Pipelining To Increase Throughput of Stream Processing Systems
Pipelining boosts stream processing throughput by enabling parallelism among independent threads using shared queues for coordination.
Join the DZone community and get the full member experience.
Join For FreeInstruction Pipelining is used in CPU architectures to improve the throughput of the CPU at a given clock rate. The same pipelining concept can be used to increase the throughput of stream processing systems.
Stream Processing Systems
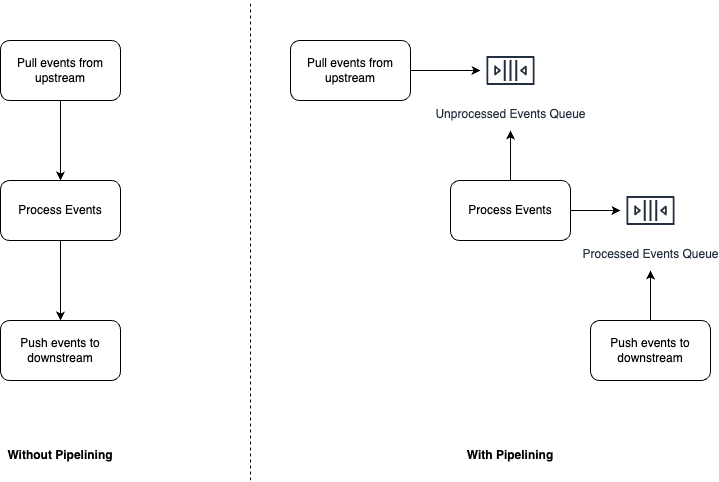
Stream processing systems process an input stream of data to generate an output stream of data. These systems are typically used to perform actions such as data transformation, filtering, data augmentation, etc. All these systems generally follow the same high-level algorithm, pull events from upstream, process events, and push processed events downstream.
Without Pipelining
This algorithm can be implemented in a single threaded execution model whereby one thread pulls events from upstream, processes the events, and finally pushes processed events downstream. In this implementation, the execution thread cannot pull more events from upstream till it has pushed all the processed events to downstream.
The single threaded execution model, while is simple to understand and implement, does not provide the maximum throughput possible. Let's say it takes ~250 milliseconds to pull 1000 events from upstream, ~500 milliseconds to process them, and another ~250 milliseconds to push the processed events to downstream. Hence, the throughput of our system comes out to be ~1000 events per second.
/**
* This class demonstrates a single threaded execution model of a stream processing system
*/
public class SingeThreadedStreamProcessor {
/**
* The method simulates the pull from upstream step.
* @param setName Name of the event set
*/
private void pullFromUpstream(String setName) {
try {
System.out.println("Pulling " + setName);
Thread.sleep(250);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* This method simulates the processing step.
* @param setName Name of the event set
*/
private void processEvents(String setName) {
try {
System.out.println("Processing " + setName);
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* This method simulates the push to downstream step
* @param setName Name of the event set
*/
private void pushToDownstream(String setName) {
try {
System.out.println("Publishing " + setName);
Thread.sleep(250);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* This method executes the end to end algorithm for consuming an event set.
* @param setName Name of the event set
*/
public void consumeAnEventSet(String setName) {
pullFromUpstream(setName);
processEvents(setName);
pushToDownstream(setName);
}
}Assuming we are consuming six event sets, the above code will take roughly six seconds to perform the end-end algorithm.
public class SingleThreadedStreamProcessorTest {
public static void main(String[] args) {
SingeThreadedStreamProcessor processor = new SingeThreadedStreamProcessor();
long beginTime = System.currentTimeMillis();
for (int i = 0; i < 6; i++) {
processor.consumeAnEventSet("set" + (i + 1));
}
long endTime = System.currentTimeMillis();
System.out.println("Time taken to process:" + (endTime-beginTime) + "ms");
}
}Output:
Pulling set1
Processing set1
Publishing set1
Pulling set2
Processing set2
Publishing set2
Pulling set3
Processing set3
Publishing set3
Pulling set4
Processing set4
Publishing set4
Pulling set5
Processing set5
Publishing set5
Pulling set6
Processing set6
Publishing set6
Time taken to process:6072ms
With Pipelining
As defined for CPU architectures, instruction pipelining is a technique for implementing instruction-level parallelism within a single processor. In case of stream processing systems, the same concepts apply. We can break the high-level algorithm into three instruction sets that can be all executed in parallel.
Instead of having one thread execute the entire algorithm, we can have three threads each working on one instruction set and use shared queues for co-ordination.
- Event Puller thread: This thread is responsible for pulling events from upstream and writing them to a local in-memory queue, let's call it the "Unprocessed Events Queue".
- Event Processor thread: This thread is responsible for pulling events from the "Unprocessed Events Queue," processing them, and writing processed events to another local in-memory queue, let's call it the "Processed Events Queue".
- Event Publisher thread: This thread is responsible for pulling events from the "Processed Events Queue" and pushing them to downstream.
At a given point in time, all three threads will be doing work, thereby ensuring that we get the max throughput from this implementation.
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
/**
* This class demonstrates how a Stream Processing System can use Pipelining to efficiently use system resources
* and increase its throughput. It establishes three threads that each perform an independent instruction while using
* shared queues to transfer work over.
*/
public class MultiThreadedStreamProcessor {
// Queue to hold the input events
// Think of this queue as it belongs to the upstream system
private final Queue<String> inputEventsQueue_;
// Queue to hold the events that have been pulled from upstream
private final Queue<String> unProcessedEventsQueue_;
// Queue to hold the events that have been processed
private final Queue<String> processedEventsQueue_;
// Queue to hold the events that have been pushed to downstream
// Think of this queue as it belongs to the downstream system
private final Queue<String> outputEventsQueue_;
public MultiThreadedStreamProcessor() {
// Initialize all queues
inputEventsQueue_ = new ConcurrentLinkedQueue<>();
unProcessedEventsQueue_ = new ConcurrentLinkedQueue<>();
processedEventsQueue_ = new ConcurrentLinkedQueue<>();
outputEventsQueue_ = new ConcurrentLinkedQueue<>();
// Initialize the threads
Thread eventPullerThread = new Thread(new EventPullerRunnable());
Thread eventProcessorThread = new Thread(new EventProcessorRunnable());
Thread eventPublisherThread = new Thread(new EventPublisherRunnable());
// Kick off all threads
eventPullerThread.start();
eventProcessorThread.start();
eventPublisherThread.start();
}
/**
* This runnable represents the work Event Puller thread will do
*/
private class EventPullerRunnable implements Runnable {
@Override
public void run() {
// If work appears in input events queue, pick it up and act on it.
while (true) {
if (!inputEventsQueue_.isEmpty()) {
String setName = inputEventsQueue_.poll();
pullFromUpstream(setName);
unProcessedEventsQueue_.add(setName);
}
}
}
private void pullFromUpstream(String setName) {
try {
System.out.println("Pulling " + setName);
Thread.sleep(250);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
/**
* This runnable represents the work Event Processor thread will do
*/
private class EventProcessorRunnable implements Runnable {
@Override
public void run() {
// If work appears in unprocessed events queue, pick it up and act on it.
while (true) {
if (!unProcessedEventsQueue_.isEmpty()) {
String setName = unProcessedEventsQueue_.poll();
processEvents(setName);
processedEventsQueue_.add(setName);
}
}
}
private void processEvents(String setName) {
try {
System.out.println("Processing " + setName);
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
/**
* This runnable represents the work done by Event Publisher thread
*/
private class EventPublisherRunnable implements Runnable {
// If work appears in processed events queue, pick it up and act on it.
@Override
public void run() {
while (true) {
if (!processedEventsQueue_.isEmpty()) {
String setName = processedEventsQueue_.poll();
pushToDownstream(setName);
outputEventsQueue_.add(setName);
}
}
}
private void pushToDownstream(String setName) {
try {
System.out.println("Publishing " + setName);
Thread.sleep(250);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
/**
* This method executes the end to end algorithm for consuming an event set.
* @param setName Name of the event set
*/
public void consumeAnEventSet(String setName) {
// All we have to do is submit the work to inputQueue.
// The threads are all running and will pick up the work as soon as they see it in the queue
inputEventsQueue_.add(setName);
}
/**
* Getter for output events queue.
* A caller can poll on this to know when all the work has been completed.
* @return the output events queue
*/
public Queue<String> getOutputEventsQueue() {
return outputEventsQueue_;
}
}
-The following code lets us measure the throughput of the pipelined implementation:
public class MultiThreadedStreamProcessorTest {
public static void main(String[] args) {
MultiThreadedStreamProcessor multiThreadedStreamProcessor = new MultiThreadedStreamProcessor();
long startTime = System.currentTimeMillis();
// Add inputs
int totalEventSets = 6;
for (int i = 0; i < totalEventSets; i++) {
multiThreadedStreamProcessor.consumeAnEventSet("set" + (i+1));
}
// Lets wait till all work is done
while (true) {
if (multiThreadedStreamProcessor.getOutputEventsQueue().size() == totalEventSets) {
System.out.println("all work has been completed");
break;
}
}
long endTime = System.currentTimeMillis();
System.out.println("Time taken :" + (endTime-startTime) + "ms" );
}
}
Output:
Pulling set1
Pulling set2
Processing set1
Pulling set3
Processing set2
Publishing set1
Pulling set4
Pulling set5
Processing set3
Publishing set2
Pulling set6
Processing set4
Publishing set3
Processing set5
Publishing set4
Publishing set5
Processing set6
Publishing set6
all work has been completed
Time taken :3545msThe above illustration shows how the pipelined implementation provides approximately 2x the throughput, 3.5 seconds, as compared to six seconds of the non-pipelined implementation.
Opinions expressed by DZone contributors are their own.
Comments