Popular Design Patterns for Microservices Architectures
In this article, learn about the most important design patterns that are essential to building and developing a microservices application.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Microservices and Containerization Trend Report.
For more:
Read the Report
Applications have been built with monolithic architectures for decades; however, many are now moving to a microservices architecture. Microservices architectures gives us faster development speed, scalability, reliability, the flexibility to develop each component with the best tech stack suitable, and much more. Microservices architectures rely on independently deployable microservices. Each microservice has its own business logic and database consisting of a specific domain context. The testing, enhancing, and scaling of each service is independent of other microservices.
However, a microservices architecture is also prone to its own challenges and complexity. To solve the most common challenges and problems, some design patterns have evolved. In this article, we will look at a few of them.
Essential Design Patterns
There are more than eight must-have design patterns for smooth development in a typical microservices architecture. In this section, we will take a look at these patterns in more detail. We have divided them into two sections based on the type of applications being created — greenfield or brownfield.
Design Patterns for Greenfield Applications
When we build an application from scratch, we get the freedom to apply all the latest and modern design patterns required for a microservices architecture. Let’s take a deep dive into a few of them.
API Gateway Pattern
Breaking down the whole business logic into multiple microservices brings various issues, leading to questions such as:
- How do you handle cross-cutting concerns such as authorization, rate limiting, load balancing, retry policies, service discovery, and so on?
- How do you avoid too many round trips and tight coupling due to direct client-to-microservice communication?
- Who will do the data filtering and mapping in case a subset of data is required by a client?
- Who will do the data aggregation in case a client requires calling multiple microservices to get data?
To address these concerns, an API gateway sits between the client applications and microservices. It brings features like reverse proxy, requests aggregation, gateway offloading, service discovery, and many more. It can expose a different API for each client.
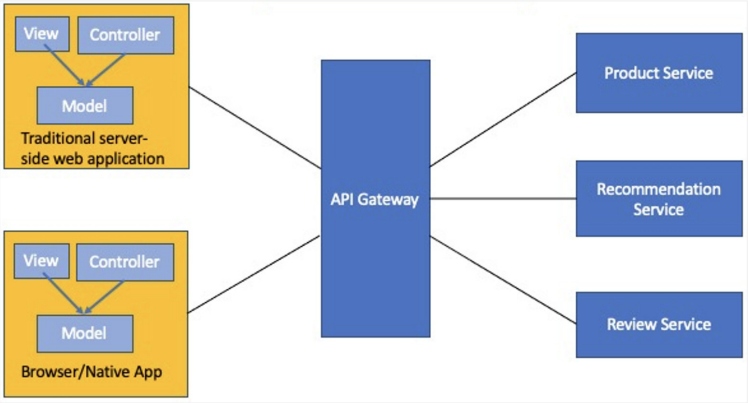
Figure 1: API gateway example
Source: Diagram adapted from Microservices.io documentation
Client-side UI Composition Pattern
In this pattern, microservices are developed by business-capabilities-oriented teams. Some UI screens may need data from multiple microservices. For example, a shopping site will include features such as a catalog, shopping cart, buying options, customer reviews, and so on. Each data item belongs to a specific microservice. Now each data item to be displayed is the responsibility of a different team. How can we solve this?
A UI team should create a page skeleton that builds screens by composing multiple UI components. Each team develops a client-side UI component that is service-specific. This skeleton is also known as a single-page application (SPA). Frameworks like AngularJS directives and ReactJS components support this. This also allows users to refresh a specific region of the screen when any data changes, providing a better user experience.
Database per Service Pattern
Microservices need to be independent and loosely coupled. So what should the database architecture be for a microservice application?
- A typical business transaction may involve queries, joins, or data persistence actions from multiple services owned by different teams.
- In polyglot microservices architectures, where each microservice may have different data storage requirements, consider unstructured data (NoSQL database), structured data (relational database), and/or graph data (Neo4j).
- Databases need replications and sharding for scaling purposes.
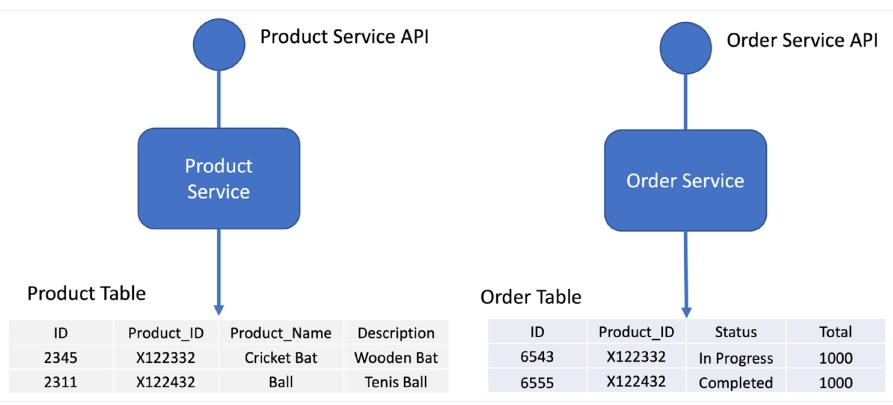
Figure 2: Example of a database per service
Source: Diagram adapted from Microservices.io documentation
A microservice transaction must be limited to its own database. Any other service requiring that data must use a service API. If you are using a relational database, then a schema per service is the best option to make the data private to the microservice. To create a barrier, assign a different database user ID to each service. This ensures developers are not tempted to bypass a microservice’s API and access the database directly.
This enables each microservice to use the type of database best suited for its requirements. For example, use Neo4j for social graph data and Elasticsearch for text search.
Saga Pattern
When we use one database per service, it creates a problem with implementing transactions that span multiple microservices. How do we bring data consistency in this case? Local ACID transactions don’t help here. The solution is the saga pattern. A saga is a chain of local transactions where each transaction updates the database and publishes an event to trigger the next local transaction. The saga pattern mandates compensating transactions in case any local transaction fails.
There are two ways to implement saga:
- Orchestration – An orchestrator (object) coordinates with all the services to do local transactions, get updates, and execute the next event. In case of failure, it holds the responsibility to trigger the compensation events.
- Choreography – Each microservice is responsible for listening to and publishing events, and it enables the compensation events in case of failure.
Orchestration is much simpler to implement than choreography. In orchestration, only one component needs to coordinate all the events, whereas in choreography, each microservice must listen and react to events.
Circuit Breaker Pattern
In microservices architectures, a transaction involves calling multiple services. If a downstream microservice is down, it will keep calling to the service and exhaust network resources for all other services as well. It also impacts the user experience. How do we handle the cascading failures?
Electric circuit breaker functionality inspired the circuit breaker pattern — the solution to this issue. A proxy sits between a client and a microservice, which tracks the number of consecutive failures. If it crosses a threshold, it trips the connection and fails immediately. After a timeout period, the circuit breaker again allows a limited number of test requests to check if the circuit can be resumed. Otherwise, the timeout period resets.
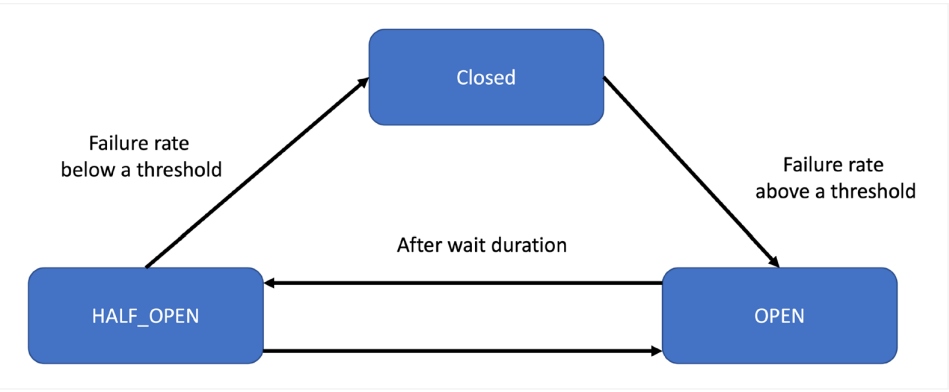
Figure 3: Circuit breaker stages
Source: Diagram adapted from "Circuit Breaker Implementation in Resilience4j," Bohdan Storozhuk
Java’s resilence4j framework provides this proxy service.
Decomposition by Business Capability or Subdomain Pattern
In microservices architectures, a large complex application must be decomposed, cohesive, as well as loosely coupled. It should also be autonomous and small enough to be developed by a “pizza-sized” team (six to eight members). How do we decompose it?
There are two ways to decompose a greenfield application — by business capability or subdomain:
- A business capability is something that generates value. For example, in an airline company, business capabilities can be bookings, sales, payment, seat allocation, and so on.
- The subdomain concept comes from domain-driven design (DDD). A domain consists of multiple subdomains, such as product catalog, order management, delivery management, and so on.
Design Patterns for Brownfield Applications
Because we have been building applications for decades, around 80 percent of companies run on existing applications that are known as brownfield applications. Migrating a brownfield application to microservices is the most challenging task. Let’s have a look at certain design patterns that can help make migration easier.
Strangler Fig Pattern
How do we migrate a monolithic application to a microservices architecture? The strangler pattern is based on a vine analogy that strangles the tree it wraps around. In this pattern, a small part of the monolithic application is converted to a microservice, and for the customer, nothing changes as the external API remains the same. Slowly, all the parts are refactored to microservices, and the new architecture "strangles," or replaces, the original monolithic architecture.
Anti-Corruption Layer Pattern
When a modern application needs to integrate with a legacy application, it is challenging to interoperate with outdated infrastructure protocols, APIs, and data models. Adhering to old patterns and semantics may corrupt the new system. How can we avoid that?
This requires a layer that translates communication between the two systems. An anti-corruption layer conforms to the data model of the legacy or modern system, depending on which system it is communicating with to get the data. It ensures the old system doesn’t need to change, and the modern system doesn’t compromise on its design and technology.
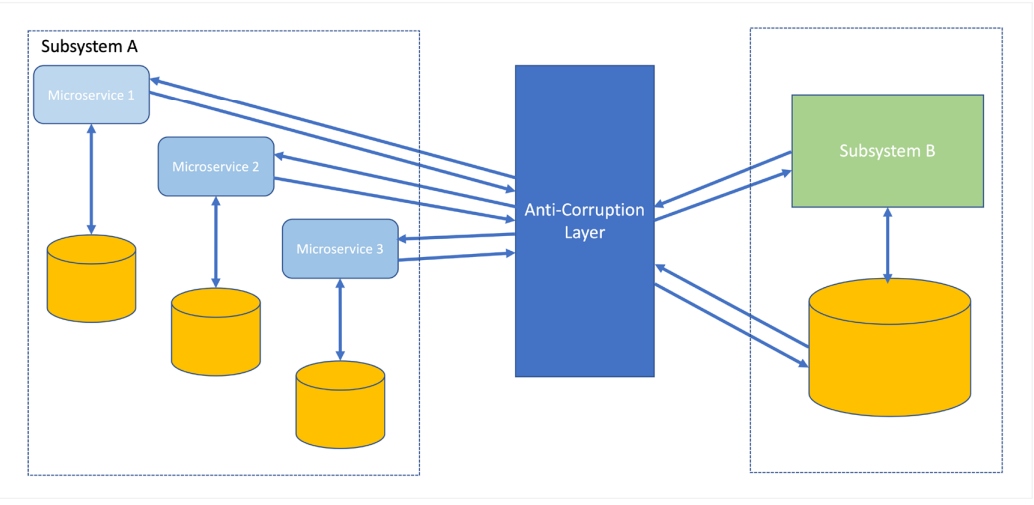
Figure 4: Anti-corruption layer example
Source: Diagram adapted from Microservices.io documentation
Conclusion
Microservices architectures provide a lot of flexibility for developers but also bring many challenges as the number of components to manage increases. In this article, we have talked about the most important design patterns that are essential to building and developing a microservices application.
Additional resources to help you get started:
- "Design Patterns for Microservices"
- "Distributed Sagas for Microservices"
- "API Gateway to the Rescue"
- Microsoft Documentation, Strangler Fig Pattern
This is an article from DZone's 2022 Microservices and Containerization Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments