Migrating Hadoop to the Cloud: 2X Storage Capacity and Fewer Ops Costs
Learn how Yimian, an AI-powered data analytics provider, implemented a compute-storage decoupled architecture, doubled storage capacity, and cut operational costs.
Join the DZone community and get the full member experience.
Join For FreeYimian is a leading AI-powered data analytics provider specializing in digital commerce data. We offer real-time insights on business strategy, product development, and digital commerce operations. Many of our customers are industry leaders in personal care, makeup, F&B, pet, and auto, like Procter and Gamble, Unilever, and Mars.
Our original technology architecture was a big data cluster built using CDH (Cloudera Distributed Hadoop) in an on-premises data center. As our business grew, the data volume increased dramatically.
To address challenges such as lengthy scaling cycles, mismatched compute and storage resources, and high maintenance costs, we decided to transform our data architecture and migrate to the cloud, adopting a storage-compute separation approach. After a careful evaluation, we embraced Alibaba Cloud Elastic MapReduce (EMR) + JuiceFS + Alibaba Cloud Object Storage Service (OSS).
Currently, with JuiceFS, we’ve implemented a compute-storage decoupled architecture, doubling our total storage capacity. Notably, we observed no significant performance impact, and our operational costs have been significantly reduced.
In this article, we’ll share our architecture design for migrating Hadoop to the cloud, why we chose JuiceFS+EMR+OSS, and how we benefit from the new architecture. We aim to offer valuable insights for those facing similar challenges through this post.
Our Old Architecture and Challenges
To meet our growing application demands, we’ve been crawling data from hundreds of large websites, with the current count exceeding 500. Over time, we have accumulated substantial amounts of raw, intermediate, and result data. As we continued to expand our website crawls and customer base, our data volume was rapidly increasing. Therefore, we decided to scale our hardware to accommodate the growing requirements.
The Original Architecture
The following figure shows our previous architecture, which involved a CDH-based big data cluster deployed in a data center:
- The key components included Hive, Spark, and HDFS.
- Several data production systems, with Kafka being one of them, fed data into the cluster.
- We used other storage solutions, such as TiDB, HBase, and MySQL, alongside Kafka.
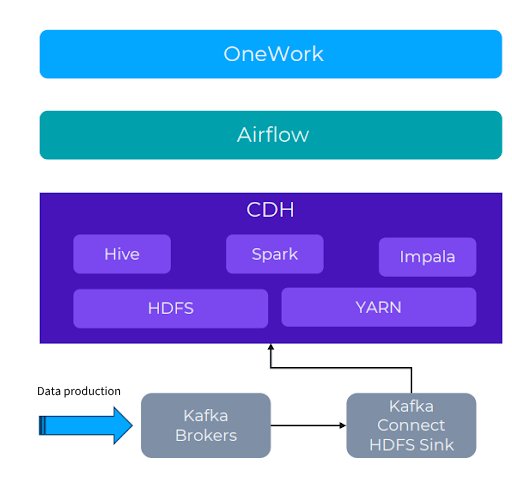
Data flowed from upstream application systems and data collection systems, where it was written to Kafka. We employed a Kafka Connect cluster to sync the data into HDFS.
On top of this architecture, we developed a custom data development platform called OneWork to manage various tasks. These tasks were scheduled via Airflow and processed in task queues.
Our Pain Points
The challenges we faced were as follows:
- Rapid growth of application data and long scaling cycles: Our CDH cluster, deployed in 2016, already handled petabytes of data by 2021. However, data growth often exceeded hardware planning, leading to frequent scaling every six months. This consumed significant resources and time.
- Storage-compute coupling and difficulty in capacity planning: The traditional Hadoop architecture's tight coupling of storage and compute makes it challenging to independently scale and plan based on storage or compute requirements. For example, expanding storage would also require purchasing unnecessary compute resources. This led to inefficient resource allocation.
- Afraid to upgrade due to our CDH version: Our CDH version was old, and we hesitated to upgrade due to concerns about stability and compatibility.
- High operations costs: With about 200 employees, we had only one full-time operations staff. This brought about a heavy workload. To alleviate this, we sought a more stable and simple architecture.
- Single data center point of failure: All data stored in a single data center posed a long-term risk. In case of cable damages or other issues, having a single data center creates a single point of failure.
Our Requirements for the New Architecture
To address our challenges and meet the growing demands, we decided on some architectural changes. The main aspects we considered for the upgrade include the following:
- Cloud adoption, elastic scalability, and operational flexibility: Embracing cloud services would simplify operations. For example, leveraging cloud-based storage allows us to focus on the application while avoiding maintenance tasks. Additionally, cloud resources enable elastic scalability without lengthy hardware deployments and system configurations.
- Storage-compute decoupling: We aimed to separate storage and compute to achieve better flexibility and performance.
- Preference for open-source components, avoiding vendor lock-in: Although we use cloud services, we sought to minimize reliance on specific vendors. While using AWS Redshift for customer services, we leaned towards open-source components for in-house operations.
- Compatibility with existing solutions, controlling costs and risks: Our goal was to ensure compatibility with current solutions to minimize development costs and impact on our application.
Why We Chose JuiceFS+EMR+OSS
After we evaluated various solutions, we chose EMR+JuiceFS+OSS to build a storage-compute separated big data platform and gradually migrated our on-premises data center to the cloud.
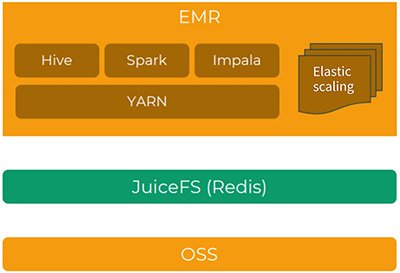
In this setup, object storage replaces HDFS, and JuiceFS serves as the protocol layer due to its support for POSIX and HDFS protocols. At the top, we use a semi-managed Hadoop solution, EMR. It includes Hive, Impala, Spark, Presto/Trino, and other components.
Alibaba Cloud vs. Other Public Clouds
After our careful evaluation, we chose Alibaba Cloud over AWS and Azure due to the following factors:
- Proximity: Alibaba Cloud's availability zone in the same city as our data center ensures low latency and reduced network costs.
- Comprehensive open-source components: Alibaba Cloud EMR offers a wide range of Hadoop-related open-source components. Apart from our heavy usage of Hive, Impala, Spark, and Hue, it also provides seamless integration with Presto, Hudi, Iceberg, and more. During our research, we discovered that only EMR natively includes Impala, whereas AWS and Azure either offer lower versions or require manual installation and deployment.
JuiceFS vs. JindoFS
What’s JuiceFS?
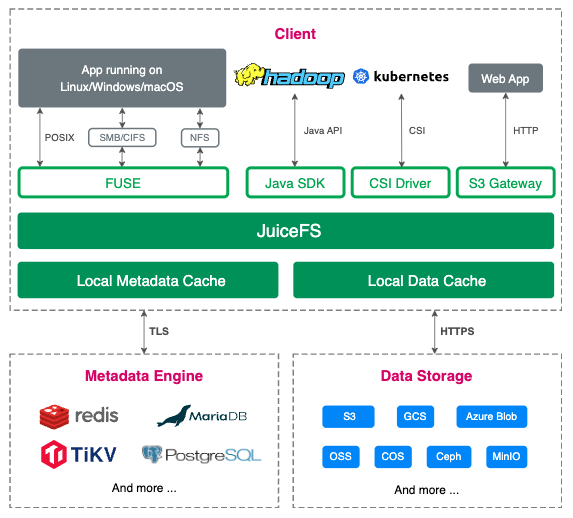
JuiceFS is an open-source, cloud-native, distributed file system with high performance. It provides full POSIX compatibility, allowing object storage to be used as a massive local disk across different platforms and regions.
JuiceFS adopts a data-metadata separated architecture, enabling a distributed file system design. When using JuiceFS to store data, the data is persisted in object storage like Amazon S3, while metadata can be stored on Redis, MySQL, TiKV, SQLite, and other databases.
In addition to POSIX, JuiceFS is fully compatible with the HDFS SDK, allowing seamless replacement of HDFS for storage-compute separation.
Why We Chose JuiceFS Over JindoFS
We opted for JuiceFS over JindoFS based on the following considerations:
- Storage design: JuiceFS adopts a data and metadata separation storage architecture, enabling a distributed file system design. Data is persisted in object storage, while metadata can be stored in various databases like Redis, MySQL, TiKV, and SQLite, providing higher flexibility. In contrast, JindoFS' metadata is stored on the EMR cluster's local hard disk, making maintenance, upgrades, and migrations less convenient.
- Storage flexibility: JuiceFS offers various storage solutions, supporting online migration between different schemes and increasing portability. JindoFS block data only supports OSS.
- Open-source community support: JuiceFS is based on an open-source community, supporting all public cloud environments. This facilitates future expansion to a multi-cloud architecture.
The Entire Architecture Design
Considering that some applications will still be kept in the Hadoop cluster of the data center, we actually employ a hybrid cloud architecture, as shown in the figure below.
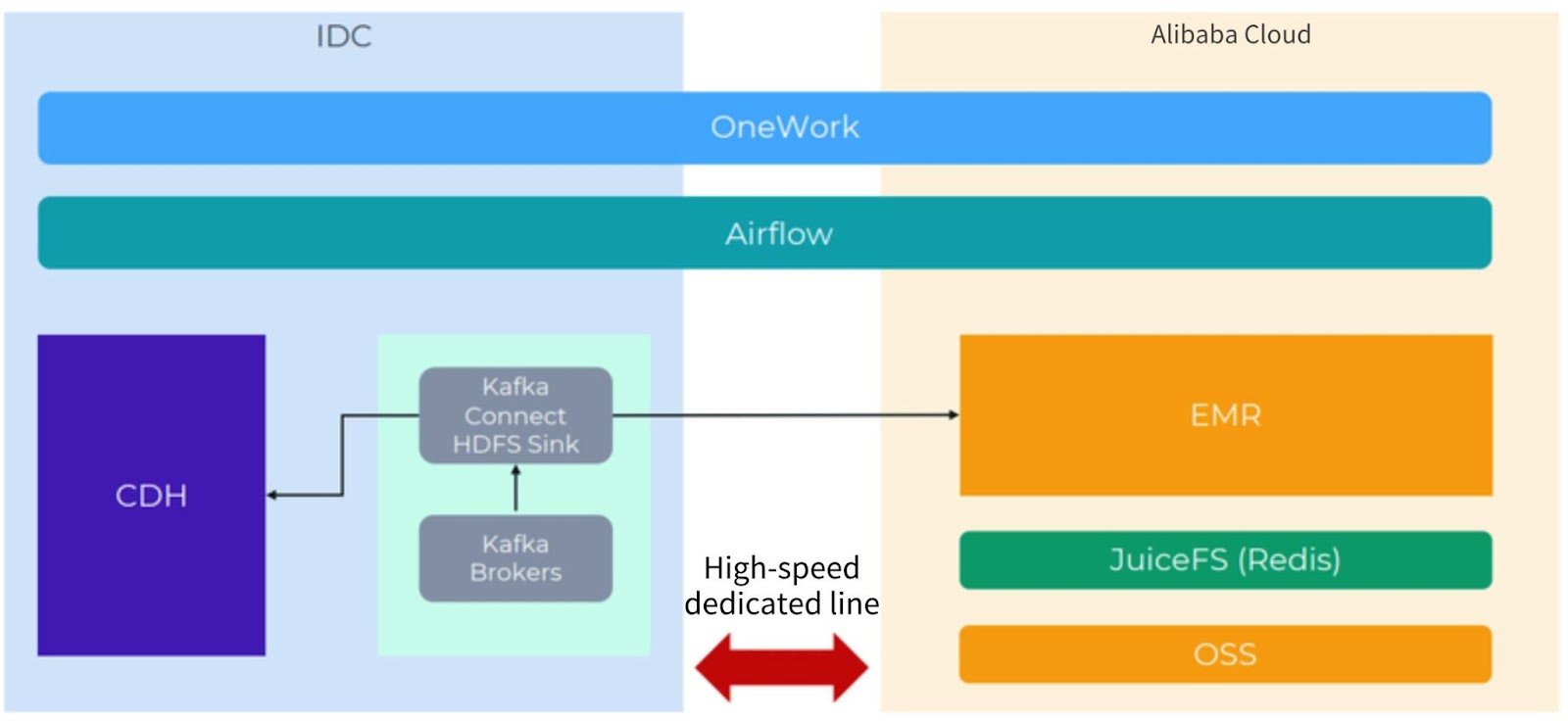
In the architecture figure:
- At the top are Airflow and OneWork, both of which support distributed deployment, so they can be easily scaled horizontally.
- On the left is the IDC, which uses the traditional CDH architecture and some Kafka clusters.
- On the right is the EMR cluster deployed on Alibaba Cloud.
The IDC and the EMR cluster are connected by a high-speed dedicated line.
How We Benefit From the New Architecture
Benefits of Storage-Compute Separation
With the implementation of storage-compute decoupling, our total storage capacity has doubled while the compute resources remain stable. Occasionally, we enable temporary task nodes as needed. In our scenario, data volume experiences rapid growth while query demands remain stable. Since 2021, our data volume has doubled. We have made minimal changes to the compute resources from the initial stage until now, except for occasionally enabling elastic resources and temporary task nodes to address specific application needs.
Performance Changes
For our application scenario, which primarily involves large-scale batch processing for offline computation, there is no significant impact on the performance. However, during the PoC phase, we observed improvements in response times for ad-hoc Impala queries.
During the PoC phase, we conducted some simple tests. However, accurately interpreting the results is challenging due to various influencing factors:
- The transition from HDFS to JuiceFS
- Component version upgrades
- Changes to the Hive engine
- Changes to the cluster load
All these make it difficult to draw definitive conclusions about performance differences compared to our previous deployment of CDH on bare metal servers.
Usability and Stability
We haven’t encountered issues with JuiceFS.
While using EMR, we had minor problems. Overall, CDH is perceived as more stable and user-friendly.
Implementation Complexity
In our scenario, the most time-consuming processes are incremental dual-write and data verification. In retrospect, we invested excessively in verification and could simplify it.
Multiple factors influence complexity:
- Application scenarios (offline/real-time, number of tables/tasks, upper-level applications)
- Component versions
- Supporting tools and reserves
Future Plans
Our future plans include:
- Continuing the migration of the remaining applications to the cloud.
- Exploring a cold/hot tiered storage strategy using JuiceFS+OSS. JuiceFS files are entirely disassembled on OSS, making it challenging to implement file-level tiering. Our current approach involves migrating cold data from JuiceFS to OSS, setting it as archive storage, and modifying the LOCATION of Hive tables or partitions without impacting usage.
- If the data volume increases and there is pressure on using Redis, we may consider switching to TiKV or other engines in the future.
- Exploring EMR's elastic compute instances to reduce usage costs while meeting application service level agreements.
Published at DZone with permission of Yangliang Li. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments