Model Cards and the Importance of Standardized Documentation for Explaining Models
Building on Google's work, here are some suggestions on how to create effective documentation to make models open, accessible, and understandable to all teams.
Join the DZone community and get the full member experience.
Join For FreeDocumentation is officially defined as material that provides official information or evidence that serves as a record. From a machine learning perspective, particularly with regard to a deployed model in a production environment, documentation should serve as notes and descriptions to help us understand the model in its entirety. Ultimately, effective documentation makes our models understandable to the many stakeholders we interact with.
Whether we are deploying low-impact models serving basic and non-sensitive needs or high-impact models with significant outcomes, such as loan approvals, we have a responsibility to be transparent—not just to our end users, but to our internal stakeholders. Furthermore, it shouldn’t just be the data scientists who hold all knowledge underpinning a model—it should be open, accessible, and understandable to anyone.
One Document To Rule Them All
Of course, documentation is needed by various teams for different reasons. As an experiment, I asked colleagues what they needed documentation for.
My fellow data scientists said they needed in-line code documentation so that they could better understand it if they needed to take over the codebase. They also said they needed records of performance metrics and logs of datasets and feature sets so they could reproduce experiments, replicating model parameters and hyperparameters.
Product teams said they wanted to understand the business use case and how to get in contact with the data scientists and developers that built the models or applications, as they need to know information about feature sensitivity and be able to answer client questions.
Legal teams said they wanted to understand things like fairness and bias, i.e., the methodology used that will ensure models are sustainable long-term when it comes to delivering fair outcomes. The ability to document if Personal Identifiable Information (PII) is used within a model, and its corresponding permissions, is also essential.
Providing the right information in a user-friendly way to teams that vary in technical understanding and capabilities and have different requirements of information is a significant challenge.
In my team, we have a GitHub repository synced with our Databricks environment containing scripts for our pipelines and workflows. We keep a standardized README template that outlines a model’s purpose, developer information, the model’s architecture, paper references, and the product teams that the model serves. Additionally, we track and document data science conversations across a model’s development, from ideas to Q&A, to model validation. We also track all experiments with MLFlow and log model parameters, hyperparameters, datasets, feature sets, performance metrics, validation charts, and so on. We love our setup, but if our product and legal teams want access to this data for their own purposes, they immediately come up against barriers.
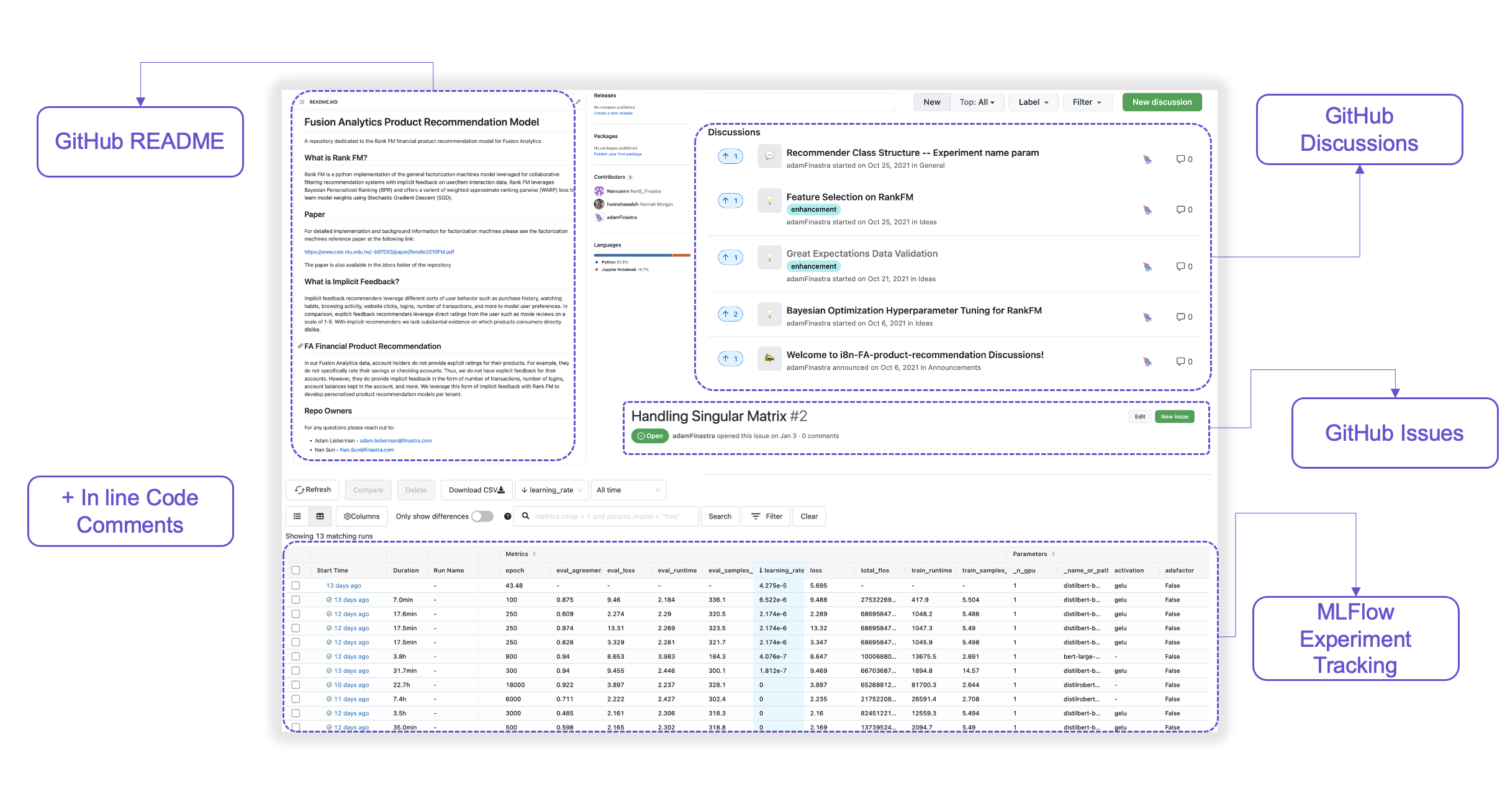
A representation of the information required by data science teams
First, any new person on their teams must request access to our organizational resources like GitHub, Databricks, and our Azure Active Directory.
Secondly, they are struck by information overload—they don’t always care about seeing sortable logs of experiments, and there is a majority of data that is irrelevant to them.
Lastly, they are not comfortable with the tools we use and are used to having spreadsheets and reports in easy-to-use formats, such as PDF and HTML, that are visually simple and can be easily shared. So, how do we as data scientists expose the required information about our models to other teams?
Introducing Model Cards
In 2019, Google released a paper called "Model Cards for Model Reporting." Google had the same challenges as us, in that they saw that there was no set standard for documentation procedures to communicate information around ML models and that there was a need for a shared understanding for everyone. From content to process to fairness and privacy, it was great to see that there was thought around documentation for all. They even had a Python library, but it was not as flexible as we needed and not as tailored to what our teams were asking for. For reference, Google’s paper suggested logging model details, intended use, metrics, evaluation data, ethical considerations, recommendations, and more. This is a fantastic list, but we took it upon ourselves to give the Model Cards library a new look, and also tailor it for our data product and legal teams.
Building on what Google had done, we wanted to create a set of cards that contained the right amount of information for each team. After discussion we came to an agreement to log the following:
- Business information such as the business unit, product, and both a high-level and detailed description
- Repo information, such as our Databricks environments and GitHub repositories
- Developer information and contact info
- Light dataset information highlighting if PII is present
- Some model architecture information
- A feature table that discloses if features are considered sensitive and how they were created
- Validation metrics and charts
- Training electricity for sustainability, sections to log interpretability, and also a section for bias and fairness
- Additionally, developers can add notes to their cards for any pertinent info they want the other teams to know.
We wanted a really clean and flat look for our cards and the ability to generate a nice HTML document. We created a Python wrapper around some Semantic UI components that would generate the HTML, CSS, and JavaScript behind the file. With a simple API to add information and order the grids, it gave the data science team easy flexibility to integrate the information they were generating in their pipelines right into a model card. It accomplished a shared set of info all sides were looking for, a nice look and feel, a file that was interactive and easy to share, standardized, and simple for our data scientists to integrate into their workflow.
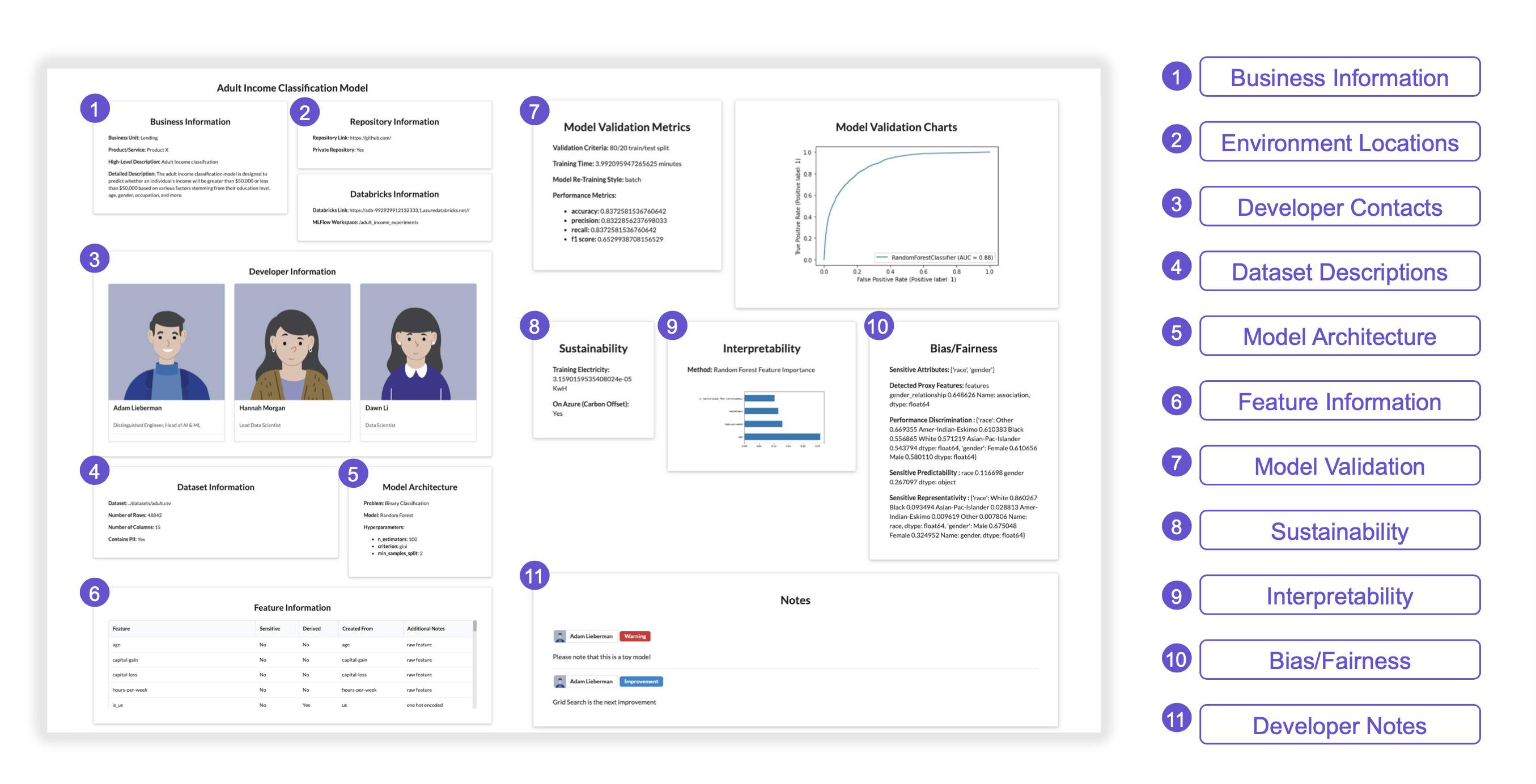
A model card that allows users to quickly access the information that is relevant to them
Taking a Tailored Approach
Experimenting with model cards has been a fun and useful exploration for our team in collaborating with all of our stakeholders from different backgrounds and domains. It’s been a long journey setting up our infrastructure and creating a comfortable and smooth environment for our data scientists and engineers to operate from. But there is still a lot of work to do and there’s no one right answer for a standardized approach to model cards or even MLOps infrastructure.
My implementation was tailored more to the needs of my organization’s internal stakeholders, to help them collaborate with the data science team. However, the need for standardized model cards in an industry-agnostic fashion is still needed. To establish this standard, I would put the following questions to the broader data science community:
- What is important to document in your company/industry from an ML perspective?
- Who are your key stakeholders?
- How can we better standardize this process?
- How can we ensure additional documentation is as seamless as possible for the data scientists developing the models?
- How can we best share and visualize the results for our non-technical teams?
If we can agree on the above, we can move to create a standard model card that can be used across industries and make data science accessible and ultimately understandable to all.
Opinions expressed by DZone contributors are their own.
Comments