Microservices With Apache Camel and Quarkus (Part 5)
After learning how to run our microservices in Minikube in part three of this series, let's look at how to do the same in OpenShift.
Join the DZone community and get the full member experience.
Join For FreeIn part three of this series, we have seen how to deploy our Quarkus/Camel-based microservices in Minikube, which is one of the most commonly used Kubernetes local implementations. While such a local Kubernetes implementation is very practical for testing purposes, its single-node feature doesn't satisfy real production environment requirements. Hence, in order to check our microservices behavior in a production-like environment, we need a multi-node Kubernetes implementation. And one of the most common is OpenShift.
What Is OpenShift?
OpenShift is an open-source, enterprise-grade platform for container application development, deployment, and management based on Kubernetes. Developed by Red Hat as a component layer on top of a Kubernetes cluster, it comes both as a commercial product and a free platform or both as on-premise and cloud infrastructure. The figure below depicts this architecture.
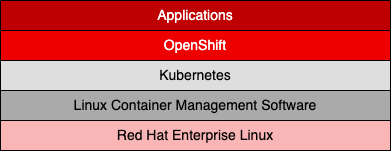
As with any Kubernetes implementation, OpenShift has its complexities, and installing it as a standalone on-premise platform isn't a walk in the park. Using it as a managed platform on a dedicated cloud like AWS, Azure, or GCP is a more practical approach, at least in the beginning, but it requires a certain enterprise organization.
For example, ROSA (Red Hat OpenShift Service on AWS) is a commercial solution that facilitates the rapid creation and the simple management of a full Kubernetes infrastructure, but it isn't really a developer-friendly environment allowing it to quickly develop, deploy and test cloud-native services.
For this later use case, Red Hat offers the OpenShift Developer's Sandbox, a development environment that gives immediate access to OpenShift without any heavy installation or subscription process and where developers can start practicing their skills and learning cycle, even before having to work on real projects. This totally free service, which doesn't require any credit card but only a Red Hat account, provides a private OpenShift environment in a shared, multi-tenant Kubernetes cluster that is pre-configured with a set of developer tools, like Java, Node.js, Python, Go, C#, including a catalog of Helm charts, the s2i build tool, and OpenShift Dev Spaces.
In this post, we'll be using OpenShift Developer's Sandbox to deploy our Quarkus/Camel microservices.
Deploying on OpenShift
In order to deploy on OpenShift, Quarkus applications need to include the OpenShift extension. This might be done using the Qurakus CLI, of course, but given that our project is a multi-module maven one, a more practical way of doing it is to directly include the following dependency in the master POM:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-openshift</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-container-image-openshift</artifactId>
</dependency>
This way, all the sub-modules will inherit the dependencies.
OpenShift is supposed to work with vanilla Kubernetes resources; hence, our previous recipe, where we deployed our microservices on Minikube, should also apply here. After all, both Minikube and OpenShift are implementations of the same de facto standard: Kubernetes.
If we look back at part three of this series, our Jib-based build and deploy process was generating vanilla Kubernetes manifest files (kubernetes.yaml), as well as Minikube ones (minikube.yaml). Then, we had the choice between using the vanilla-generated Kubernetes resources or the more specific Minikube ones, and we preferred the latter alternative. While the Minikube-specific manifest files could only work when deployed on Minikube, the vanilla Kubernetes ones are supposed to work the same way on Minikube as well as on any other Kubernetes implementation, like OpenShift.
However, in practice, things are a bit more complicated, and, as far as I'm concerned, I failed to successfully deploy on OpenShift vanilla Kubernetes manifests generated by Jib. What I needed to do was to rename most of the properties whose names satisfy the pattern quarkus.kubernetes.* by quarkus.openshift.*. Also, some vanilla Kubernetes properties, for example quarkus.kubernetes.ingress.expose, have a completely different name for OpenShift. In this case quarkus.openshift.route.expose.
But with the exception of these almost cosmetic alterations, everything remains on the same site as in our previous recipe of part three. Now, in order to deploy our microservices on OpenShift Developer's Sandbox, proceed as follows.
Log in to OpenShift Developer's Sandbox
Here are the required steps to log in to OpenShift Developer Sandbox:
- Fire your preferred browser and go to the OpenShift Developer's Sandbox site
- Click on the
Loginlink in the upper right corner (you need to already have registered with the OpenShift Developer Sandbox) - Click on the red button labeled
Start your sandbox for freein the center of the screen - In the upper right corner, unfold your user name and click on the
Copy login commandbutton - In the new dialog labeled
Log in with ...click on theDevSandboxlink - A new page is displayed with a link labeled
Display Token. Click on this link. - Copy and execute the displayed
occommand, for example:
$ oc login --token=... --server=https://api.sandbox-m3.1530.p1.openshiftapps.com:6443Clone the Project From GitHub
Here are the steps required to clone the project's GitHub repository:
$ git clone https://github.com/nicolasduminil/aws-camelk.git
$ cd aws-camelk
$ git checkout openshiftCreate the OpenShift Secret
In order to connect to AWS resources, like S3 buckets and SQS queues, we need to provide AWS credentials. These credentials are the Access Key ID and the Secret Access Key. There are several ways to provide these credentials, but here, we chose to use Kubernetes secrets. Here are the required steps:
- First, encode your Access Key ID and Secret Access Key in Base64 as follows:
$ echo -n <your AWS access key ID> | base64
$ echo -n <your AWS secret access key> | base64- Edit the file
aws-secret.yamland amend the following lines such that to replace...by the Base64 encoded values:
AWS_ACCESS_KEY_ID: ...
AWS_SECRET_ACCESS_KEY: ...- Create the OpenShift secret containing the AWS access key ID and secret access key:
$ kubectl apply -f aws-secret.yamlStart the Microservices
In order to start the microservices, run the following script:
$ ./start-ms.shThis script is the same as the one in our previous recipe in part three:
#!/bin/sh
./delete-all-buckets.sh
./create-queue.sh
sleep 10
mvn -DskipTests -Dquarkus.kubernetes.deploy=true clean install
sleep 3
./copy-xml-file.shThe copy-xml-file.sh script that is used here in order to trigger the Camel file poller has been amended slightly:
#!/bin/sh
aws_camel_file_pod=$(oc get pods | grep aws-camel-file | grep -wv -e build -e deploy | awk '{print $1}')
cat aws-camelk-model/src/main/resources/xml/money-transfers.xml | oc exec -i $aws_camel_file_pod -- sh -c "cat > /tmp/input/money-transfers.xml"Here, we replaced the kubectl commands with the oc ones. Also, given that OpenShift has this particularity of creating pods not only for the microservices but also for the build and the deploy commands, we need to filter out in the list of the running pods the ones having string occurrences of build and deploy.
Running this script might take some time. Once finished, make sure that all the required OpenShift controllers are running:
$ oc get is
NAME IMAGE REPOSITORY TAGS UPDATED
aws-camel-file default-route-openshift-image-registry.apps.sandbox-m3.1530.p1.openshiftapps.com/nicolasduminil-dev/aws-camel-file 1.0.0-SNAPSHOT 17 minutes ago
aws-camel-jaxrs default-route-openshift-image-registry.apps.sandbox-m3.1530.p1.openshiftapps.com/nicolasduminil-dev/aws-camel-jaxrs 1.0.0-SNAPSHOT 9 minutes ago
aws-camel-s3 default-route-openshift-image-registry.apps.sandbox-m3.1530.p1.openshiftapps.com/nicolasduminil-dev/aws-camel-s3 1.0.0-SNAPSHOT 16 minutes ago
aws-camel-sqs default-route-openshift-image-registry.apps.sandbox-m3.1530.p1.openshiftapps.com/nicolasduminil-dev/aws-camel-sqs 1.0.0-SNAPSHOT 13 minutes ago
openjdk-11 default-route-openshift-image-registry.apps.sandbox-m3.1530.p1.openshiftapps.com/nicolasduminil-dev/openjdk-11 1.10,1.10-1,1.10-1-source,1.10-1.1634738701 + 46 more... 18 minutes ago
$ oc get pods
NAME READY STATUS RESTARTS AGE
aws-camel-file-1-build 0/1 Completed 0 19m
aws-camel-file-1-d72w5 1/1 Running 0 18m
aws-camel-file-1-deploy 0/1 Completed 0 18m
aws-camel-jaxrs-1-build 0/1 Completed 0 14m
aws-camel-jaxrs-1-deploy 0/1 Completed 0 10m
aws-camel-jaxrs-1-pkf6n 1/1 Running 0 10m
aws-camel-s3-1-76sqz 1/1 Running 0 17m
aws-camel-s3-1-build 0/1 Completed 0 18m
aws-camel-s3-1-deploy 0/1 Completed 0 17m
aws-camel-sqs-1-build 0/1 Completed 0 17m
aws-camel-sqs-1-deploy 0/1 Completed 0 14m
aws-camel-sqs-1-jlgkp 1/1 Running 0 14m
oc get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
aws-camel-jaxrs ClusterIP 172.30.192.74 <none> 80/TCP 11m
modelmesh-serving ClusterIP None <none> 8033/TCP,8008/TCP,8443/TCP,2112/TCP 18hAs shown in the listing above, all the required image streams have been created, and all the pods are either completed or running. The completed pods are the ones associated with the build and deploy operations. The running ones are associated with the microservices.
There is only one service running: aws-camel-jaxrs. This service makes it possible to communicate with the pod that runs the aws-camel-jaxrs microservice by exposing the route to it. This is automatically done in effect to the quarkus.openshift.route.expose=true property. And the microservice aws-camel-sqs needs, as a matter of fact, to communicate with aws-camel-sqs and, consequently, it needs to know the route to it. To get this route, you may proceed as follows:
$ oc get routes
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
aws-camel-jaxrs aws-camel-jaxrs-nicolasduminil-dev.apps.sandbox-m3.1530.p1.openshiftapps.com aws-camel-jaxrs http None
Now open the application.properties file associated with the aws-camel-sqs microservice and modify the property rest-uri such that to read as follows:
rest-uri=aws-camel-jaxrs-nicolasduminil-dev.apps.sandbox-m3.1530.p1.openshiftapps.com/xferHere, you have to replace the namespace nicolasduminil-dev with the value which makes sense in your case. Now, you need to stop the microservices and start them again:
$ ./kill-ms.sh
...
$ ./start-ms.sh
...Your microservices should run as expected now, and you may check the log files by using commands like:
$ oc logs aws-camel-jaxrs-1-pkf6nAs you may see, in order to get the route to the aws-camel-jaxrs service, we need to start, to stop, and to start our microservices again. This solution is far from being elegant, but I didn't find any other, and I'm relying on the advised reader to help me improve it. It's probably possible to use the OpenShift Java client in order to perform, in Java code, the same thing as the oc get routes command is doing, but I didn't find how, and the documentation isn't too explicit.
I would like to present my apologies for not being able to provide here the complete solution, but enjoy it nevertheless!
Opinions expressed by DZone contributors are their own.
Comments