Processing Paradigms: Stream vs. Batch in the AI Era
Efficiently processing and ingesting data is a requirement for any organization. Both batch and stream processing play important roles in artificial intelligence.
Join the DZone community and get the full member experience.
Join For FreeBatch and Stream: An Introduction
Batching is a tried-and-true approach to data processing and ingestion. Batch processing involves taking bounded (finite) input data, running a job on it for processing, and producing some output data. Success is generally measured by throughput and data quality.
Batch jobs can be run sequentially, and are typically executed on a schedule. Because batch jobs typically require the accumulation of data over time and process a lot of data all at once, it can introduce significant latency into a system.
Stream processing, on the other hand, consumes inputs and produces outputs continuously. Stream jobs operate on “events,” shortly after they occur. Events are small, self-contained, immutable objects containing the details of something that happened. These events are often managed by a message broker like Apache Kafka, where they are collected, stored, and made available to consumers. This design forgoes arbitrarily dividing data by time, which allows for data to be ingested or processed in near-real-time.
Stream processing introduces fault tolerance concerns. Unlike in a batch process, where the input data is finite and failed jobs can simply be re-run, stream jobs work on data that is constantly arriving. Different streaming frameworks take different approaches to this problem. Apache Flink periodically generates rolling checkpoints of state and writes them to durable storage. If there is a failure, processes can resume from the checkpoint (typically created every few seconds). Another approach is to divide the events into second-sized batches in a process called “microbatching.” Apache Spark leverages this technique in its streaming framework.
How To Choose Your Paradigm
There are two major questions to ask yourself when deciding between implementing batch processing or stream processing pipelines.
What are my latency requirements?
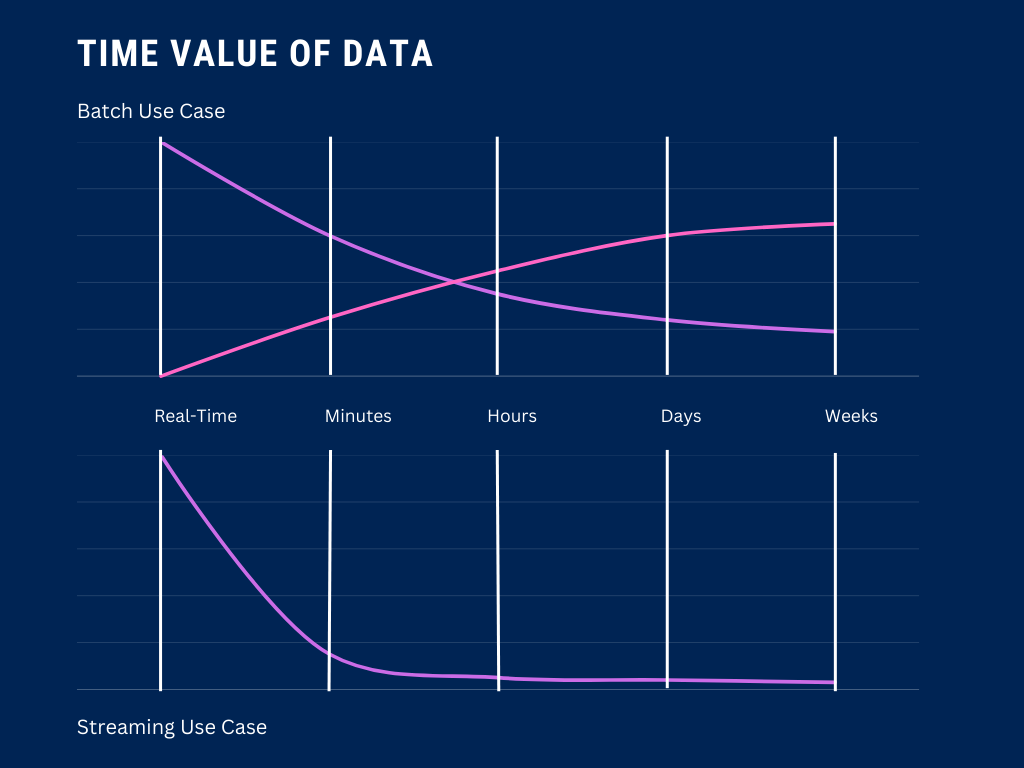
To understand if your use case can tolerate the latency that batch processing introduces, it’s useful to think about the time value of your data. If there is a high rate of decay in the business value of your data within the first few minutes after it is emitted, batch processing should not be your first choice.
But the truth is, the majority of decision-making doesn’t happen on a second-to-second basis. That’s why batch processing is so ubiquitous — whether you’re replicating a database, building reports, or updating dashboards, batch processing will often be enough to get the job done.
What resources are available to build and maintain the pipeline?
Cost is an important consideration in any architecture. As of this writing, batch is still generally more cost-effective than streaming. From resource optimization to system maintenance and cost of implementation, batch wins on affordability.
Stream and Batch for AI
When building training and deploying your own AI models, the question of batch or stream processing is no longer an either-or. In this section, we’ll examine how batch and stream processing work together during the training and deployment phase.
Batch processing is ideal during the initial training process — there is typically a lot of historical data that needs to be ingested and processed. When the initial training is complete, stream processing is an excellent paradigm for training models on real-time data. This allows for more adaptive, dynamic models that evolve as new data comes in.
Once the model is deployed, batch inference can be used for running inference on large datasets, such as daily sales predictions or monthly risk assessments. Streaming, on the other hand, can be used for real-time inference, which is essential for tasks like anomaly detection and real-time recommendation engines.
Both paradigms play a part in training, deploying, and maintaining quality AI models. Mastering both is essential for data practitioners tasked with building AI applications internally.
Conclusion
When choosing between stream and batch for your data pipelines, ensure you spend enough time gathering requirements, analyzing your available resources, and understanding stakeholder needs. This should ultimately decide which approach you take.
At Airbyte, we use the batch processing paradigm to move your data. If you’re interested in learning more, check out this article on CDC about how to keep data stores in sync.
Published at DZone with permission of John Lafleur. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments