Three Performance Tricks for Dealing With Big Data Sets
This article describes three different tricks that I used in dealing with big data sets (order of 10 million records) and that proved to enhance performance dramatically.
Join the DZone community and get the full member experience.
Join For FreeThis article describes three different tricks that I used in dealing with big data sets (order of 10 million records), and that proved to enhance performance dramatically.
Trick 1: CLOB Instead of Result Set
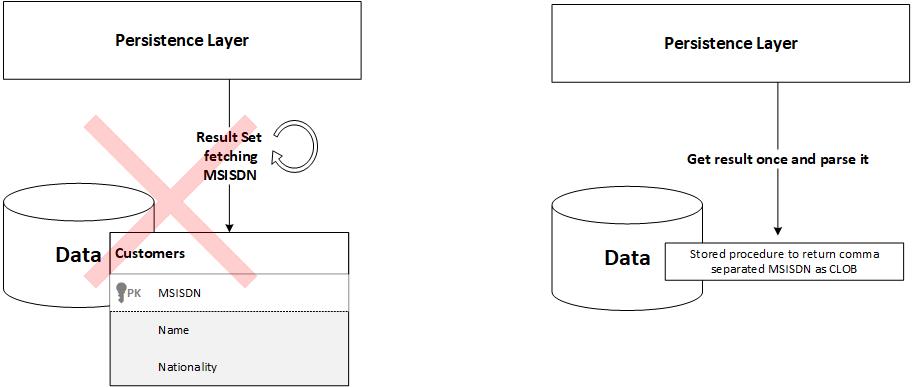
The use case here was that I had a big database table (~ 10 million records) that I needed to query on one column in it, but I needed to eventually get all data inside it; imagine a table containing millions of customers and in one use case, you need to get the mobile numbers (MSISDN) of all of them at once inside your application. The first thing I tried was the ordinary result set approach, where I open a result set and continue fetching the result until it finishes. However, this was too slow even with tuning all the available parameters (fetch size, concurrency, etc.), so I went to the idea here. I created a stored procedure to compose all the mobile numbers as comma-separated CLOB, then the query returns the CLOB once, and it is then parsed at the application level. This trick enhanced the performance dramatically.
Trick 2: Index Dropping for Bulk Update
The use case here is that I have a night job that updates a table with a bulk set of data (~10 million records). The table naturally has many indexes as many queries run against it. The point here is that bulk updates become very slow in case of having an index on the table because the index is being updated at the same time the data is updated; moreover, the index gets corrupted due to all these consecutive inserts. so the solution was to drop the indexes on the table first, make the bulk insertions, then rebuild the index again and execute the gather statistics command (as the database was Oracle). Again, the performance was enhanced to the magnitude of hours.
Trick 3: Using Mod Operation to Uniform Load Across Workers
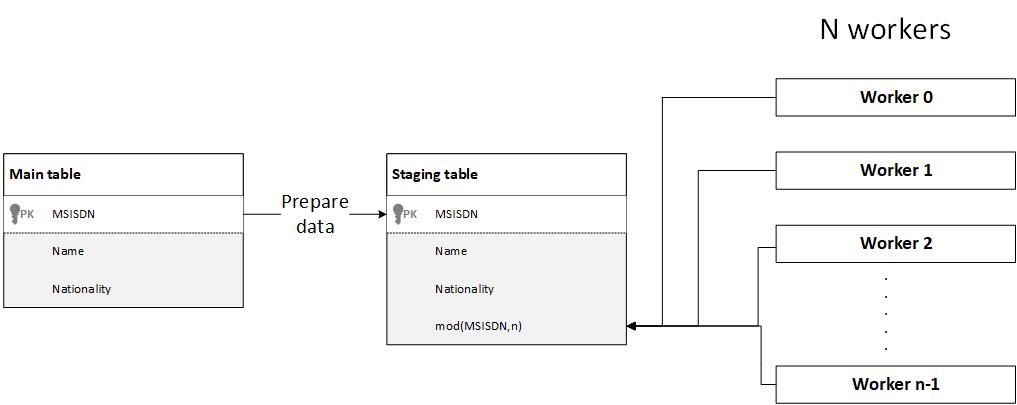
Generally, when you have a data-intensive application that you want to make reports on, process, or transfer a subset of its data to another application, the first step is data preparation, where the target data subject to report, query, or process is moved to a staging table as a preparation for the next step, the next step is usually starting processing the data on this temp table using multiple workers (threads), a common challenge here is how to distribute the workload across workers uniformly, i.e. assume that the staging table now has 10 million records that you will distribute their processing across 20 workers for performance and efficiency, the best scenario is that each one process 500k records, the worst scenario is that one worker process 10M records while the remaining 19 threads process zero records. So, how do we distribute the workload uniformly across workers?
There are multiple options here:
1. Depending on the total number of records in the table (count(1)) and divide it by the number of threads, then make an if condition to check if the worker quota is reached and accordingly quit:
//pseudo code
// var totalRecordsCount = select count(1) from STAGING_TABLE
// var workerQuota= totalRecordsCount /numberOfThreads
//while (numberOfProcessedRecords < workerQuota) {
//the processing logic }Clearly, you will need some logic to guarantee that there is no overlapping between workers on the data processed. This will add complexity to the code, impact the performance, and, finally, might not be accurate.
The code is not efficient.
2. Specify a range for each worker to process. For example, each worker will process the data of a certain hour or day, a certain range of SIDs, MSISDNs, part numbers, etc. (depending on your business).
//pseudo code
//open a cursor for records processing_date between(11AM, 12 PM)
// or SID between (0000000,00500000)
// or AGE between (10,15)
//etc ....The issue here clearly is that there is no guarantee for uniform load across workers unless the data has a very special uniform distribution over the selected field, which is generally not the case.
3-.The selected approach, which is a fine-tuning for the previous one, is to create an additional column in the staging table that should be populated during data preparation. The value in this column is mod(SOME_RANDOM_VALUED_COLUMN,noOfWorkingThreads) , to understand what this means. Usually, you will have some column that has numeric, random (or pseudo-random) values like SID, MSISDN, part number, voucher number, etc. So, applying the mod operation on such a column will result in numbers from 0 to noOfWorkingThreads-1 that are nearly uniformly distributed over the table. You can then make each of your n workers select its related rows by filtering on this column.
//pseudo code
//int threadId; //a sequence number that identifies the running thread, value ranges from 0 to noOfWorkingThreads-1
//cursor targetRows = select * from STAGING_TABLE where SID_MOD = threadIdThis solution guarantees no overlapping between workers, no table rows counting overhead, and no checking conditions, thus the best performance.
Opinions expressed by DZone contributors are their own.
Comments