Migration of Legacy DB/File Structure to RDBMS
Migration is difficult, but sometimes, it's required — like if you want to improve your database's performance or utilize features of the target RDBMS that are missing in the source.
Join the DZone community and get the full member experience.
Join For FreeThis article details a migration process for a popular database (ADABAS, a Software AG product) and mainframe VSAM file structure to target RDBMS. Here, I have chosen ADABAS DB (non-relational) as the legacy source database and chosen the file structure as VSAM files (hierarchical).
Why Is Migration Required?
Although the source VSAM or ADABAS is quite efficient in handling legacy data and mission-critical applications, and VSAM can be found on almost every mainframe, there are still reasons to migrate — for example, to improve performance or to utilize features of the target RDBMS that are missing in the source.
VSAM File Structure
- VSAM doesn’t understand how records are stored internally, so querying and retrieving data based on condition is not possible (i.e. extracting employees who are in the IT department). Moreover, you need a program for data extraction from VSAM files.
- VSAM will not store any metadata information (i.e. data relationships) so data analysis can’t be done easily.
- Once the VSAM file is loaded initially, tuning the file will be difficult to do later.
- VSAM security is limited at the data level and recovery is also limited.
- VSAM is restricted to the mainframe platform.
ADABAS DB
- Cannot compete with open systems to meet today’s business demands.
- Incompatible with modern data management solutions.
- Critical data is locked up in legacy databases; database modernization can’t be achieved.
- Is an expensive non-relational database.
What Drives Migration to RDBMS
To provide advantages of migrating to RDMBS, I have chosen Oracle as a sample relational DB and listed below some of its advantages.
- Oracle provides a high level of scalability.
- Oracle provides a high degree of security from a table to a specific data value.
- Oracle supports lots of tools for data manipulation, data replication, data warehousing, performance monitoring, and archival and report generation.
- Oracle is web-enabled with built-in Java support, and data can be accessed from various systems using standard TCP/IP, ODBC, or JDBC.
- Oracle supports disaster recovery.
Data Migration Approach
Below is a detailed step-by-step approach to migrating VSAM files/ADABAS DB to RDBMS.
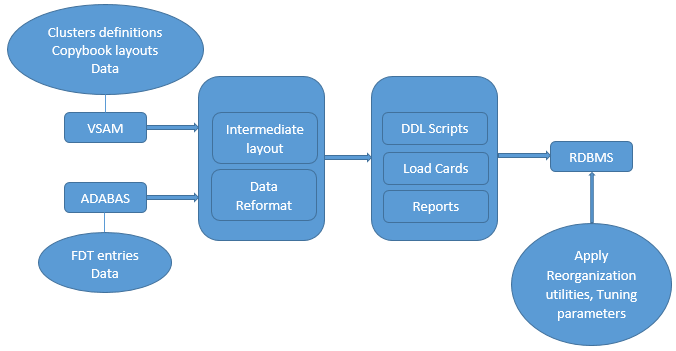
Schema and Data Extraction
Extract the ADABAS DB schema, VSAM file definitions, and their data either using existing DB extraction utilities or automated scripts (if utilities aren't available) and convert them to intermediate structures.
VSAM File Definitions and Data Extraction
Use automation scripts to extract and format VSAM file definitions from IDCAMS DEFINE CLUSTER and DEFINE AIX declarations for batch files, from the CICS DEFINE FILE declarations for online files, and extract and format the layouts from corresponding VSAM copybooks. This provides the necessary information about the primary key, any alternate keys, and layouts to allow the creation of a table for each VSAM file that can be accessed efficiently. Also, extract the data to flat files (i.e. using REPRO). We need to consider the below throughout the conversion process.
- VSAM base cluster key becomes target DB primary key.
- Copybook field becomes DB column.
FILLERfields have to be omitted in DB table.- Converting numerical fields to
SMALLINT,INTEGER, andDECIMALdepends on the size and decimal point. - Handle special cases like Redefined copybook record layouts,
OCCURSclauses, andGROUPS - Change field attributes, like extend field size, if required.
A VSAM file has a primary index with a unique key. In addition, it can have one or more alternate indexes, which may or may not allow duplicate keys. In this case, an alternate index with duplicates can be replaced with a non-unique index in the target DB. In VSAM, a single record can be randomly read via any index key, or multiple records can be read using a start operation followed by multiple "read next" and/or "read previous" operations. In this case, DB cursors can be replaced in application programs to scan across table rows. In application programs, VSAM calls will be replaced with new SQL calls and package binds have to be done as per embedded SQL programs. And in case of DB2 as a target, batch JCLs have to be modified to comment VSAM files usage and accommodate the steps required to access DB2.
ADABAS DB Schema and Data Extraction
Use ADABAS data extraction utilities (i.e. ADAULD, ADACMP, etc.) and parameters to unload the schema and data, decompress the data (as data in ADABAS is stored in compressed format), format the data (in case of, for example, MU/PE occurrences or NULL suppressions), and extract FDT and data into flat files.
Identify and list down the various ADABAS data types and have an exhaustive list of special features (i.e. conditions, indexes, and NULL value-handling on fields).
Define the Intermediate Structure (Source Layout Reformat)
Here, source layout is reformatted into an intermediate structure to accommodate any legacy DB as a source, bring into the common format and handling the same approach thereafter for conversion.
- Create a generic mapping of the above lists or source data types to an intermediate type.
- Convert the extracted schemas to an intermediate structure for the common data types.
- Convert the schema to an intermediate structure for special data types and unique features.
- Represent the (non-)unique indexes or keys for the columns in an intermediate layout.
Validation of Extracted Data
The process below validates extracted data and generates a discrepancy report, if there is any to be generated.
- Data type validation: Check the extracted data against the intermediate layout generated (i.e. numeric data, alphabetic data, etc.) and conditions on fields (in case the source is DB).
- Referential Integrity (foreign key) validation (in case source is DB): List all the unique index keys from the source DB, get help from an SME to identify any foreign key relations between tables, and record them explicitly for those fields in the intermediate layout.
- Any special validations: Needed to handle the scripts, if any.
Data Reformat and Loading
Reformat the source data and load into the target using below approach.
- Create target RDBMS load card/layout from the common intermediate structure.
- Reformat/massage the data to fit into the target RDBMS layout created and/or fix any data discrepancies.
- Create DDL script from the layout for the creation of actual tables and unique/non-unique indexes; impose field level conditions/restrictions; if required, use any new features in RDBMS (i.e. triggers, partitioning, etc.) for optimization.
- Run the DDL script in the target RDBMS to create tables and add features to them.
- Run the load scripts to load the formatted data into the target RDBMS in sync with schemas.
- Run the reorganization utilities (i.e.
REORG,RUNSTATS,CHECK RI, etc.) on the target DB for integrity checks or sanity.
Reports Verification
Below reports can be generated for one-on-one mapping verification after successful data migration to RDBMS.
- Complete entity-relationship model (ERM) diagrams for the new RDBMS.
- Summary reports of the source database (ADABAS or VSAM files) and usage.
- Matrix reports that relate source files to target DB tables and source fields to target DB columns.
- In case of ADABAS, MU and PE have "maximum occurrences" and date field finder reports.
- Additional reports include further detailed identification of the unique/special characteristics of the source database (ADABAS or VSAM files) and its conversion.
Conclusion
By using the above approach, we can successfully migrate data to RDBMS without losing data and still keep in sync with the schema. We can use scripts for mapping and verification and use manual intervention sometimes to handle special scenarios (i.e. build foreign key relation with parent tables based on SME input, etc.). For verification reports during or after migration, we can either generate a few or all of them to ensure that the migration process was successful for audit purposes. In case of any wrong mappings, we can refer these reports and take action immediately.
Opinions expressed by DZone contributors are their own.
Comments