Understanding Multi-Leader Replication for Distributed Data
In this article, learn about the advantages, practical use cases, and topologies of multi-leader database replication, as well as its pros and cons for scalability.
Join the DZone community and get the full member experience.
Join For FreeDatabase replication is a fundamental strategy for handling the demands of distributed systems. Replicating data is a topic that ranges back to the 1970s. To replicate means to keep a copy of the same data on multiple nodes.
Multi-leader replication is particularly useful for a range of use cases. This article starts with a sample of use cases for multi-leader replication. I will then highlight the pros and cons of multi-leader replication for different topologies and summarize them in a table.
Sample Use Cases
Multi-leader data replication can be used for edge computing, multi-tenant SaaS platforms, and write-intensive applications with distributed users, among others. Let's have a closer look:
Edge Computing
Edge devices and edge data centers can write data locally. Multi-leader replication can ensure updates propagate across the network for consistency. Distributed locations with latency sensitivity, intermittent connectivity, high write availability, resource scarcity, data sovereignty and compliance, redundancy, and fault tolerance can all be addressed by multi-leader replication. Regional leaders can store and process data locally to comply with sovereignty laws. Data synchronization can occur for non-restricted data fields or anonymized datasets. Asynchronously distributing the propagation of updates across leaders can reduce the load on any single node and conserve computing, storage, and network resources.
Multi-Tenant SaaS Platforms
Multi-leader replication can support multi-tenant architectures by enabling independent writes for each tenant while maintaining synchronization. Multiple customers or organizations (tenants) may share the same application infrastructure but require logically isolated data and functionality. Data can be separated per organization but with shared global consistency.
Write-Intensive Applications With Distributed Users
Consider applications like stock trading platforms, where traders write transactions at multiple entry points, or distributed supply chain management systems. Multi-leader replication can distribute the write load across nodes, enhancing scalability and performance.
Why Use Multi-Leader Replication?
This article focuses on the support to multi-datacenter architectures. Supporting such architectures by multi-leader replication is based on the following:
Avoiding Single Points of Failure
A traditional banking system with a single central database is vulnerable to single points of failure. If the primary database goes down, the entire system becomes inaccessible. By using multi-leader replication, if one data center experiences an outage, other data centers can still process transactions. This way, services like online banking can remain available to customers.
Workload Isolation
Each datacenter can handle its operations independently without depending on other datacenters for every transaction. By processing requests locally, the need to communicate with remote datacenters for every read or write operation is reduced. This minimizes latency and boosts performance. Issues in one datacenter, such as hardware failures or local network outages, do not immediately impact the functionality of others. Consider, for example, the case of local writes. Multi-leader systems allow each datacenter to serve as a leader node. This means that local clients (users) can write directly to their nearest datacenter. This significantly reduces write latency, as data does not have to traverse long geographical distances before being acknowledged. In simpler terms, when users are spread across different regions, having multiple leaders in various locations ensures that data is closer to the users. This reduces the time it takes for data to travel between the user and the server.
Cross-Datacenter Synchronization
Changes made in one datacenter are asynchronously propagated to other datacenters. Different consistency models across the system can be enforced this way. While writes are handled locally, global synchronization ensures that all datacenters converge to the same state over time.
Scalability
By scaling horizontally, we can add more nodes to a cluster. The system can handle increased workloads since multiple nodes can process reads and writes concurrently.
Multi-Leader Replication Topologies
In multi-leader replication, multiple nodes can handle write requests simultaneously. Each leader can independently process writes and propagate those changes to other nodes in the system. Essentially, every leader is also a follower to the other leaders.
To understand multi-leader replication, we must analyze the different replication topologies. Each topology offers a different path along which writes are propagated from one node to another. Table 1 summarises the pros and cons of each topology, and it also includes a number of commercial databases that we've used per topology. It should be mentioned that many commercial databases can be used for more than one topologies and the table is not restrictive. The table just highlights our choices based on cost, complexity and technical expertise.
Also, it is worth mentioning that commercial databases can employ hybrid topologies, combining aspects from each topology and balancing trade-offs. However, to clarify basic concepts, the categorization in Table 1 is based on three basic topologies.
| Topology | Pros | Cons | Example databases |
| Circular (Ring) | Simple implementation Predictable network traffic Lower bandwidth requirements Clear replication path |
Single point of failure Long replication paths Higher write latency Limited fault tolerance Potential for replication loops Complex recovery after node failure |
MySQL Circular Replication MariaDB Galera Cluster PostgreSQL with pglogical Amazon Aurora (modified ring) |
| Star (Hub and Spoke) | Centralized management Simplified monitoring Simpler conflict resolution |
Single point of failure Limited scalability Centralization bottlenecks |
Oracle Advanced Replication SQL Server Publisher/Subscriber Azure SQL Database geo-replication |
| All-to-All (Mesh) | High availability Low propagation latency Load distribution |
Complex conflict resolution Communication complexity Security complexity |
MongoDB CouchDB NuoDB |
Table 1: Multi-leader replication topology comparison
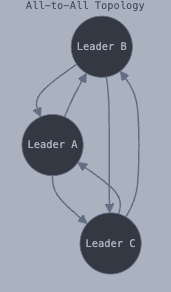
All-to-All Topology (Full-Mesh)
As shown in Figure 1, every leader sends its writes to every other leader. Every node can read and write data, acting as both a data producer and consumer. Any update made on a node is directly propagated to every other node, ensuring that all nodes stay synchronized via a direct replication link.
Pros
- High availability: There is no single point of failure since the failure of one node does not disrupt communication between the remaining nodes. Unlike topologies that rely on central nodes or specific communication paths, the full mesh topology ensures that every node serves as both a potential data source and a backup mechanism. This means that if any single node fails, the entire system can continue functioning without interruption. This is because multiple alternative paths exist for data transmission and recovery.
- Low propagation latency: Updates made on any node are sent to all other nodes via direct links. This direct communication eliminates intermediary nodes, enabling rapid data synchronization.
- Load distribution: The load of reads/writes can be distributed across multiple nodes, improving performance. Since every node holds a full copy of the dataset, read requests can be directed to any available node. This allows the system to balance read traffic across all nodes, reducing the chance of any single node becoming a bottleneck. Writes, on the other hand, are distributed across nodes based on factors like geographic proximity, user preferences, and application logic.
Cons
- Complex conflict resolution: In an all-to-all database topology, conflict resolution becomes complex because every node can simultaneously process write operations. When multiple nodes attempt to update the same data element at nearly identical moments, traditional sequential processing mechanisms break down. Each node generates its own version of the data, creating a multidimensional version space where determining the "correct" or "authoritative" version can become a sophisticated computational problem.
- Communication complexity: For n nodes, each node needs to maintain n-1 direct connections to other nodes. The total number of connections across the network simplifies to O(n²). As the number of nodes increases, the added complexity may not justify the expected gains. This is because more nodes increase the processing load on individual nodes. This is particularly true as conflict resolution and consistency mechanisms scale with the number of connections. Also, with more nodes participating in direct communication, contention for network resources and the increased overhead in managing connections can result in slower response times and reduced throughput.
- Security and vulnerability complexity: More connections imply more complex authentication, encryption and security requirements. There is an increased attack surface for potential security vulnerabilities. This can result in higher complexity in implementing secure communication channels between nodes.
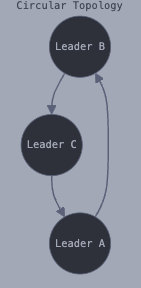
Circular Topology (Ring)
Each leader node communicates with only two other nodes, forming a circular (ring) structure, as shown in Figure 2. Changes propagate around the ring in a unidirectional or bidirectional flow, depending on the configuration. Each leader node receives writes from one node and forwards those writes (plus any writes of its own) to one other node.
Pros
- Connection simplicity: Each node is connected to just two neighboring nodes. This minimizes the connection complexity. Unlike in mesh topologies, where each node might need to maintain numerous connections, the ring topology reduces overhead in connection management. One potential benefit is lower resource consumption. This setup benefits systems where minimal connectivity is preferred to reduce resource strain.
- Efficient propagation: Data updates in a ring topology follow a structured, predictable path, so network traffic is manageable and avoids the flood of simultaneous data replication seen in other topologies. The consistency of the data propagation path can simplify network management. It is easier to track the status and latency of data transfers. This is particularly useful for applications where updates can be allowed to propagate gradually without requiring instant synchronization.
- Scalability: The ring topology is generally more scalable than a full mesh, where every additional node greatly increases the number of required connections. In a ring, new nodes simply connect to their two closest neighbors. This way, adding capacity is straightforward. This topology works well for systems expected to grow gradually, as nodes can be added with minimal reconfiguration.
- Good for linear data flows: The ring topology is suitable for applications that process data sequentially, where each node processes data and passes it along to the next. Linear or sequential processing tasks benefit greatly from this setup. For example, in a chain of transformations or aggregations, each node can perform its operation and hand off the results to the next.
Cons
- High latency in large rings: Because each update has to pass through each node sequentially, latency can increase significantly as the ring grows. The time it takes for an update to reach a distant node in the ring can be problematic for applications that rely on low-latency, near-instantaneous data updates. This issue becomes more pronounced in large rings or systems that require frequent updates. This is where the cumulative delay of each hop adds up and impacts the overall responsiveness.
- Single-node dependency: The entire data flow is interrupted if one node fails in a unidirectional ring. A bidirectional ring configuration helps mitigate this risk but adds complexity. In a unidirectional ring, each node depends entirely on its neighbors for communication and data replication. A single point of failure can halt data flow completely, disrupting operations. This vulnerability makes ring topologies less reliable for applications that demand high availability and fault tolerance.
- Replication loops: In bidirectional rings or systems with poorly managed replication controls, data can circulate in loops. This causes redundant data transfer and additional latency. Replication loops create unnecessary network traffic and consume bandwidth without providing additional data consistency. Careful control mechanisms are needed to prevent this problem. Such loops can increase the configuration and monitoring burden on administrators.
- Complex recovery after node failure: When a node fails, reintegrating it or adding a new node to replace it can be complex, often requiring substantial reconfiguration. This is because the data and communication paths must be adjusted. The sequential design of the ring topology makes it sensitive to changes. This may involve re-synchronizing data across multiple nodes.
- Higher write latency: Writes take longer to propagate through the entire ring. This is because each write must be replicated node-by-node in sequence, which delays full data consistency. In write-heavy applications, this latency becomes a bottleneck. Each update must wait for the previous one to be replicated. This is particularly limiting in applications requiring fast, consistent access to updated data across all nodes. It introduces delays for each node to achieve the latest data state.
Star Topology
A designated root node (a central leader node) forwards write to all other nodes. The central leader node acts as a hub, with satellite leaders connecting directly to it. This leads to a star topology, as shown in Figure 3, that can also be generalized to a tree topology.

Pros
- Simplicity: Since all nodes connect directly to a central hub, each node only has to manage a single connection. This reduces network complexity and simplifies configuration. This also means fewer connections to maintain, lowering both setup and maintenance costs.
- Efficient propagation: The central hub node is the distribution point that can manage and enforce update ordering. It is easy to avoid or resolve conflicts this way. This centralization can also simplify version control.
- Centralized management and monitoring: The hub node can serve as a monitoring point for the entire network. It can be used to track node health, replication lag, and network stability. It can also be used for configuration, maintenance, and backup processes. This setup reduces the need for extensive, distributed monitoring and management systems.
- Direct replication paths: With each node directly connected to the hub, the star topology ensures that data propagation happens in predictable, direct paths. This makes troubleshooting simpler, as issues in replication paths are usually easier to detect and address.
Cons
- Single-node dependency: The hub is a critical point in the star topology; if it fails, the entire network suffers. This centralization introduces a major risk because all replication depends on the hub’s functionality. Failover and backup solutions are essential to mitigate this vulnerability. The reliance of each satellite node on the hub can create a fragile system. If satellite nodes cannot communicate with the hub, they might be unable to access updated data, leading to inconsistencies and downtime.
- Limited scalability: Although the star topology scales better than a full mesh, it also has limits. As the number of nodes grows, the hub must handle increased replication traffic, which can push its hardware limits. To avoid this bottleneck, hubs need to be designed with scalable hardware, and additional hubs may be required for larger setups.
- Centralization bottlenecks: As the hub manages all data distribution and communication, it can become a bottleneck under high traffic. Performance degradation is an issue as this load can strain the central node’s resources (e.g., CPU, memory, network bandwidth). As an example, we can consider network congestion as all data must pass through the hub. High levels of traffic can slow down replication times. This may lead to replication lag, especially in geographically distributed networks where network latency adds to the load on the central node.
Synchronous, Semi-Synchronous, and Asynchronous
In synchronous replication, a leader waits for a response from a follower. In asynchronous replication, a leader does not wait for a response from a follower.
The main benefit of synchronous replication is that the follower always has a current, consistent copy of the data matching the leader. If the leader experiences a sudden failure, data remains accessible to the follower. However, a key drawback arises if the synchronous follower is unresponsive. For example, if there is a crash or network issue, the leader is forced to halt any new writes and wait until the follower becomes available again before proceeding. This way, a single node outage could halt the entire system.
To alleviate halts, there are cases where enabling synchronous replication implies that one of the followers is synchronous and the others are asynchronous. This is also known as semi-synchronous replication. If the synchronous follower becomes unavailable or slow, one of the asynchronous followers is made synchronous. This way, we have an up-to-date copy of the data for the leader and one synchronous follower.
Multi-leader replication systems usually process writes concurrently on multiple nodes and asynchronously replicate them to other nodes. This can reduce the latency for write operations and improve system throughput and responsiveness. Since each leader can operate semi-independently without waiting for synchronous confirmations, clients do not have to wait for confirmation from multiple leaders. However, if a leader fails and is not recoverable, any writes that have not been replicated to followers are lost.
Problematic Features in Multi-Leader Setups
Three basic features that may cause problems in multi-leader set-ups include integrity constraints, triggers, and auto-incrementing keys. Let's have a closer look:
Integrity Constraints
Constraints like foreign keys, unique constraints, and primary keys are often designed to maintain data integrity. However, in a multi-leader replication setup, maintaining these constraints across multiple leaders can be challenging. For example, concurrent updates may violate these constraints. Foreign key constraints might fail due to replication delays. Conflict resolution mechanisms may discard updates required to satisfy constraints.
Triggers
Database triggers are automatically executed in response to certain events (like inserts, updates, or deletes). When the same operation occurs simultaneously on different leaders, conflicts between triggers may occur. For example, node A updates a record, which activates a trigger to update related data. The update is propagated to Node B, where the same trigger executes again. In effect, the update is sent back to Node A, continuing the loop indefinitely. If triggers involve multiple related tables or cascade updates, a simple change at one leader node can lead to cascading conflicts at others.
Auto-Incrementing Keys
Each leader may generate its own auto-incrementing keys. This may potentially create primary key collisions. Auto-incrementing keys assume a single source of truth. When this assumption is broken in multi-leader replication, the lack of a centralized counter increases the risk of conflicts. The need for distributed coordination may undermine the performance benefits of decentralization. Collision resolution mechanisms may add complexity, increasing operational costs and risks for errors.
Wrapping Up
Multi-leader data replication is not a panacea. As we add more and more leaders, the added complexity may not justify the expected gains. It's an alternative to other replication types like single-leader replication and leaderless replication. In fact, multi-leader replication is a solution to the problem of unresponsive leaders in single-leader replication systems. If a leader is unresponsive in single-leader replication, then we cannot write to the database. This is an obstacle that can be avoided if we have multiple leaders.
This article analyzed three basic multi-leader replication topologies. We've gone through their pros and cons and highlighted some commercial databases that we've used per topology. There exist other topologies that are beyond our scope like, for example, the master-master with witnesses topology that is designed to balance fault tolerance, operational efficiency, and data consistency. New topologies are also expected, either as hybrid combinations of the ones analyzed or as innovative new ideas, as the demand for data replication increases.
Data replication is rarely used on its own and it is often used in parallel with database partitioning. Although the focus on this article is on a specific kind of data replication, database partitioning is a topic that requires attention on its own. I hope that this article can serve as a basis to understand and navigate the hybrid combinations of multi-leader data replication topologies that exist out there.
Opinions expressed by DZone contributors are their own.
Comments