Resilient MultiCloud Messaging
Messaging becomes an important technical option when operating solutions span clouds, hybrid deployments, and even inter-application and inter-process communication.
Join the DZone community and get the full member experience.
Join For FreeAsynchronous communication for applications through messaging has been around for a long time. One of the reasons for the adoption of messaging is to mitigate issues of connectivity, which can come from:
- Applications not being built or deployed to provide a high level of resilience to ensure always-available characteristics. Therefore, the messaging infrastructure provided by a broker can hold a message until it can be delivered.
- Mitigate infrastructure issues such as potential networking issues such as connection loss.
- Mitigate bandwidth/capacity constraints on the receiving service or its infrastructure.
- Data egress costs from a cloud vendor.
- Prevent cascading application faults because one service is unavailable, which impacts a consuming service if it is directly connected.
Messaging Overcomes Transient Network Issues
The mitigation of connectivity is important when systems become increasingly distributed, as in all but the rarest of cases, the flow of communications will traverse pieces of infrastructure (servers, routers, proxies, firewalls, and even physical switches) over which we have no control. You only have to look in the press to see incidents where services have been impacted by accidental or deliberate disruption, from breaks in submarine cabling (the most notable recent issue being Tonga’s volcanic eruption) and major network backbone centers. While a great deal of effort goes into public infrastructure protection, like our macro level, it will all come down to cost-benefit. We can also see that these issues can occur more frequently than we’d like through the data shared by ThousandEyes.com.
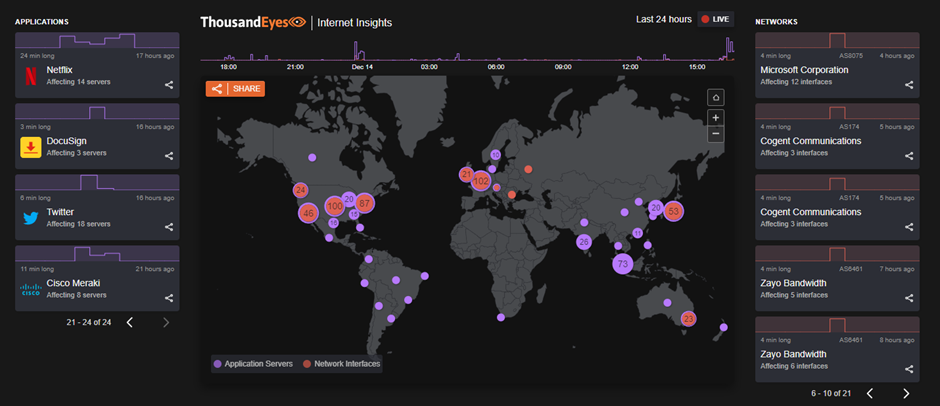
ThousandEyes dashboard showing internet service disruptions.
Different Clouds, Different Native Services
With this in mind, messaging becomes an important technical option when operating solutions span clouds, hybrid deployments, and even inter-application and inter-process communication, as it can cushion the application logic from the complexities of handling communication issues. This can become more problematic when adopting different cloud vendor serverless messaging solutions as they may not be able to plug into other cloud vendor serverless solutions. For example, connecting AWS’s Simple Queue Service (SQS) directly to OCI’s Queue service isn’t possible today. This is where Solace, with its PubSub+ offering, comes into its own, and given that Oracle is a great believer in supporting multi-cloud needs, we have been working with Solace to demonstrate why PubSub+ is a good proposition and the features of Oracle Cloud (OCI) that make a big difference to the cost and performance of running PubSub+.
Solace’s vision is to enable an event-based mesh (just as we have service meshes and data meshes). PubSub+ enables the idea of an Event Mesh where different cloud services and protocols can be stitched together. For example AWS Lambda solution could generate an SQS message, which is then received by a Java JMS application running on Google’s GKS and a REST web application on Azure, an APEX application using TEQ (Transaction Event Queue, the latest generation of Oracle Databases’ AQ) on-premises or in OCI (and now even in Azure) and cloud-native applications on OCI (using Kubernetes) and OCI Queue and OCI Streaming for example. Our scenario could extend so that the application running AWS using SQS can talk to Google’s PubSub, which supports analytical operations with BigQuery while at the same time transacting with a cloud-hosted EBusiness Suite deployment. There is no need to modify the AWS app because we need to plumb the data info to another system on another cloud.
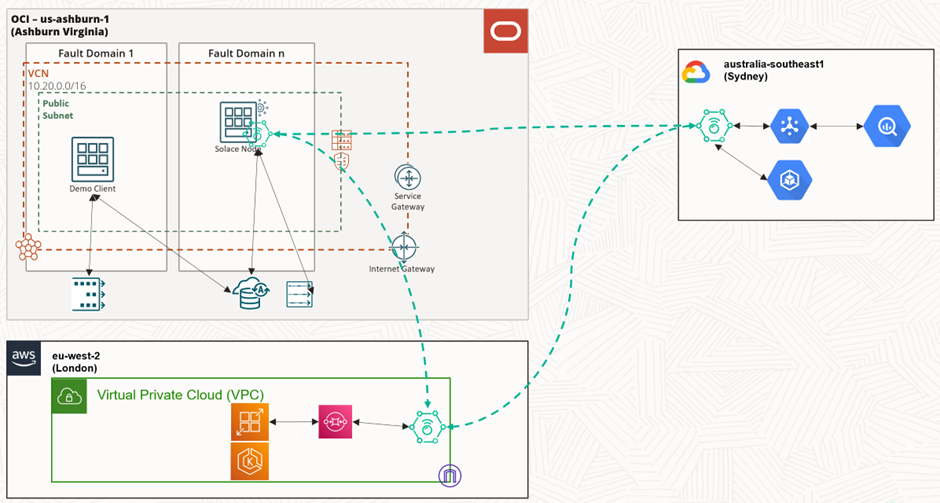
Hypothetical/demo deployment of Solace Pub/Sub+ with multiple clouds
To achieve this, we can deploy PubSub+ on Kubernetes, not to mention services like Container Instances or good old vanilla VMs. Such deployments can be in a variety of configurations, from single-node deployments to highly resilient clusters. We can either directly connect our applications to Solace if we're using common open protocols such as Kafka, MQTT, JMS, etc. If applications are using local cloud-provided services, Solace allows them to continue to use those, and we connect Solace to those services so that the application is unaware of any changes.
How we deploy Solace depends upon the specific needs. If all our clouds are using local native services, we could look at a hub and spoke model as Solace becomes a transparent routing and platform, and there is local resilience to network factors from the native services. If applications are connecting directly to Solace, then we should look to having localized nodes to minimize the impact of network issues on the applications, as we discussed.
With suitable deployments, a highly resilient messaging framework where applications are entirely shielded from network, routing, and application deployment issues, as Solace is providing the intelligence to channel messages across its mesh.
Messaging (and PubSub+) Performance Considerations
When deploying PubSub+, we need to be very conscious of storage IOPS performance + (which is true of many other messaging solutions). For guaranteed delivery, particularly deliver once-only requirements, the brokers become very I/O intensive, as the broker is constantly adding and removing the messages from physical storage, and storage performance impacts the ability to complete secured transfers of messages at high rates.
Ideally, we need to minimize any abstraction overheads for storage – particularly when dealing with Kubernetes environments and the Container Storage Interface implementation supporting the persistent storage volumes. If our systems have demand fluctuations and end points are elastically scaling a lot, we also want our storage performance to scale. After all, we don’t want to pay for storage performance based on peak load. Ideally, we want our storage IOPs performance to scale based on the actual workload.
The work Oracle has done for its autonomous database and other data services has resulted in a very dynamic storage performance that can affect its IOPS performance, so the harder your messaging is working, the faster the I/O will go. This means that the broker is no longer the point of vulnerability to sudden dynamic workload fluctuations and won’t create application back pressure because it can’t service the scaled application’s requests to send or receive messages even if the connection between brokers was to become a bandwidth choke point.
In addition to the autoscaling storage, Solace provides an Arm build of PubSub+, which means that an OCI deployment can take advantage of the Ampere compute with its cost performance profile, delivering a lot of savings.
Conclusion
Solace’s PubSub+ offering, which includes a free tier (standard edition of the software event broker), provides some amazing opportunities for multi-cloud capabilities without needing to change applications. Furthermore, if you try PubSub+, have a look at the OCI performance capabilities, particularly if you’re applying a hub and spoke architecture (an option if the applications are using local cloud native messaging) – even if OCI only becomes your hub.
Learn More
To learn more about OCI and Solace, try these resources:
Opinions expressed by DZone contributors are their own.
Comments