Preventing and Fixing Bad Data in Event Streams: Part 2
The techniques we use for dealing with bad data in event streams differ from those in the batch world. Here, learn more about overcoming bad data in streaming.
Join the DZone community and get the full member experience.
Join For FreeAlright, I’m back — time for part 2.
In the first part, I covered how we handle bad data in batch processing; in particular, cutting out the bad data, replacing it, and running it again. But this strategy doesn’t work for immutable event streams as they are, well, immutable. You can’t cut out and replace bad data like you would in batch-processed data sets.
Thus, instead of repairing after the fact, the first technique we looked at is preventing bad data from getting into your system in the first place. Use schemas, tests, and data quality constraints to ensure your systems produce well-defined data. To be fair, this strategy would also save you a lot of headaches and problems in batch processing.
Prevention solves a lot of problems. But there’s still a possibility that you’ll end up creating some bad data, such as a typo in a text string or an incorrect sum in an integer. This is where our next layer of defense in the form of event design comes in.
Event design plays a big role in your ability to fix bad data in your event streams. And much like using schemas and proper testing, this is something you’ll need to think about and plan for during the design of your application. Well-designed events significantly ease not only bad data remediation issues but also related concerns like compliance with GDPR and CCPA.
And finally, we’ll look at what happens when all other lights go out — you’ve wrecked your stream with bad data and it’s unavoidably contaminated. Then what? Rewind, Rebuild, and Retry.
But to start we’ll look at event design, as it will give you a much better idea of how to avoid shooting yourself in the foot from the get-go.
Fixing Bad Data Through Event Design
Event design heavily influences the impact of bad data and your options for repairing it. First, let’s look at State (or Fact) events, in contrast to Delta (or Action) events.
State events contain the entire statement of fact for a given entity (e.g., Order, Product, Customer, Shipment). Think of state events exactly like you would think about rows of a table in a relational database — each presents an entire accounting of information, along with a schema, well-defined types, and defaults (not shown in the picture for brevity’s sake).
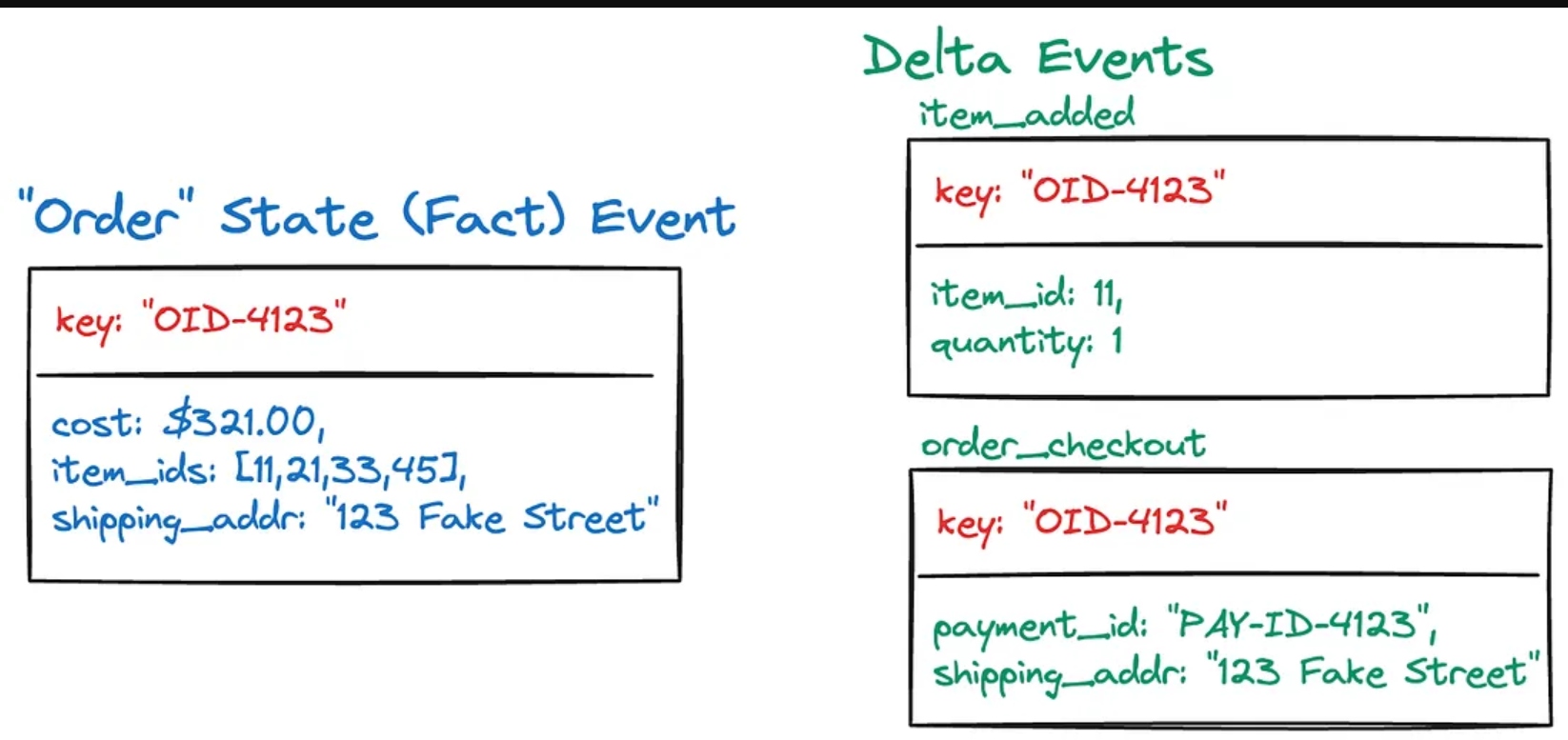
State events enable event-carried state transfer (ECST), which lets you easily build and share state across services. Consumers can materialize the state into their own services, databases, and data sets, depending on their own needs and use cases.
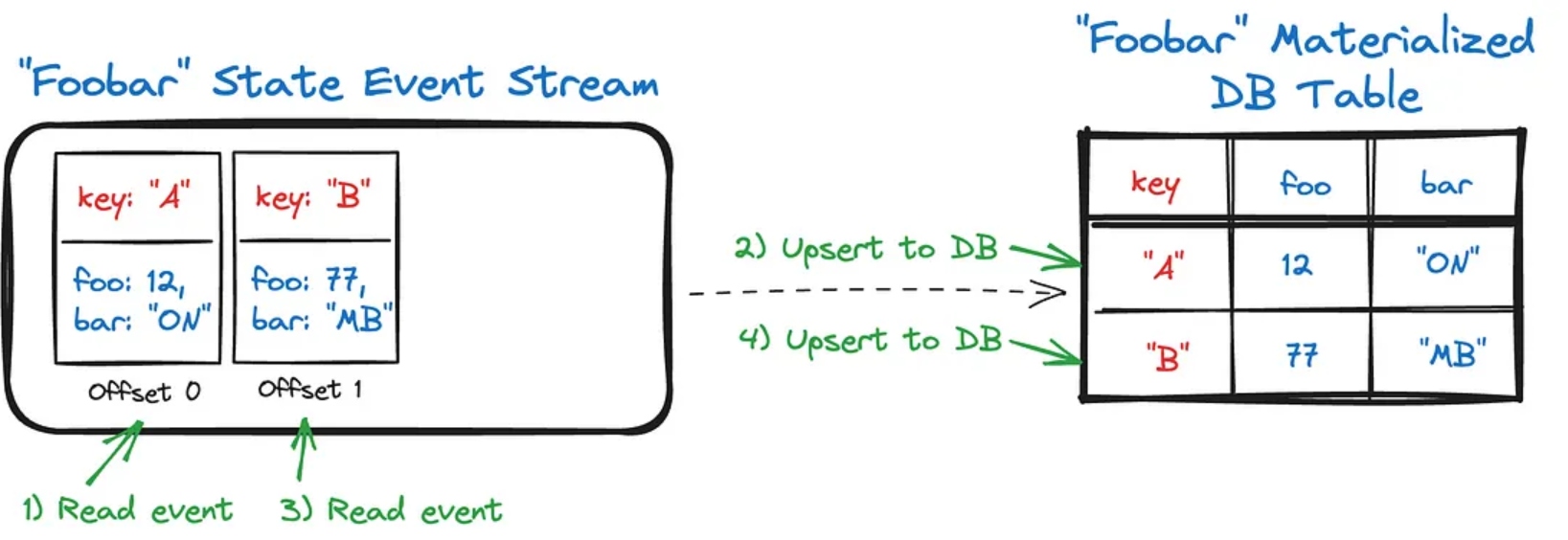
Materializing is pretty straightforward. The consumer service reads an event (1) and then upserts it into its own database (2), and you repeat the process (3 and 4) for each new event. Every time you read an event, you have the option to apply business logic, react to the contents, and otherwise drive business logic.
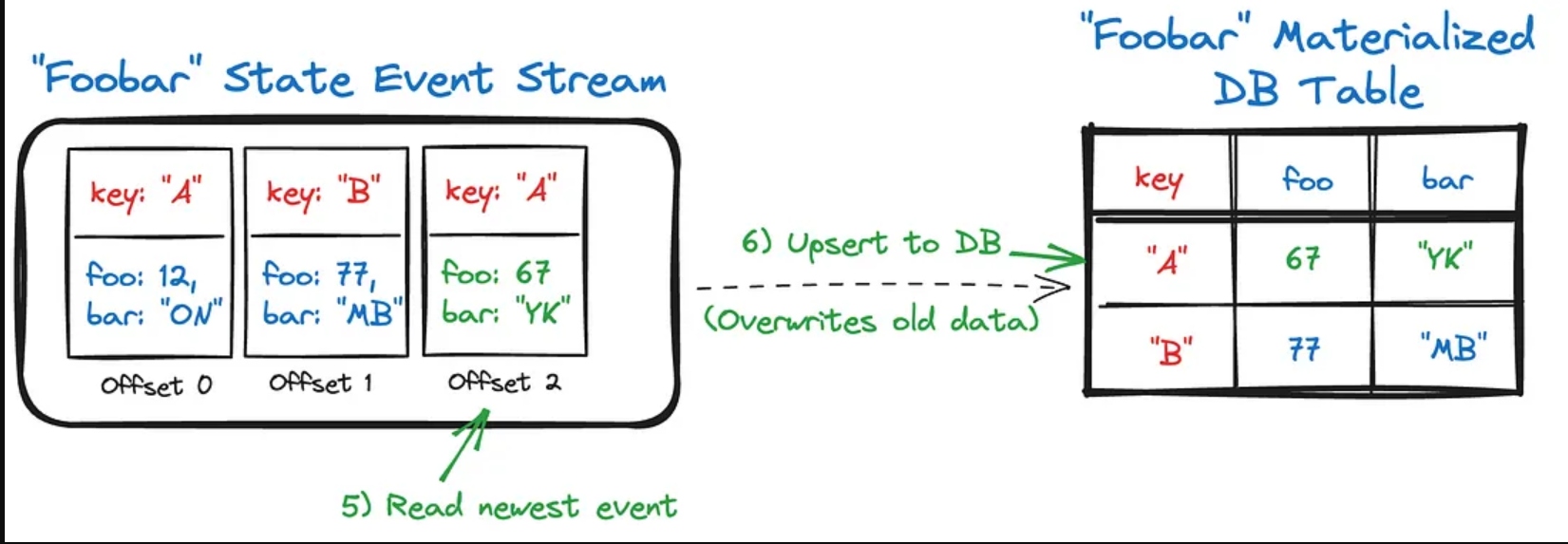
Updating the data associated with a Key “A” (5) results in a new event. That event is then consumed and upserted (6) into the downstream consumer data set, allowing the consumer to react accordingly. Note that your consumer is not obligated to store any data that it doesn’t require — it can simply discard unused fields and values.
Deltas, on the other hand, describe a change or an action. In the case of the Order, they describe item_added, and order_checkout, though reasonably you should expect many more deltas, particularly as there are many different ways to create, modify, add, remove, and change an entity.
Though I can (and do) go on and on about the tradeoffs of these two event design patterns, the important thing for this post is that you understand the difference between Delta and State events. Why? Because only State events benefit from topic compaction, which is critical for deleting bad, old, private, and/or sensitive data.
Compaction is a process in Apache Kafka that retains the latest value for each record key (e.g., Key = “A”, as above) and deletes older versions of that data with the same record key. Compaction enables the complete deletion of records via tombstones from the topic itself — all records of the same key that come before the tombstone will be deleted during compaction.
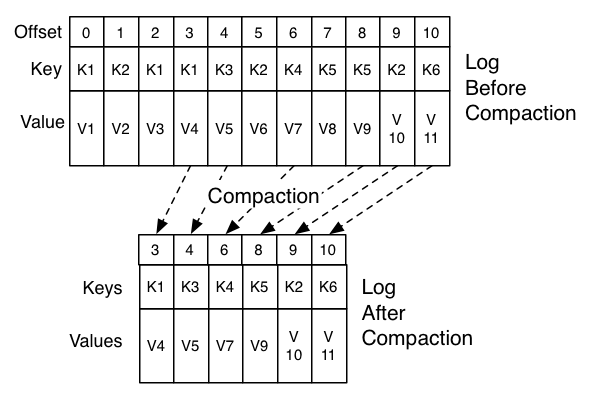
Aside from enabling deletion via compaction, tombstones also indicate to registered consumers that the data for that key has been deleted and they should act accordingly. For example, they should delete the associated data from their own internal state store, update any business operations affected by the deletion, and emit any associated events to other services.
Compaction contributes to the eventual correctness of your data, though your consumers will still need to deal with any incorrect side-effects from earlier incorrect data. However, this remains identical as if you were writing and reading to a shared database — any decisions made off the incorrect data, either through a stream or by querying a table, must still be accounted for (and reversed if necessary). The eventual correction only prevents future mistakes.
State Events: Fix It Once, Fix It Right
It’s really easy to fix bad state data. Just correct it at the source (e.g., the application that created the data), and the state event will propagate to all registered downstream consumers. Compaction will eventually clean up the bad data, though you can force compaction, too, if you cannot wait (perhaps due to security reasons).
You can fiddle around with compaction settings to better suit your needs, such as compacting ASAP or only compacting data older than 30 days (min.compaction.lag.ms= 2592000000). Note that active Kafka segments can’t be compacted immediately, the segment must first be closed.
I like state events. They’re easy to use and map to database concepts that the vast majority of developers are already familiar with. Consumers can also infer the deltas of what has changed from the last event (n-1) by comparing it to their current state (n). And even more, they can compare it to the state before that (n-2), before that (n-3), and so forth (n-x), so long as you’re willing to keep and store that data in your microservice’s state store.
“But wait, Adam!”
I have heard (many) times before.
“Shouldn’t we store as little data as possible so that we don’t waste space?”
Eh, Kinda.
Yes, you should be careful with how much data you move around and store, but only after a certain point. But this isn’t the 1980s, and you’re not paying $339.8 per MB for disk. You’re far more likely to be paying $0.08/GB-month for AWS EBS gp3, or you’re paying $0.023/GB-month for AWS S3.

State is cheap. Network is cheap. Be careful about cross-AZ costs, which some writers have identified as anti-competitive, but by and large, you don’t have to worry excessively about replicating data via State events.
Maintaining a per-microservice state is very cheap these days, thanks to cloud storage services. And since you only need to keep the state your microservices or jobs care about, you can trim the per-consumer replication to a smaller subset in most cases. I’ll probably write another blog about the expenses of premature optimization, but just keep in mind that state events provide you with a ton of flexibility and let you keep complexity to a minimum. Embrace today’s cheap compute primitives, and focus on building useful applications and data products instead of trying to slash 10% of an event’s size (heck — just use compression if you haven’t already).
But now that I’ve ranted about state events, how do they help us fix the bad data? Let’s take a look at a few simple examples, one using a database source, one with a topic source, and one with an FTP source.
State Events and Fixing at the Source
Kafka Connect is the most common way to bootstrap events from a database. Updates made to a registered database’s table rows (Create, Update, Delete) are emitted to a Kafka topic as discrete state events.
You can, for example, connect to a MySQL, PostgreSQL, MongoDB, or Oracle database using Debezium (a change-data capture connector). Change-data events are state-type events and feature both before and after fields indicating the before state and after state due to the modification. You can find out more in the official documentation, and there are plenty of other articles written on CDC usage on the web.
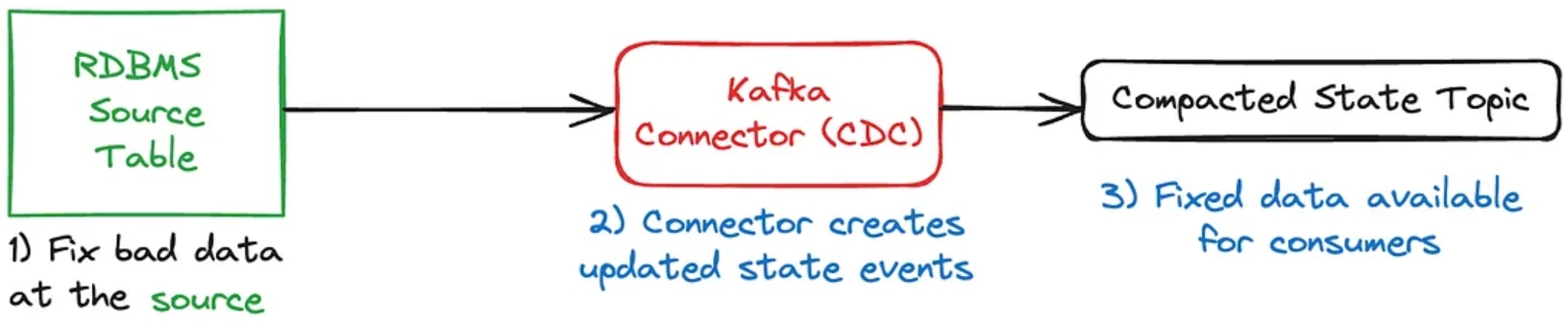
To fix the bad data in your Kafka Connect-powered topic, simply fix the data in your source database (1). The change-data connector (CDC, 2a) takes the data from the database log, packages it into events, and publishes it to the compacted output topic. By default, the schema of your state type maps directly to your table source — so be careful if you’re going to go about migrating your tables.
Note that this process is exactly the same as what you would do for batch-based ETL. Fix the bad data at source, rerun the batch import job, then upsert/merge the fixes into the landing table data set. This is simply the stream-based equivalent.

Similarly, for example, a Kafka Streams application (2) can rely on compacted state topics (1) as its input, knowing that it’ll always get the eventual correct state event for a given record. Any events that it might publish (3) will also be corrected for its own downstream consumers.
If the service itself receives bad data (say a bad schema evolution or even corrupted data), it can log the event as an error, divert it to a dead-letter queue (DLQ), and continue processing the other data (Note that we talked about dead-letter queues and validation back in part 1).
Lastly, consider an FTP directory where business partners (AKA the ones who give us money to advertise/do work for them) drop documents containing information about their business. Let’s say they’re dropping in information about their total product inventory so that we can display the current stock to the customer. (Yes, sometimes this is as close to event streaming as a partner is willing or able to get).
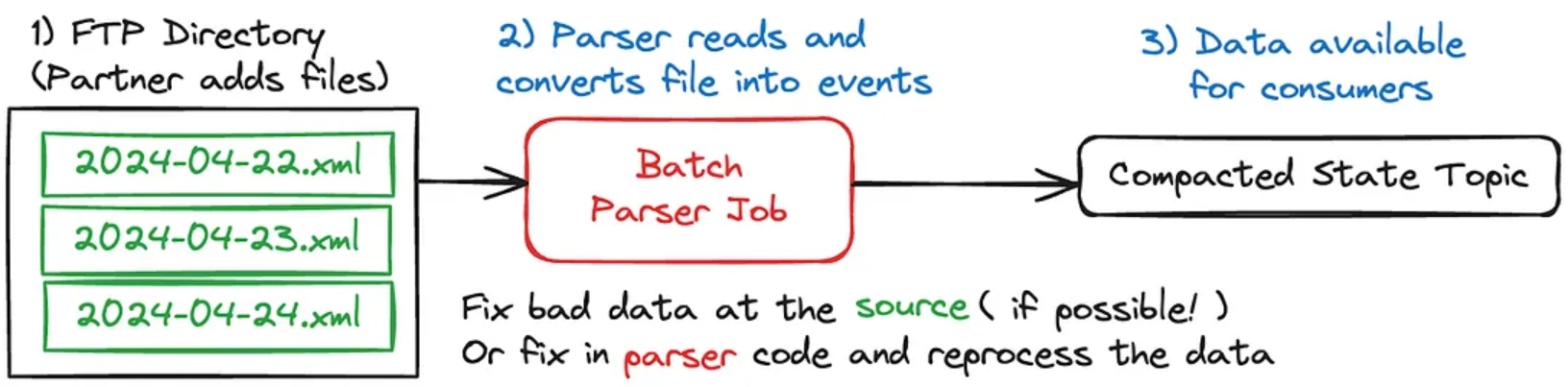
We’re not going to run a full-time streaming job just idling away, waiting for updates to this directory. Instead, when we detect a file landing in the bucket, we can kick off a batch-based job (AWS Lambda?), parse the data out of the .xml file, and convert it into events keyed on the productId representing the current inventory state.
If our partner passes us bad data, we’re not going to be able to parse it correctly with our current logic. We can, of course, ask them nicely to resend the correct data (1), but we might also take the opportunity to investigate what the error is, to see if it’s a problem with our parser (2), and not their formatting. Some cases, such as if the partner sends a completely corrupted file, require it to be resent. In other cases, they may simply leave it to us data engineers to fix it up on our own.
So we identify the errors, add code updates, and new test cases, and reprocess the data to ensure that the compacted output (3) is eventually accurate. It doesn’t matter if we publish duplicate events since they’re effectively benign (idempotent), and won’t cause any changes to the consumer’s state.
That’s enough for state events. By now you should have a good idea of how they work. I like state events. They’re powerful. They’re easy to fix. You can compact them. They map nicely to database tables. You can store only what you need. You can infer the deltas from any point in time so long as you’ve stored them.
But what about deltas, where the event doesn’t contain state but rather describes some sort of action or transition? Buckle up.
Can I Fix Bad Data for Delta-Style Events?
“Now,” you might ask, “What about if I write some bad data into a delta-style event? Am I just straight out of luck?” Not quite. But the reality is that it’s a lot harder (like, a lot a lot) to clean up delta-style events than it is state-style events. Why?
The major obstacle to fixing deltas (and any other non-state event, like commands) is that you can’t compact them — no updates, no deletions. Every single delta is essential for ensuring correctness, as each new delta is in relation to the previous delta. A bad delta represents a change into a bad state. So what do you do when you get yourself into a bad state? You really have two strategies left:
- Undo the bad deltas with new deltas. This is a build-forward technique, where we simply add new data to undo the old data. (WARNING: This is very hard to accomplish in practice).
- Rewind, rebuild, and retry the topic by filtering out the bad data. Then, restore consumers from a snapshot (or from the beginning of the topic) and reprocess. This is the final technique for repairing bad data, and it’s also the most labor-intensive and expensive. We’ll cover this more in the final section as it technically also applies to state events.
Both options require you to identify every single offset for each bad delta event, a task that varies in difficulty depending on the quantity and scope of bad events. The larger the data set and the more delta events you have, the more costly it becomes — especially if you have bad data across a large keyspace.
These strategies are really about making the best out of a bad situation. I won’t mince words: Bad delta events are very difficult to fix without intensive intervention!
But let’s look at each of these strategies in turn. First up, build-forward, and then to cap off this blog, rewind, rebuild, and retry.
Build-Forward: Undo Bad Deltas With New Deltas
Deltas, by definition, create a tight coupling between the delta event models and the business logic of consumer(s). There is only one way to compute the correct state, and an infinite amount of ways to compute the incorrect state. And some incorrect states are terminal — a package, once sent, can’t be unsent, nor can a car crushed into a cube be un-cubed.
Any new delta events, published to reverse previous bad deltas, must put our consumers back to the correct good state without overshooting into another bad state. But it’s very challenging to guarantee that the published corrections will fix your consumer’s derived state. You would need to audit each consumer’s code and investigate the current state of their deployed systems to ensure that your corrections would indeed correct their derived state. It’s honestly just really quite messy and labor-intensive and will cost a lot in both developer hours and opportunity costs.
However… you may find success in using a delta strategy if the producer and consumer are tightly coupled and under the control of the same team. Why? Because you control entirely the production, transmission, and consumption of the events, and it’s up to you to not shoot yourself in the foot.
Fixing Delta-Style Events Sounds Painful
Yeah, it is. It’s one of the reasons why I advocate so strongly for state-style events. It’s so much easier to recover from bad data, to delete records (hello GDPR), to reduce complexity, and to ensure loose coupling between domains and services.
Deltas are popularly used as the basis of event sourcing, where the deltas form a narrative of all changes that have happened in the system. Delta-like events have also played a role in informing other systems of changes but may require the interested parties to query an API to obtain more information. Deltas have historically been popular as a means of reducing disk and network usage, but as we observed when discussing state events, these resources are pretty cheap nowadays and we can be a bit more verbose in what we put in our events.
Overall, I recommend avoiding deltas unless you absolutely need them (e.g., event sourcing). Event-carried state transfer and state-type events work extremely well and simplify so much about dealing with bad data, business logic changes, and schema changes. I caution you to think very carefully about introducing deltas into your inter-service communication patterns and encourage you to only do so if you own both the producer and the consumer.
For Your Information: “Can I Just Include the State in the Delta?”
I’ve also been asked if we can use events like the following, where there is a delta AND some state. I call these hybrid events, but the reality is that they provide guarantees that are effectively identical to state events. Hybrid events give your consumers some options as to how they store state and how they react. Let’s look at a simple money-based example.
Key: {accountId: 6232729}
Value: {debitAmount: 100, newTotal: 300}
In this example, the event contains both the debitAmount ($100) and the newTotal of funds ($300). But note that by providing the computed state (newTotal=$300), it frees the consumers from computing it themselves, just like plain old state events. There’s still a chance the consumer will build a bad aggregate using debitAmount, but that’s on them — you already provided them with the correct computed state.
There’s not much point in only sometimes including the current state. Either your consumers are going to depend on it all the time (state event) or not at all (delta event). You may say you want to reduce the data transfer over the wire — fine. But the vast majority of the time, we’re only talking about a handful of bytes, and I encourage you not to worry too much about event size until it costs you enough money to bother addressing. If you’re REALLY concerned, you can always invest in a claim-check pattern.
But let’s move on now to our last bad-data-fixing strategy.
The Last Resort: Rewind, Rebuild, and Retry
Our last strategy is one that you can apply to any topic with bad data, be it delta, state, or hybrid. It’s expensive and risky. It’s a labor-intensive operation that costs a lot of people hours. It’s easy to screw up, and doing it once will make you never want to do it again. If you’re at this point you’ve already had to rule out our previous strategies.
Let’s just look at two example scenarios and how we would go about fixing the bad data.
Rewind, Rebuild, and Retry from an External Source
In this scenario, there’s an external source from which you can rebuild your data. For example, consider an nginx or gateway server, where we parse each row of the log into its own well-defined event.
What caused the bad data? We deployed a new logging configuration that changed the format of the logs, but we failed to update the parser in lockstep (tests, anyone?). The server log file remains the replayable source of truth, but all of our derived events from a given point in time onwards are malformed and must be repaired.
Solution
If your parser/producer is using schemas and data quality checks, then you could have shunted the bad data to a DLQ. You would have protected your consumers from the bad data but delayed their progress. Repairing the data in this case is simply a matter of updating your parser to accommodate the new log format and reprocessing the log files. The parser produces correct events, sufficient schema, and data quality, and your consumers can pick up where they left off (though they still need to contend with the fact that the data is late).
But what happens if you didn’t protect the consumers from bad data, and they’ve gone and ingested it? You can’t feed them hydrogen peroxide to make them vomit it back up, can you?
Let’s check how we’ve gotten here before going further:
- No schemas (otherwise would have failed to produce the events)
- No data quality checks (ditto)
- Data is not compactable and the events have no keys
- Consumers have gotten into a bad state because of the bad data
At this point, your stream is so contaminated that there’s nothing left to do but purge the whole thing and rebuild it from the original log files. Your consumers are also in a bad state, so they’re going to need to reset either to the beginning of time or to a snapshot of internal state and input offset positions.
Restoring your consumers from a snapshot or savepoint requires planning ahead (prevention, anyone?). Examples include Flink savepoints, MySQL snapshots, and PostgreSQL snapshots, to name just a few. In either case, you’ll need to ensure that your Kafka consumer offsets are synced up with the snapshot’s state. For Flink, the offsets are stored along with the internal state. With MySQL or PostgreSQL, you’ll need to commit and restore the offsets into the database, to align with the internal state. If you have a different data store, you’ll have to figure out the snapshotting and restores on your own.
As mentioned earlier, this is a very expensive and time-consuming resolution to your scenario, but there’s not much else to expect if you use no preventative measures and no state-based compaction. You’re just going to have to pay the price.
Rewind, Rebuild, and Retry With the Topic as the Source
If your topic is your one and only source, then any bad data is your fault and your fault alone. If your events have keys and are compactable, then just publish the good data over top of the bad. Done. But let’s say we can’t compact the data because it doesn’t represent state? Instead, let’s say it represents measurements.
Consider this scenario. You have a customer-facing application that emits measurements of user behavior to the event stream (think clickstream analytics). The data is written directly to an event stream through a gateway, making the event stream the single source of truth. But because you didn’t write tests nor use a schema, the data has accidentally been malformed directly in the topic. So now what?
Solution
The only thing you can do here is reprocess the “bad data” topic into a new “good data” topic. Just as when using an external source, you’re going to have to identify all of the bad data, such as by a unique characteristic in the malformed data. You’ll need to create a new topic and a stream processor to convert the bad data into good data.
This solution assumes that all of the necessary data is available in the event. If that is not the case, then there’s little you can do about it. The data is gone. This is not CSI:Miami where you can yell, “Enhance!” to magically pull the data out of nowhere.
So let’s assume you’ve fixed the data and pushed it to a new topic. Now all you need to do is port the producer over, then migrate all of the existing consumers. But don’t delete your old stream yet. You may have made a mistake migrating it to the new stream and may need to fix it again.
Migrating consumers isn’t easy. A polytechnical company will have many different languages, frameworks, and databases in use by their consumers. To migrate consumers, for example, we typically must:
- Stop each consumer, and reload their internal state from a snapshot made prior to the timestamps of the first bad data.
- That snapshot must align with the offsets of the input topics, such that the consumer will process each event exactly once. Not all stream processors can guarantee this (but it is something that Flink is good at, for example).
- But wait! You created a new topic that filtered out bad data (or added missing data). Thus, you’ll need to map the offsets from the original source topic to the new offsets in the new topic.
- Resume processing from the new offset mappings, for each consumer.
If your application doesn’t have a database snapshot, then we must delete the entire state of the consumer and rebuild it from the start of time. This is only possible if every input topic contains a full history of all deltas. Introduce even just one non-replayable source and this is no longer possible.
Summary
In Part 1, I covered how we do things in the batch world, and why that doesn’t transfer well to the streaming world. While event stream processing is similar to batch-based processing, there is significant divergence in strategies for handling bad data.
In batch processing, a bad dataset (or partition of it) can be edited, corrected, and reprocessed after the fact. For example, if my bad data only affected computations pertaining to 2024–04–22, then I can simply delete that day’s worth of data and rebuild it. In batch, no data is immutable, and everything can be blown away and rebuilt as needed. Schemas tend to be optional, imposed only after the raw data lands in the data lake/warehouse. Testing is sparse, and reprocessing is common.
In streaming, data is immutable once written to the stream. The techniques that we can use to deal with bad data in streaming differ from those in the batch world.
- The first one is to prevent bad data from entering the stream. Robust unit, integration, and contract testing, explicit schemas, schema validation, and data quality checks each play important roles. Prevention remains one of the most cost-effective, efficient, and important strategies for dealing with bad data —to just stop it before it even starts.
- The second is event design. Choosing a state-type event design allows you to rely on republishing records of the same key with the updated data. You can set up your Kafka broker to compact away old data, eliminating incorrect, redacted, and deleted data (such as for GDPR and CCPA compliance). State events allow you to fix the data once, at the source, and propagate it out to every subscribed consumer with little-to-no extra effort on your part.
- Third and finally is Rewind, Rebuild, and Retry. A labor-intensive intervention, this strategy requires you to manually intervene to mitigate the problems of bad data. You must pause consumers and producers, fix and rewrite the data to a new stream, and then migrate all parties over to the new stream. It’s expensive and complex and is best avoided if possible.
Prevention and good event design will provide the bulk of the value for helping you overcome bad data in your event streams. The most successful streaming organizations I’ve worked with embrace these principles and have integrated them into their normal event-driven application development cycle. The least successful ones have no standards, no schemas, no testing, and no validation — it’s a wild west, and many a foot is shot.
Anyways, if you have any scenarios or questions about bad data and streaming, please reach out to me on LinkedIn. My goal is to help tear down misconceptions and address concerns around bad data and streaming, and to help you build up confidence and good practices for your own use cases. Also, feel free to let me know what other topics you’d like me to write about, I’m always open to suggestions.
Published at DZone with permission of Adam Bellemare. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments