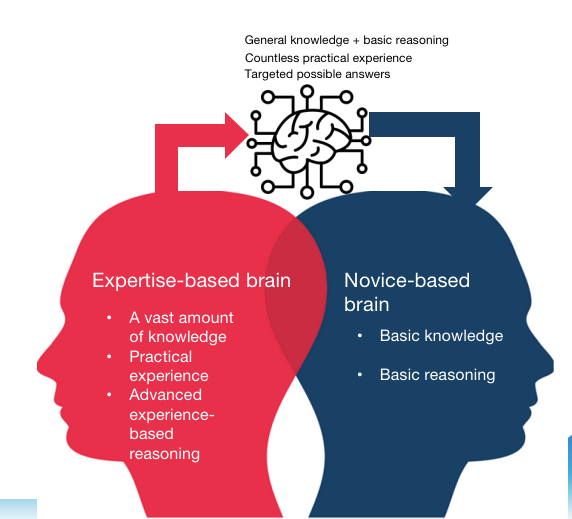
In the past, junior programmers would be given tasks by mentors, taught basic approaches, and then guided and corrected as they wrote code. They learned from experience and guidance, gradually gaining proficiency.
However, the arrival of large models has completely transformed this process. Large models possess extensive knowledge and even some rudimentary reasoning abilities. They've undergone countless practices, learning various codes and business definitions within a company. The scenarios they've encountered far exceed those faced by mentors in their time. They provide potential answers based on developers' requirements and goals.
It's akin to having an all-knowing "mentor" available at your beck and call, capable of instantly generating code for your reference and learning. After learning and adjustment, a junior programmer can submit code that surpasses their individual skill level, ready for peer review.
So, why wouldn't we utilize large models to boost our development efficiency?
How To Utilize Large Models for Assisted Programming?
Common tools currently include ChatGPT, Co-Pilot, and private large-scale models.
Different methods are applicable depending on the programming scenario:
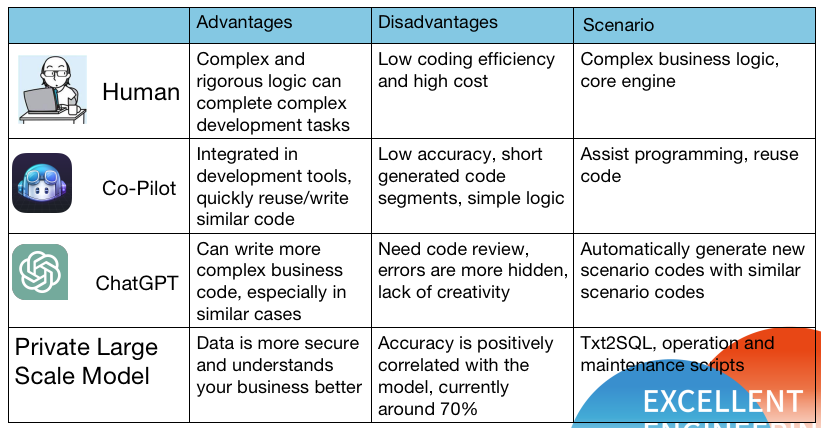
It's evident that humans are best suited for challenging and innovative architecture or new business scenario code. For reused or similar algorithms, using Co-Pilot can rapidly enhance efficiency. ChatGPT can be employed for generating code in similar scenarios with minor modifications. Private large models are suitable for scenarios where data and code security are crucial, and where the model's familiarity with your business knowledge matters — requiring fine-tuning.
One might argue that not every company can afford private large models. However, this is a misconception. You don't necessarily need to train an entirely new private large model. For most companies, optimizing (fine-tuning) an existing open-source large model for understanding your business context is sufficient. This process requires only 1-2 graphics cards (e.g., 3090/4090) and a few hours for configuration.
Using private large models can directly facilitate the following:
- Easy access to desired software features.
- Efficient navigation of complex user manuals and rules.
