An Introduction To Open Table Formats
Path to performant, cost-effective, efficient data lakehouse enabling more intelligent interaction between storage and compute engines.
Join the DZone community and get the full member experience.
Join For FreeThe evolution of data management architectures from warehouses to lakes and now to lakehouses represents a significant shift in how businesses handle large datasets. The data lakehouse model combines the best of both worlds, offering the cost-effectiveness and flexibility of data lakes with the robust functionality of data warehouses. This is achieved through innovative table formats that provide a metadata layer, enabling more intelligent interaction between storage and compute resources.
How Did We Get to Open Table Formats?
Hive: The Original Table Format
Running analytics on Hadoop data lakes initially required complex Java jobs using the MapReduce framework, which was not user-friendly for many analysts. To address this, Facebook developed Hive in 2009, allowing users to write SQL instead of MapReduce jobs.
Hive converts SQL statements into executable MapReduce jobs. It introduced the Hive table format and Hive Metastore to track tables. A table is defined as all files within a specified directory (or prefixes for object storage), with partitions as subdirectories. The Hive Metastore tracks these directory paths, enabling query engines to locate the relevant data.
Benefits of the Hive Table Format
- Efficient queries: Techniques like partitioning and bucketing enabled faster queries by avoiding full table scans.
- File format agnostic: Supported various file formats (e.g., Apache Parquet, Avro, CSV/TSV) without requiring data transformation.
- Atomic changes: Allowed atomic changes to individual partitions via the Hive Metastore.
- Standardization: Became the de facto standard, compatible with most data tools.
Limitations of the Hive Table Format
- Inefficient file-level changes: No mechanism for atomic file swaps, only partition-level updates.
- Lack of multi-partition transactions: No support for atomic updates across multiple partitions, leading to potential data inconsistencies.
- Concurrent updates: Limited support for concurrent updates, especially with non-Hive tools.
- Slow query performance: Time-consuming file and directory listings slowed down queries.
- Partitioning challenges: Derived partition columns could lead to full table scans if not properly filtered.
- Inconsistent table statistics: Asynchronous jobs often result in outdated or unavailable table statistics, hindering query optimization.
- Object storage throttling: Performance issues with large numbers of files in a single partition due to object storage throttling.
As datasets and use cases grew, these limitations highlighted the need for newer table formats.
Modern table formats offer key improvements over the Hive table format:
- ACID transactions: Ensure transactions are fully completed or canceled, unlike legacy formats.
- Concurrent writers: Safely handle multiple writers, maintaining data consistency.
- Enhanced statistics: Provide better table statistics and metadata, enabling more efficient query planning and reduced file scanning.
With that context, this document explores the popular Open Table Format: Apache Iceberg.
What Is Apache Iceberg?
Apache Iceberg is a table format created in 2017 by Netflix to address performance and consistency issues with the Hive table format. It became open source in 2018 and is now supported by many organizations, including Apple, AWS, and LinkedIn. Netflix identified that tracking tables as directories limited consistency and concurrency. They developed Iceberg with goals of:
- Consistency: Ensuring atomic updates across partitions.
- Performance: Reducing query planning time by avoiding excessive file listings.
- Ease of use: Providing intuitive partitioning without requiring knowledge of physical table structure.
- Evolvability: Allowing safe schema and partitioning updates without rewriting the entire table.
- Scalability: Supporting petabyte-scale data.
Iceberg defines tables as a canonical list of files, not directories, and includes support libraries for integration with compute engines like Apache Spark and Apache Flink.
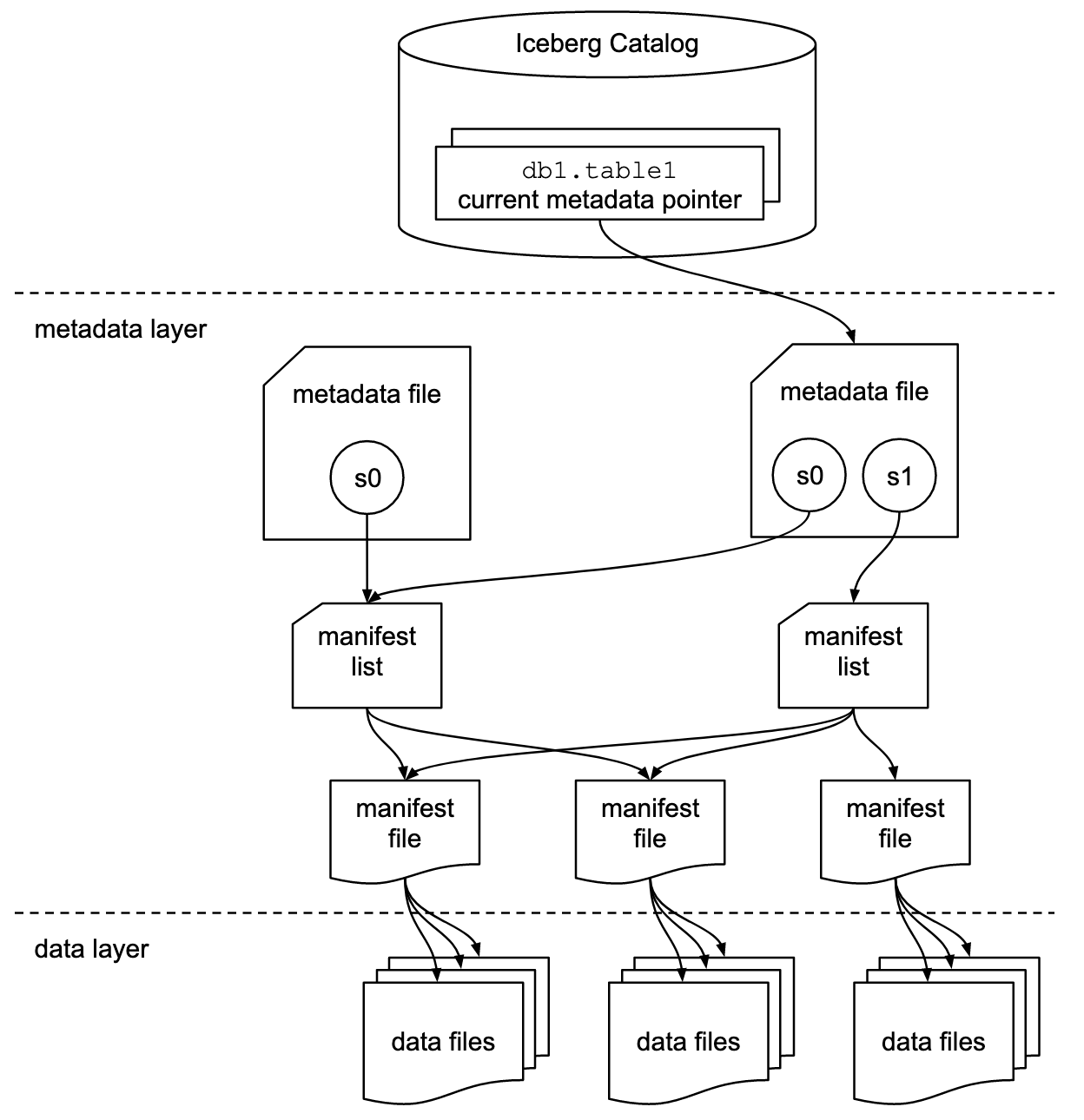
Metadata Tree Components in Apache Iceberg
- Manifest file: Lists data files with their locations and key metadata for efficient execution plans.
- Manifest list: Defines a table snapshot as a list of manifest files with statistics for efficient execution plans.
- Metadata file: Defines the table’s structure, including schema, partitioning, and snapshots.
- Catalog: Tracks the table location, mapping table names to the latest metadata file, similar to the Hive Metastore. Various tools, including the Hive Metastore, can serve as a catalog.
Key Features
ACID Transactions
Apache Iceberg uses optimistic concurrency control to ensure ACID guarantees, even with multiple readers and writers. This approach assumes transactions won’t conflict and checks for conflicts only when necessary, minimizing locking and improving performance. Transactions either commit fully or fail, with no partial states.
Concurrency guarantees are managed by the catalog, which has built-in ACID guarantees, ensuring atomic transactions and data correctness. Without this, conflicting updates from different systems could lead to data loss. A pessimistic concurrency model, which uses locks to prevent conflicts, may be added in the future.
Partition Evolution
Before Apache Iceberg, changing a table’s partitioning often required rewriting the entire table, which was costly at scale. Alternatively, sticking with the existing partitioning sacrificed performance improvements.
With Apache Iceberg, you can update the table’s partitioning without rewriting the data. Since partitioning is metadata-driven, changes are quick and inexpensive. For example, a table initially partitioned by month can evolve to day partitions, with new data written in day partitions and queries planned accordingly.
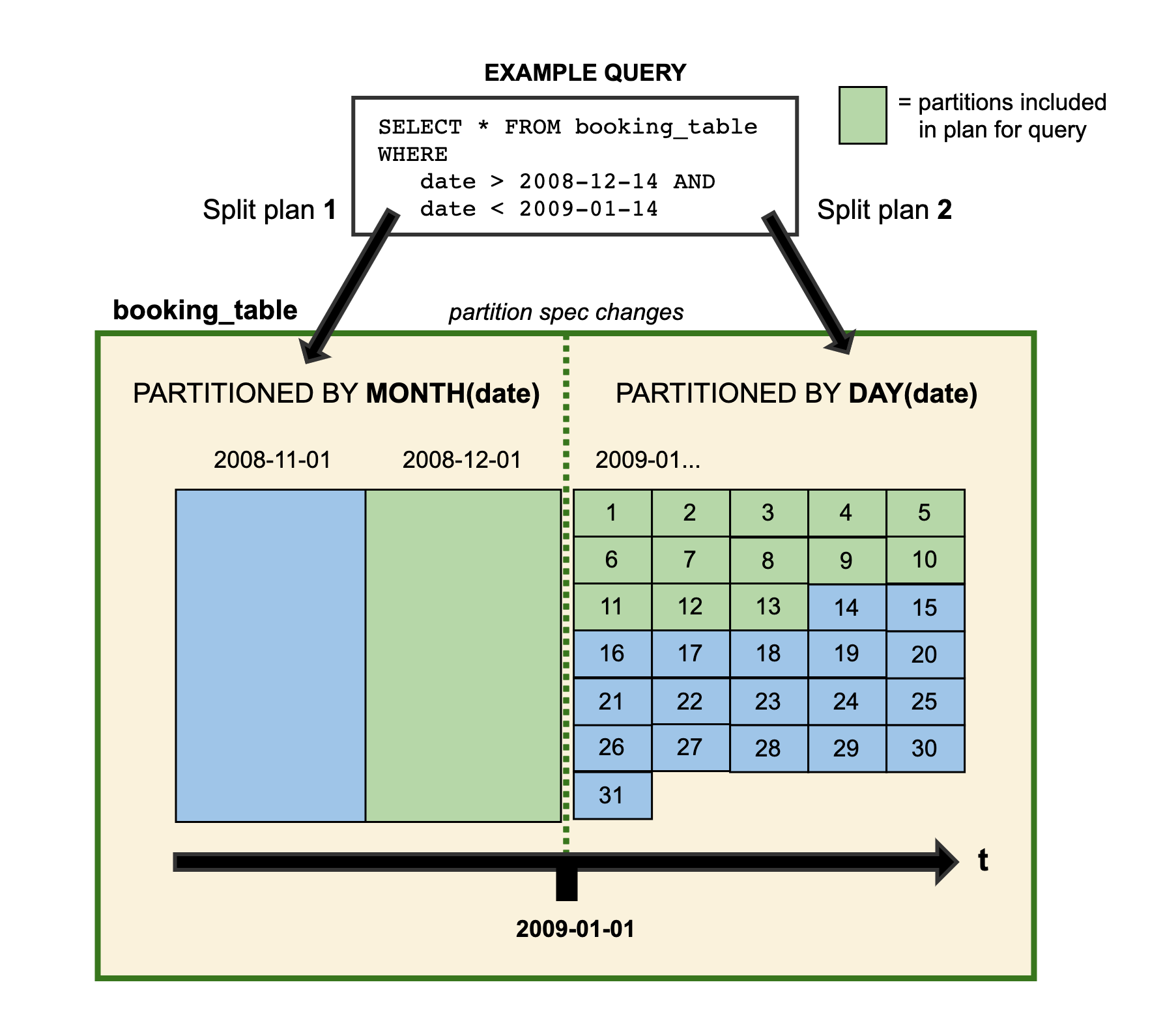
Hidden Partitioning
Users often don’t know or need to know how a table is physically partitioned. For example, querying by a timestamp field might seem intuitive, but if the table is partitioned by event_year, event_month, and event_day, it can lead to a full table scan.
Apache Iceberg solves this by allowing partitioning based on a column and an optional transform (e.g., bucket, truncate, year, month, day, hour). This eliminates the need for extra partitioning columns, making queries more intuitive and efficient.
In the figure below, assuming the table uses day partitioning, the query would result in a full table scan in Hive due to a separate “day” column for partitioning. In Iceberg, the metadata tracks the partitioning as “the transformed value of CURRENT_DATE,” allowing the query to use the partitioning when filtering by CURRENT_DATE.
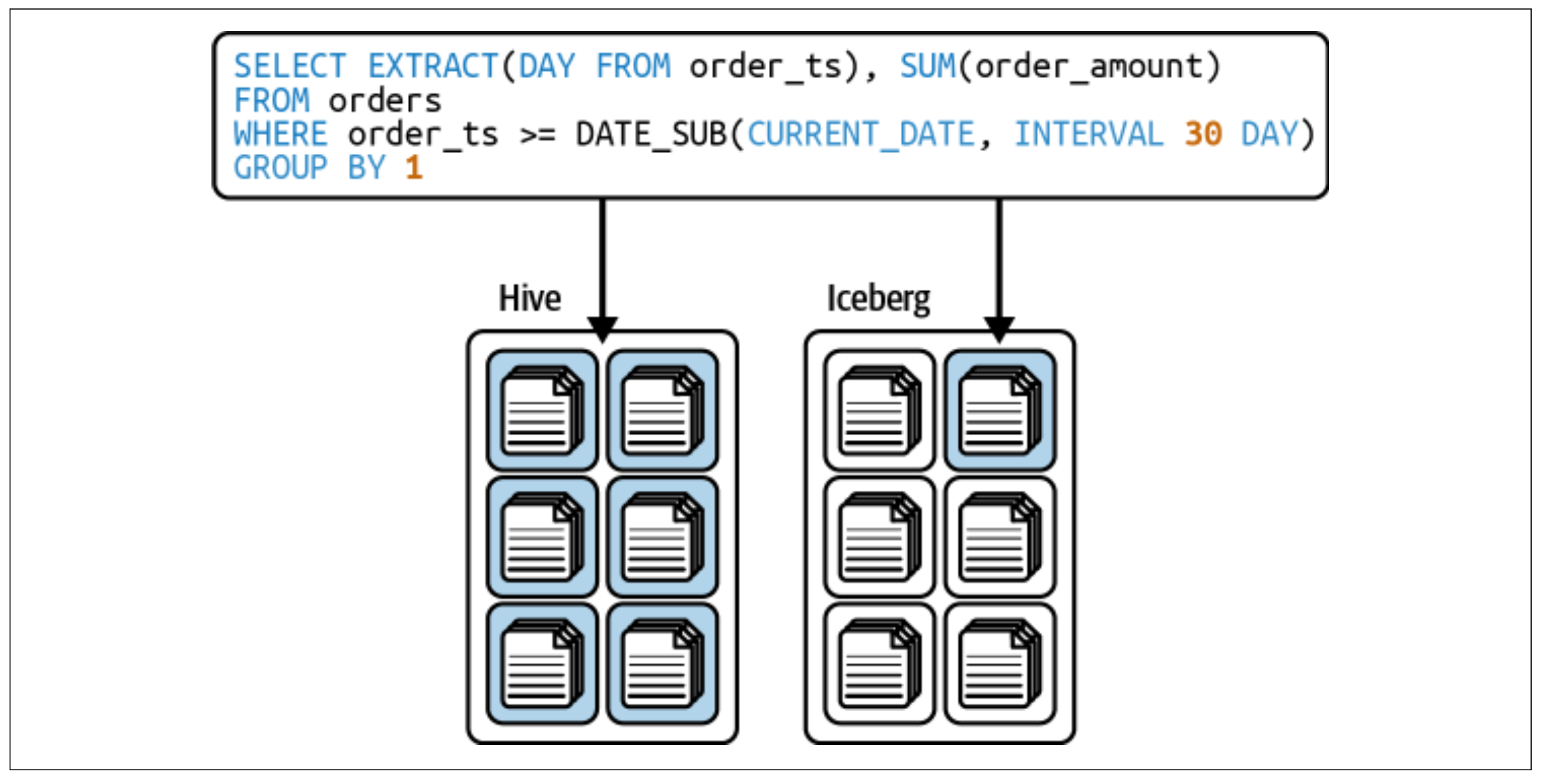
Time Travel
Apache Iceberg offers immutable snapshots, enabling queries on the table’s historical state, known as time travel. This is useful for tasks like end-of-quarter reporting or reproducing ML model outputs at a specific point in time, without duplicating data.
Version Rollback
Iceberg’s snapshot isolation allows querying data as it is and reverting the table to any previous snapshot, making it easy to undo mistakes.
Schema Evolution
Iceberg supports robust schema evolution, enabling changes like adding/removing columns, renaming columns, or changing data types (e.g., updating an int column to a long column).
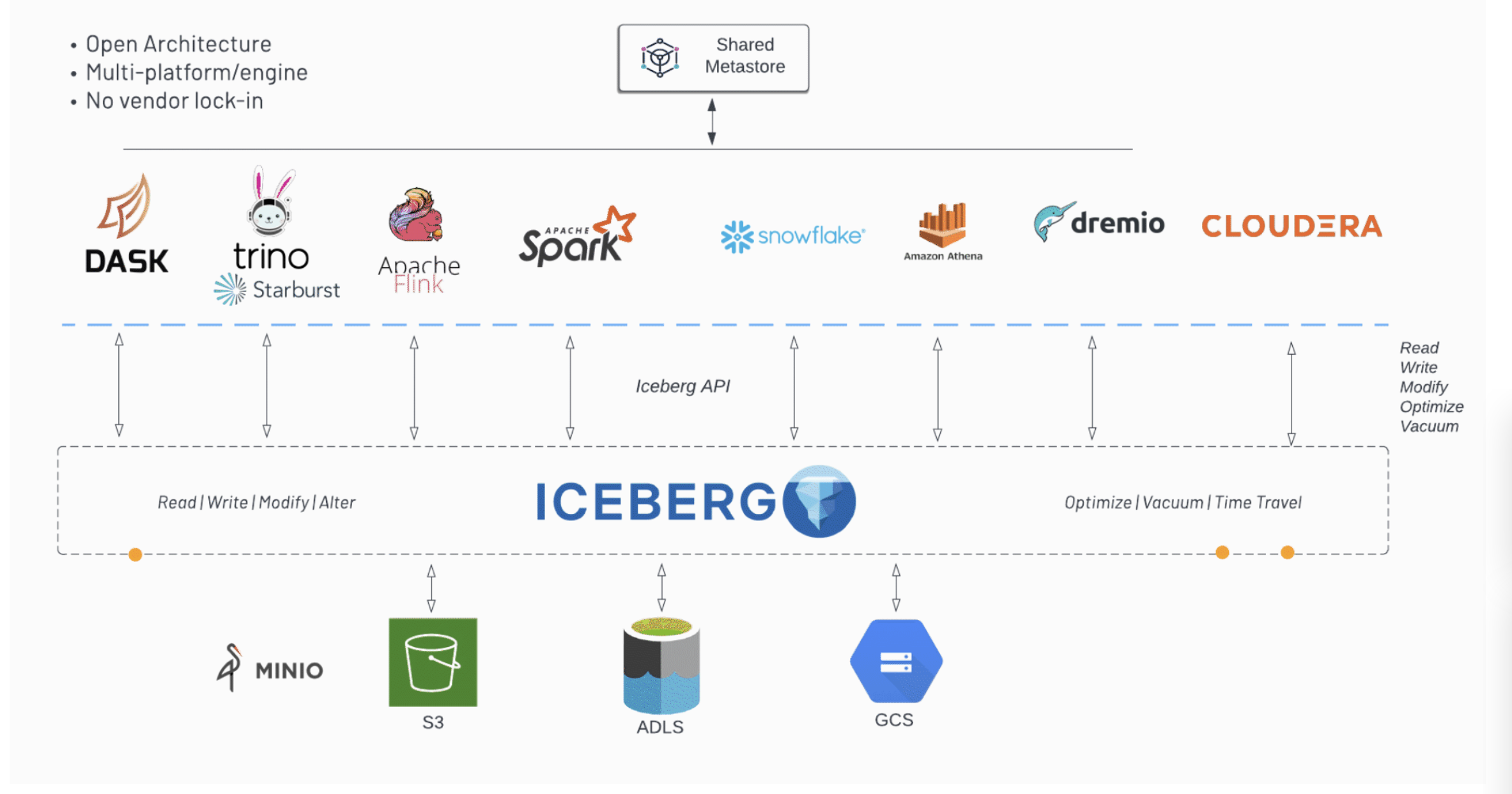
Adoption
One of the best things about Iceberg is its vast adoption by many different engines. In the diagram below, you can see many different technologies can work with the same set of data as long as they use the open-source Iceberg API. As you can see, the popularity and work that each engine has done is a great indicator of the popularity and usefulness that this exciting technology brings.
Conclusion
This post covered the evolution of data management towards data lakehouses, the key issues addressed by open table formats, and an introduction to the high-level architecture of Apache Iceberg, a leading open table format.
Opinions expressed by DZone contributors are their own.
Comments