Mastering Safe Production Deployments
Ensure smooth and safe production deployments by following best practices like PR-based deployments, thorough testing, feature flags, and proactive rollback strategies.
Join the DZone community and get the full member experience.
Join For FreeDeploying software into production is one of the most crucial activities in the software development lifecycle. It’s a moment of both excitement and risk — excitement because new features and fixes are being released to users and risk because any misstep can lead to downtime, bugs, or poor user experiences. In this blog, I will walk through the best practices for ensuring safe and smooth production deployments, tailored primarily for experienced software engineers.
In this article, we’ll dive into strategies for mitigating deployment risks, optimizing team efficiency, increasing deployment frequency, and improving the overall software delivery process.
The Problem With Traditional Deployment Models
Traditionally, many teams assign the on-call engineer or service engineering teams to handle production deployments. While this approach ensures accountability, it brings several issues to the surface:
Overload and Bottlenecks
If the on-call engineer/service engineer is busy resolving critical issues, deployments can be delayed, often resulting in the deployment of several days/weeks’ worth of changes at once.
Context Switching
The on-call engineer may not be familiar with the details of each change, requiring pull request (PR) authors to validate their changes post-deployment. This distracts developers from their ongoing tasks where they wrapped up a task a few days ago but then suddenly need to drop everything and validate an old change.
Rollback Challenges
If multiple PRs are deployed simultaneously, a problem with one PR might force a rollback of all changes, including those unrelated to the faulty code.
These issues highlight the need for an optimized deployment process that minimizes risk and maximizes efficiency.
Best Practices for Safe Production Deployments
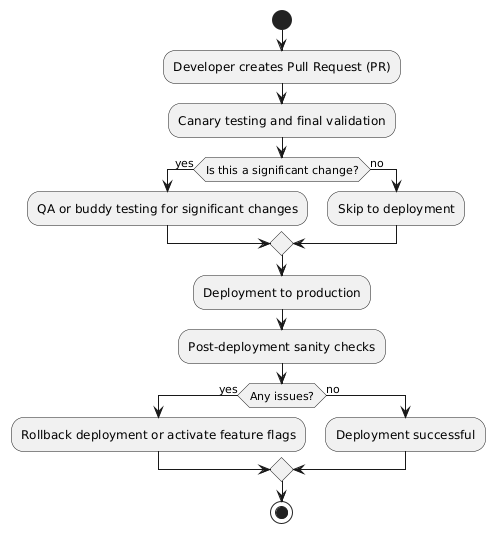
To address these challenges, here are some of the recommended best practices for safe production deployments.
1. Deploy Per Pull Request (PR)
One of the most effective strategies is to shift the responsibility for deployments from the on-call engineer/ a separate team to the PR author. This practice ensures that:
- The author, who has the most context about the changes, is responsible for final validation and post-deployment monitoring.
- The PR author avoids context switching, as they are already familiar with the changes, making the process smoother and faster.
This change also reduces the risk of deploying multiple PRs together, as each PR is deployed individually, simplifying rollback scenarios if an issue arises. Based on the context/service, such deployments per PR can also be automated where the change instantly goes to production after a merge, and the author is only responsible for the final validation.
2. Final Validation on the Deployment Artifact
Even if a PR has been tested in canary or staging environments, it is crucial to perform the final validation on the actual artifact being deployed to production. Chances are that the change itself works as expected on its own, but another conflicting feature was merged right after/before the primary change breaks functionality. Doing the final validation on the exact artifact that will be deployed to production ensures that any new changes in the main branch, which might interact with your code, do not introduce unforeseen issues.
3. Buddy Testing and QA Validation
For significant changes, end-to-end (E2E) testing becomes vital. While component testing is important, it’s equally critical to test how the changes affect the entire system. Additionally, leveraging buddy testing — where another team member reviews and tests your changes — can catch blind spots.
A practical approach is to assign QA buddies on a per-person or per-sprint basis to streamline this process and ensure thorough validation.
4. Sanity Validation Post-Deployment
After deployment, sanity validation is always performed in the production environment. This includes:
- Verifying that the deployed changes work as expected.
- Monitoring alerts and logs through tools like Slack, SignalFX, or Sentry to catch issues early.
- Rolling back immediately if any significant problems arise.
5. Avoid Deploying During Risky Times
Deployments should not happen during non-business hours, before extended weekends, or late evenings, as this increases the chances of issues going unnoticed until on-call engineers are unavailable. If there’s an urgent need to deploy at these times, ensure:
- At least one other team member is closely aware of the changes.
- The on-call engineer is fully on board with the decision.
6. Always Favor Rollbacks for Issue Mitigation
When issues arise post-deployment, the first course of action should be to roll back to the previous stable state. Even if this means rolling back other deployed changes, it is often safer than applying a quick fix in production, especially without thorough QA validation.
If a rollback isn’t possible due to irreversible changes (e.g., schema updates), make sure any emergency fixes undergo proper QA and staging validation.
7. Use Feature Flags for Critical Changes
Feature flags are your best friend when deploying large or risky changes. This approach allows you to:
- Deploy your code with the feature flag turned off, enabling you to gradually turn it on as you verify system stability.
- Gradually increase the load on dependent services.
- Use the feature flag as a kill switch if things go awry, allowing for rapid rollback without affecting other code.
8. Plan for Rollback-Friendly Deployments
Before any deployment, ask: can this be safely rolled back? Consider potential risks, such as changes to the database schema or cache structure. If rollback isn’t feasible, carefully plan how to mitigate potential failures, such as by using feature flags or additional testing in staging environments. Also, consider the option to auto-rollback if certain success metrics are not met. This can be combined with auto-canaries, where a change initially only goes to a certain percentage of the main audience and is rolled out to the full production set only if the success metrics from the canary look good.
Conclusion
Deploying software to production is a high-stakes operation, but adopting these best practices can significantly reduce the risk of failure and increase your team’s deployment confidence. These strategies — deploying per PR, leveraging buddy testing, using feature flags, and always planning for rollback—empower engineers to move fast without breaking things.
Opinions expressed by DZone contributors are their own.
Comments