- Assisted programming, Txt2SQL, enhancing data programmer efficiency.
Leveraging private large models for programming assistance is closer than you think. If you're still skeptical about the era of AIGC-driven automation in programming, consider the example below on how an open-source project utilizes AIGC to enhance development efficiency.
Example of Large Model-Driven Automated Programming: Apache SeaTunnel
The vision of Apache SeaTunnel is to "Connect Everything, Sync as Fast as Lightning." This ambitious goal aims to connect all data sources on the market, including databases, SaaS, middleware, and BinLogs, achieving optimal synchronization. This is an impossible feat for any single company, and even humans struggle to accomplish it amidst thousands of SaaS software options and ever-changing interfaces. So, how did the core team behind Apache SeaTunnel design such software in the AI era? The overall structure is depicted in the following diagram:
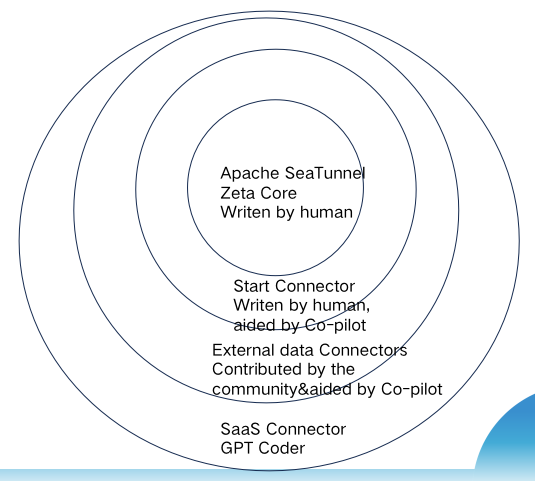
Firstly, the core computational engine is purpose-built for synchronization. Unlike Flink or Spark, it focuses on efficient memory, CPU, and bandwidth utilization, and ensures data consistency — aspects that lack existing benchmarks. Consequently, most of the code isn't borrowed but developed directly by core engineers, with continuous input and refinements from experts worldwide to keep pace with cutting-edge technology.
Secondly, the core database connectors, such as the Iceberg Connector, are complex implementations that prioritize both accuracy and high data transmission efficiency. While these still rely primarily on human expertise, they can leverage existing codes and cloud-based practices, with Co-Pilot as a supportive tool. Large models assist by complementing conventional algorithms and reusing code snippets, as demonstrated in the introductory video.
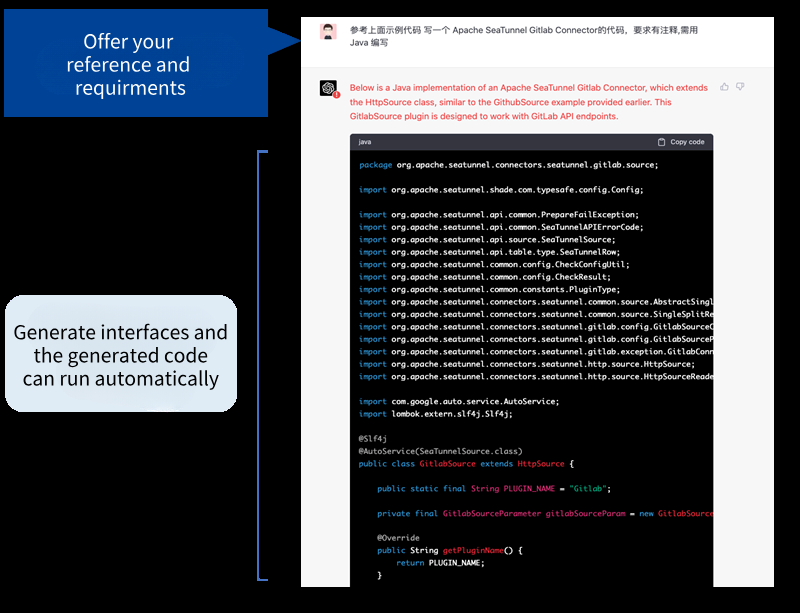
In the face of a vast sea of SaaS interfaces — over 5000 in the MarTech sector alone — manual integration is unfeasible. The SeaTunnel core team devised a strategy: abstracting over a dozen interfaces that humans had previously coded, collaborating with ChatGPT to turn them into two interfaces capable of producing elegant code. ChatGPT can comprehend SaaS interface documentation and directly generate relevant code snippets. Within SeaTunnel, this feature is known as "AI Compatibility," facilitating collaboration between AI and humans. It's a kind of "reconciliation" between programmers and AI, ensuring that each contributes where the other excels.
This feature was released in Apache SeaTunnel 2.3.1. However, as an evolving open-source project, it still has room for improvement. Given the open nature of the code, more enthusiasts are likely to fine-tune and automate this feature. For instance, I've heard of a developer planning to create a GPT Coder that monitors SaaS issues on GitHub, uses ChatGPT to generate code, and submits pull requests automatically — taking human-bot collaboration to the extreme.
Challenges of Large Model-Driven Automated Programming
While ChatGPT, Co-Pilot, and similar tools enhance programming, they're not invincible. There are several challenges to consider when generating code with large models:
- Accuracy concerns.
- Inability to conduct code reviews.
- Limited capability for automated testing.
- No accountability.
Large models can still make mistakes, and this will likely remain the norm for some time — even ChatGPT4 may produce code with 90% accuracy. Hence, it's crucial to simplify the process of code generation, as generating incorrect code is a potential pitfall. After rapid code generation by large models, human code review may struggle to keep up, as machines cannot verify if the final code correctly implements the business logic. Attempting code review using large models reveals a plethora of seemingly important but ultimately trivial improvements, obscuring the assessment of logic correctness.
Moreover, automated testing and test case generation are still challenging aspects for large models. While TestPilot is actively discussed in academic circles (see Cornell's articles on the topic), its engineering-level application remains distant.
Lastly, there's the issue of responsibility — a philosophical rather than technical challenge. Even with a 90% accuracy rate for ChatGPT, let alone a hypothetical 99.9999%, would you trust it to automatically calculate the entire company's payroll and initiate direct salary transfers with banks? If a problem arises, who's accountable? Not all business challenges can be solved with technology, and the same applies to large models.
Future Outlook
We're currently in the early stages of large model-driven automated programming. Many developers are still experimenting with Co-Pilot and ChatGPT, and most programmers haven't yet utilized private large models to boost coding efficiency based on their company's context. However, over the next 3-5 years, automated assistance in programming will undoubtedly become a staple tool for our generation of developers:
- Foundational large models will narrow the gap with ChatGPT, improving usability.
- Open-source large models will enhance accuracy and performance, resulting in improved ROI for more companies that adopt private large models.
- The threshold for large model-driven automation will decrease, with the emergence of more tools for democratized large model training — beyond Apache DolphinScheduler.
- Awareness of large model-driven automated programming will increase among technical managers, leading to adaptations in technical management processes.
- Amid the current economic cycle, leveraging large models to enhance efficiency becomes imperative.
Therefore, over the next few years, if your development process remains limited to CRUD operations and you can't harness large models to amplify your expertise and business comprehension by 10 or 100 times, you might not need to wait until you're 35 to be replaced by programmers adept at large model programming. Once they've scaled up by a factor of 10, you might find yourself among the nine who are left behind.
While this might sound a bit alarmist, the trend toward large model-driven automation in programming is an unstoppable force. I'm just a novice explorer in the realm of large model-driven automated programming, and I believe many technical managers and architects will join the wave of large model-driven automation, continuously iterating and optimizing the relationship between humans and large models within the development field. Ultimately, this synergy will make programmers, AI, and technical development processes more effective in serving businesses.
Published at DZone with permission of Debra Chen. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments