Performance Engineering Powered by Machine Learning
Machine learning techniques can help predict performance problems, allowing teams to course correct.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Performance and Site Reliability Trend Report.
For more:
Read the Report
Software testing is straightforward — every input => known output. However, historically, a great deal of testing has been guesswork. We create user journeys, estimate load and think time, run tests, and compare the current result with the baseline. If we don't spot regressions, the build gets a thumbs up, and we move on. If there is a regression, back it goes. Most times, we already know the output even though it needs to be better defined — less ambiguous with clear boundaries of where a regression falls. Here is where machine learning (ML) systems and predictive analytics enter: to end ambiguity.
After tests finish, performance engineers do more than look at the result averages and means; they will look at percentages. For example, 10 percent of the slowest requests are caused by a system bug that creates a condition that always impacts speed.
We could manually correlate the properties available in the data; nevertheless, ML will link data properties quicker than you probably would. After determining the conditions that caused the 10 percent of bad requests, performance engineers can build test scenarios to reproduce the behavior. Running the test before and after the fix will assert that it's corrected.
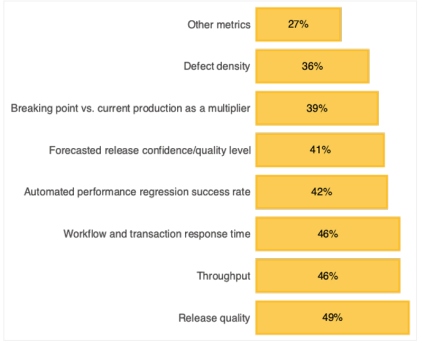
Figure 1: Overall confidence in performance metrics
Source: Data from TechBeacon
Performance With Machine Learning and Data Science
Machine learning helps software development evolve, making technology sturdier and better to meet users' needs in different domains and industries. We can expose cause-effect patterns by feeding data from the pipeline and environments into deep learning algorithms. Predictive analytics algorithms, paired with performance engineering methodologies, allow more efficient and faster throughput, offering insight into how end users will use the software in the wild and helping you reduce the probability of defects reaching production. By identifying issues and their causes early, you can make course corrections early in the development lifecycle and prevent an impact on production. You can draw on predictive analytics to improve your application performance in the following ways.
Identify root causes. You can focus on other areas needing attention using machine learning techniques to identify root causes for availability or performance problems. Predictive analytics can then analyze each cluster's various features, providing insights into the changes we need to make to reach the ideal performance and avoid bottlenecks.
Monitor application health. Performing real-time application monitoring using machine-learning techniques allows organizations to catch and respond to degradation promptly. Most applications rely on multiple services to get the complete application's status; predictive analytics models will correlate and analyze the data when the application is healthy to identify whether incoming data is an outlier.
Predict user load. We have relied on peak user traffic to size our infrastructure for the number of users accessing the application in the future. This approach has limitations as it does not consider changes or other unknown factors. Predictive analytics can help indicate the user load and better prepare to handle it, helping teams plan their infrastructure requirements and capacity utilization.
Predict outages before it's too late. Predicting application downtime or outages before they happen helps to take preventive action. The predictive analytics model will follow the previous outage breadcrumbs and continue monitoring for similar circumstances to predict future failures.
Stop looking at thresholds and start analyzing data. Observability and monitoring generate large amounts of data that can take up to several hundred megabytes a week. Even with modern analytic tools, you must know what you're looking for in advance. This leads to teams not looking directly at the data but instead setting thresholds as triggers for action. Even mature teams look for exceptions rather than diving into their data. To mitigate this, we integrate models with the available data sources. The models will then sift through the data and calculate the thresholds over time. Using this technique, where models are fed and aggregate historical data, provides thresholds based on seasonality rather than set by humans. Algorithm-set thresholds trigger fewer alerts; however, these are far more actionable and valuable.
Analyze and correlate across datasets. Your data is mostly time series, making it easier to look at a single variable over time. Many trends come from the interactions of multiple measures. For example, response time may drop only when various transactions are made simultaneously with the same target. For a human, that's almost impossible, but properly trained algorithms will spot these correlations.
The Importance of Data in Predictive Analytics
"Big data" often refers to datasets that are, well, big, come in at a fast pace, and are highly variable in content. Their analysis requires specialized methods so that we can extract patterns and information from them. Recently, improvements in storage, processors, parallelization of processes, and algorithm design enabled the processing of large quantities of data in a reasonable time, allowing wider use of these methods. And to get meaningful results, you must ensure the data is consistent.
For example, each project must use the same ranking system, so if one project uses 1 as critical and another uses 5 — like when people use DEFCON 5 when they mean DEFCON 1 — the values must be normalized before processing. Predictive algorithms are composed of the algorithm and the data it's fed, and software development generates immense amounts of data that, until recently, sat idle, waiting to be deleted. However, predictive analytics algorithms can process those files, for patterns we can't detect, to ask and answer questions based on that data, such as:
- Are we wasting time testing scenarios that aren't used?
- How do performance improvements correlate with user happiness?
- How long will it take to fix a specific defect?
These questions and their answers are what predictive analytics is used for — to better understand what is likely to happen.
The Algorithms
The other main component in predictive analysis is the algorithm; you'll want to select or implement it carefully. Starting simple is vital as models tend to grow in complexity, becoming more sensitive to changes in the input data and distorting predictions. They can solve two categories of problems: classification and regression (see Figure 2).
- Classification is used to forecast the result of a set by classifying it into categories starting by trying to infer labels from the input data like "down" or "up."
- Regression is used to forecast the result of a set when the output variable is a set of real values. It will process input data to predict, for example, the amount of memory used, the lines of code written by a developer, etc. The most used prediction models are neural networks, decision trees, and linear and logistic regression.
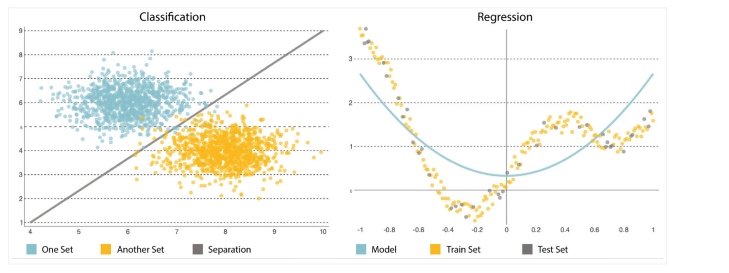
Figure 2: Classification vs. regression
Neural Networks
Neural networks learn by example and solve problems using historical and present data to forecast future values. Their architecture allows them to identify intricate relations lurking in the data in a way that replicates how our brain detects patterns. They contain many layers that accept data, compute predictions, and provide output as a single prediction.
Decision Trees
A decision tree is an analytics method that presents the results in a series of if/then choices to forecast specific options' potential risks and benefits. It can solve all classification problems and answer complex issues.
As shown in Figure 3, decision trees resemble an upsidedown tree produced by algorithms identifying various ways of splitting data into branch-like segments that illustrate a future decision and help to identify the decision path.
One branch in the tree might be users who abandoned the cart if it took more than three seconds to load. Below that one, another branch might indicate whether they identify as female. A "yes" answer would raise the risk as analytics show that females are more prone to impulse buys, and the delay creates a pause for pondering.
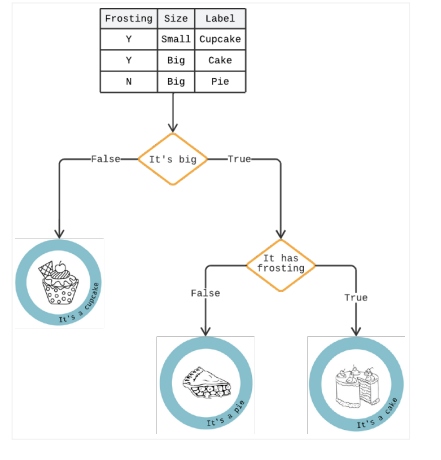
Figure 3: Decision tree example
Linear and Logistic Regression
Regression is one of the most popular statistical methods. It is crucial when estimating numerical numbers, such as how many resources per service we will need to add during Black Friday. Many regression algorithms are designed to estimate the relationship among variables, finding key patterns in big and mixed datasets and how they relate. It ranges from simple linear regression models, which calculate a straight-line function that fits the data, to logistic regression, which calculates a curve (Figure 4).
| OVERVIEW OF LINEAR AND LOGISTIC REGRESSION | |
|---|---|
| Linear Regression | Logistic Regression |
| Used to define a value on a continuous range, such as the risk of user traffic peaks in the following months. | It's a statistical method where the parameters are predicted based on older sets. It best suits binary classification: datasets where y = 0 or 1, where 1 represents the default class. Its name derives from its transformation function being a logistic function. |
| It's expressed as y = a + bx, where x is an input set used to determine the output y. Coefficients a and b are used to quantify the relation between x and y, where a is the intercept and b is the slope of the line. | It's expressed by the logistic function: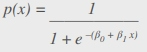 where β0 is the intercept and β1 is the rate. It uses training data to calculate the coefficients, minimizing the error between the predicted and actual outcomes. where β0 is the intercept and β1 is the rate. It uses training data to calculate the coefficients, minimizing the error between the predicted and actual outcomes. |
| The goal is to fit a line nearest to most points, reducing the distance or error between y and the line. | It forms an S-shaped curve where a threshold is applied to transform the probability into a binary classification. |
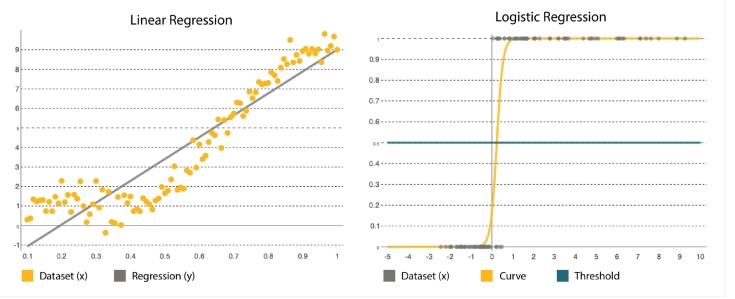
Figure 4: Linear regression vs. logistic regression
These are supervised learning methods, as the algorithm solves for a specific property. Unsupervised learning is used when you don't have a particular outcome in mind but want to identify possible patterns or trends. In this case, the model will analyze as many combinations of features as possible to find correlations from which humans can act.
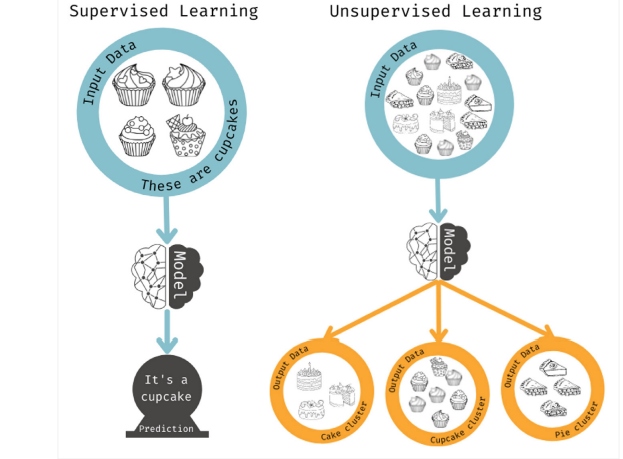
Figure 5: Supervised vs. unsupervised learning
Shifting Left in Performance Engineering
Using the previous algorithms to gauge consumer sentiment on products and applications makes performance engineering more consumer-centric. After all the information is collected, it must be stored and analyzed through appropriate tools and algorithms. This data can include error logs, test cases, test results, production incidents, application log files, project documentation, event logs, tracing, and more. We can then apply it to the data to get various insights to:
- Analyze defects in environments
- Estimate the impact on customer experience
- Identify issue patterns
- Create more accurate test scenarios, and much more
This technique supports the shift-left approach in quality, allowing you to predict how long it will take to do performance testing, how many defects you are likely to identify, and how many defects might make it to production, achieving better coverage from performance tests and creating realistic user journeys. Issues such as usability, compatibility, performance, and security are prevented and corrected without impacting users.
Here are some examples of information that will improve quality:
- Type of defect
- In what phase was the defect identified
- What the root cause of the defect is
- Whether the defect is reproducible
Once you understand this, you can make changes and create tests to prevent similar issues sooner.
Conclusion
Software engineers have made hundreds and thousands of assumptions since the dawn of programming. But digital users are now more aware and have a lower tolerance for bugs and failures. Businesses are also competing to deliver a more engaging and flawless user experience through tailored services and complex software that is becoming more difficult to test.
Today, everything needs to work seamlessly and support all popular browsers, mobile devices, and apps. A crash of even a few minutes can cause a loss of thousands or millions of dollars. To prevent issues, teams must incorporate observability solutions and user experience throughout the software lifecycle. Managing the quality and performance of complex systems requires more than simply executing test cases and running load tests. Trends help you tell if a situation is under control, getting better, or worsening — and how fast it improves or worsens. Machine learning techniques can help predict performance problems, allowing teams to course correct. To quote Benjamin Franklin, "An ounce of prevention is worth a pound of cure."
This is an article from DZone's 2022 Performance and Site Reliability Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments