Making Spring AI and OpenAI GPT Useful With RAG on Your Own Documents
Discover how to use RAG to improve your document search experience with Spring AI and OpenAI GPT. Learn how to make your own documents more useful.
Join the DZone community and get the full member experience.
Join For FreeThe AIDocumentLibraryChat project uses the Spring AI project with OpenAI to search in a document library for answers to questions. To do that, Retrieval Augmented Generation is used on the documents.
Retrieval Augmented Generation
The process looks like this:
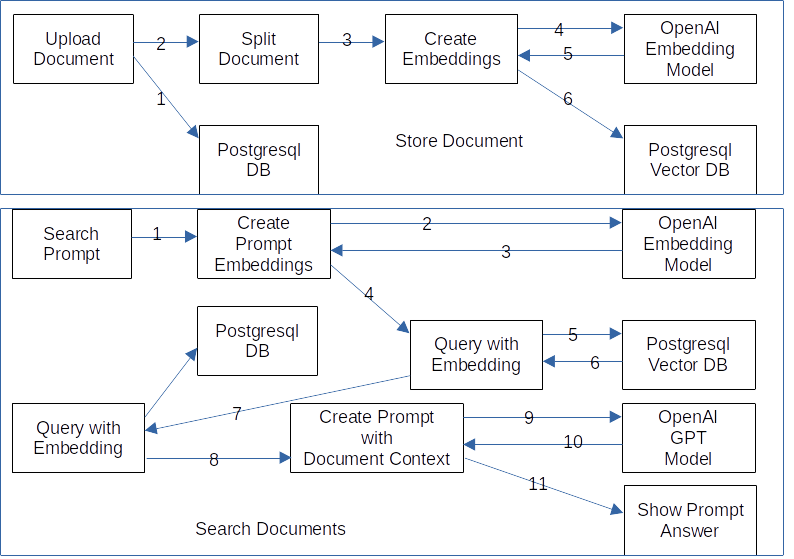
The process looks like this:
- Upload Document
- Store Document in Postgresql DB.
- Split Document to create Embeddings.
- Create Embeddings with a call to the OpenAI Embedding Model.
- Store the Document Embeddings in the Postgresql Vector DB.
Search Documents:
- Create Search Prompt
- Create Embedding of the Search Prompt with a call to the OpenAI Embedding Model.
- Query the Postgresql Vector DB for documents with nearest Embedding distances.
- Query Postgresql DB for Document.
- Create Prompt with the Search Prompt and the Document text chunk.
- Request an answer from GPT Model and show the answer based on the search prompt and the Document text chunk.
Document Upload
The uploaded document is stored in the database to have the source document of the answer. The document text has to be split in chunks to create embeddings per chunk. The embeddings are created by an embedding model of OpenAI and are a vectors with more than 1500 dimensions to represent the text chunk. The embedding is stored in an AI document with the chunk text and the id of the source document in the vector database.
Document Search
The document search takes the search prompt and uses the Open AI embedding model to turn it in an embedding. The embedding is used to search in the vector database for the nearest neighbor vector. That means that the embeddings of search prompt and the text chunk that have the biggest similarities. The id in the AIDocument is used to read the document of the relational database. With the Search Prompt and the text chunk of the AIDocument, the Document Prompt created. Then, the OpenAI GPT model is called with the prompt to create an answer based on Search Prompt and the document context. That causes the model to create answers that are closely based on the documents provided and improves the accuracy. The answer of the GPT model is returned and displayed with a link of the document to provide the source of the answer.
Architecture

The architecture of the project is built around Spring Boot with Spring AI. The Angular UI provides the user interface to show the document list, upload the documents and provide the Search Prompt with the answer and the source document. It communicates with the Spring Boot backend via the rest interface. The Spring Boot backend provides the rest controllers for the frontend and uses Spring AI to communicate with the OpenAI models and the Postgresql Vector database. The documents are stored with Jpa in the Postgresql Relational database. The Postgresql database is used because it combines the relational database and the vector database in a Docker image.
Implementation
Frontend
The frontend is based on lazy loaded standalone components build with Angular. The lazy loaded standalone components are configured in the app.config.ts:
export const appConfig: ApplicationConfig = {
providers: [provideRouter(routes), provideAnimations(), provideHttpClient()]
};The configuration sets the routes and enables the the http client and the animations.
The lazy loaded routes are defined in app.routes.ts:
export const routes: Routes = [
{
path: "doclist",
loadChildren: () => import("./doc-list").then((mod) => mod.DOCLIST),
},
{
path: "docsearch",
loadChildren: () => import("./doc-search").then((mod) => mod.DOCSEARCH),
},
{ path: "**", redirectTo: "doclist" },
];In 'loadChildren' the 'import("...").then((mod) => mod.XXX)' loads the the route lazily from the provided path and sets the exported routes defined in the 'mod.XXX' constant.
The lazy loaded route 'docsearch' has the index.ts to export the constant:
export * from "./doc-search.routes";That exports the doc-search.routes.ts:
export const DOCSEARCH: Routes = [
{
path: "",
component: DocSearchComponent,
},
{ path: "**", redirectTo: "" },
];It defines the routing to the 'DocSearchComponent'.
The fileupload can be found in the DocImportComponent with the template doc-import.component.html:
<h1 mat-dialog-title i18n="@@docimportImportFile">Import file</h1>
<div mat-dialog-content>
<p i18n="@@docimportFileToImport">File to import</p>
@if(uploading) {
<div class="upload-spinner"><mat-spinner></mat-spinner></div>
} @else {
<input type="file" (change)="onFileInputChange($event)">
}
@if(!!file) {
<div>
<ul>
<li>Name: {{file.name}}</li>
<li>Type: {{file.type}}</li>
<li>Size: {{file.size}} bytes</li>
</ul>
</div>
}
</div>
<div mat-dialog-actions>
<button mat-button (click)="cancel()" i18n="@@cancel">Cancel</button>
<button mat-flat-button color="primary" [disabled]="!file || uploading"
(click)="upload()" i18n="@@docimportUpload">Upload</button>
</div>The fileupload is done with the '<input type="file" (change)="onFileInputChange($event)">' tag. It provides the upload feature and calls the 'onFileInputChange(...)' method after each upload.
The 'Upload' button calls the 'upload()' method to send the file to the server on click.
The doc-import.component.ts has methods for the template:
@Component({
selector: 'app-docimport',
standalone: true,
imports: [CommonModule,MatFormFieldModule, MatDialogModule,MatButtonModule, MatInputModule, FormsModule, MatProgressSpinnerModule],
templateUrl: './doc-import.component.html',
styleUrls: ['./doc-import.component.scss']
})
export class DocImportComponent {
protected file: File | null = null;
protected uploading = false;
private destroyRef = inject(DestroyRef);
constructor(private dialogRef: MatDialogRef<DocImportComponent>,
@Inject(MAT_DIALOG_DATA) public data: DocImportComponent,
private documentService: DocumentService) { }
protected onFileInputChange($event: Event): void {
const files = !$event.target ? null :
($event.target as HTMLInputElement).files;
this.file = !!files && files.length > 0 ?
files[0] : null;
}
protected upload(): void {
if(!!this.file) {
const formData = new FormData();
formData.append('file', this.file as Blob, this.file.name as string);
this.documentService.postDocumentForm(formData)
.pipe(tap(() => {this.uploading = true;}),
takeUntilDestroyed(this.destroyRef))
.subscribe(result => {this.uploading = false;
this.dialogRef.close();});
}
}
protected cancel(): void {
this.dialogRef.close();
}
}This is the standalone component with its module imports and the injected 'DestroyRef'.
The 'onFileInputChange(...)' method takes the event parameter and stores its 'files' property in the 'files' constant. Then it checks for the first file and stores it in the 'file' component property.
The 'upload()' method checks for the 'file' property and creates the 'FormData()' for the file upload. The 'formData' constant has the datatype ('file'), the content ('this.file') and the filename ('this.file.name') appended. Then the 'documentService' is used to post the 'FormData()' object to the server. The 'takeUntilDestroyed(this.destroyRef)' function unsubscribes the Rxjs pipeline after the component is destroyed. That makes unsubscribing pipelines very convenient in Angular.
Backend
The backend is a Spring Boot application with the Spring AI framework. Spring AI manages the requests to the OpenAI models and the Vector Database Requests.
Liquibase Database setup
The database setup is done with Liquibase and the script can be found in the db.changelog-1.xml:
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<changeSet id="1" author="angular2guy">
<sql>CREATE EXTENSION if not exists hstore;</sql>
</changeSet>
<changeSet id="2" author="angular2guy">
<sql>CREATE EXTENSION if not exists vector;</sql>
</changeSet>
<changeSet id="3" author="angular2guy">
<sql>CREATE EXTENSION if not exists "uuid-ossp";</sql>
</changeSet>
<changeSet author="angular2guy" id="4">
<createTable tableName="document">
<column name="id" type="bigint">
<constraints primaryKey="true"/>
</column>
<column name="document_name" type="varchar(255)">
<constraints notNullConstraintName="document_document_name_notnull"
nullable="false"/>
</column>
<column name="document_type" type="varchar(25)">
<constraints notNullConstraintName="document_document_type_notnull"
nullable="false"/>
</column>
<column name="document_content" type="blob"/>
</createTable>
</changeSet>
<changeSet author="angular2guy" id="5">
<createSequence sequenceName="document_seq" incrementBy="50"
startValue="1000" />
</changeSet>
<changeSet id="6" author="angular2guy">
<createTable tableName="vector_store">
<column name="id" type="uuid"
defaultValueComputed="uuid_generate_v4 ()">
<constraints primaryKey="true"/>
</column>
<column name="content" type="text"/>
<column name="metadata" type="json"/>
<column name="embedding" type="vector(1536)">
<constraints notNullConstraintName=
"vectorstore_embedding_type_notnull" nullable="false"/>
</column>
</createTable>
</changeSet>
<changeSet id="7" author="angular2guy">
<sql>CREATE INDEX vectorstore_embedding_index ON vector_store
USING HNSW (embedding vector_cosine_ops);</sql>
</changeSet>
</databaseChangeLog>In the changeset 4 the table for the Jpa document entity is created with the primary key 'id'. The content type/size is unknown and because of that set to 'blob'. I changeset 5 the sequence for the Jpa entity is created with the default properties of Hibernate 6 sequences that are used by Spring Boot 3.x.
In changeset 6 the table 'vector_store' is created with a primary key 'id' of type 'uuid' that is created by the 'uuid-ossp' extension. The column 'content' is of type 'text'('clob' in other databases) to has a flexible size. The 'metadata' column stores the metadata in a 'json' type for the AIDocuments. The 'embedding' column stores the embedding vector with the number of OpenAI dimensions.
In changeset 7 the index for the fast search of the 'embeddings' column is set. Due to limited parameters of the Liquibase '<createIndex ...>' '<sql>' is used directly to create it.
Spring Boot / Spring AI implementation
The DocumentController for the frontend looks like this:
@RestController
@RequestMapping("rest/document")
public class DocumentController {
private final DocumentMapper documentMapper;
private final DocumentService documentService;
public DocumentController(DocumentMapper documentMapper,
DocumentService documentService) {
this.documentMapper = documentMapper;
this.documentService = documentService;
}
@PostMapping("/upload")
public long handleDocumentUpload(
@RequestParam("file") MultipartFile document) {
var docSize = this.documentService
.storeDocument(this.documentMapper.toEntity(document));
return docSize;
}
@GetMapping("/list")
public List<DocumentDto> getDocumentList() {
return this.documentService.getDocumentList().stream()
.flatMap(myDocument ->Stream.of(this.documentMapper.toDto(myDocument)))
.flatMap(myDocument -> {
myDocument.setDocumentContent(null);
return Stream.of(myDocument);
}).toList();
}
@GetMapping("/doc/{id}")
public ResponseEntity<DocumentDto> getDocument(
@PathVariable("id") Long id) {
return ResponseEntity.ofNullable(this.documentService
.getDocumentById(id).stream().map(this.documentMapper::toDto)
.findFirst().orElse(null));
}
@GetMapping("/content/{id}")
public ResponseEntity<byte[]> getDocumentContent(
@PathVariable("id") Long id) {
var resultOpt = this.documentService.getDocumentById(id).stream()
.map(this.documentMapper::toDto).findFirst();
var result = resultOpt.stream().map(this::toResultEntity)
.findFirst().orElse(ResponseEntity.notFound().build());
return result;
}
private ResponseEntity<byte[]> toResultEntity(DocumentDto documentDto) {
var contentType = switch (documentDto.getDocumentType()) {
case DocumentType.PDF -> MediaType.APPLICATION_PDF;
case DocumentType.HTML -> MediaType.TEXT_HTML;
case DocumentType.TEXT -> MediaType.TEXT_PLAIN;
case DocumentType.XML -> MediaType.APPLICATION_XML;
default -> MediaType.ALL;
};
return ResponseEntity.ok().contentType(contentType)
.body(documentDto.getDocumentContent());
}
@PostMapping("/search")
public DocumentSearchDto postDocumentSearch(@RequestBody
SearchDto searchDto) {
var result = this.documentMapper
.toDto(this.documentService.queryDocuments(searchDto));
return result;
}
}The 'handleDocumentUpload(...)' handles the uploaded file with the 'documentService' at the '/rest/document/upload' path.
The 'getDocumentList()' handles the get requests for the document lists and removes the document content to save on the response size.
The 'getDocumentContent(...)' handles the get requests for the document content. It loads the document with the 'documentService' and maps the 'DocumentType' to the 'MediaType'. Then it returns the content and the content type, and the browser opens the content based on the content type.
The 'postDocumentSearch(...)' method puts the request content in the 'SearchDto' object and returns the AI generated result of the 'documentService.queryDocuments(...)' call.
The method 'storeDocument(...)' of the DocumentService looks like this:
public Long storeDocument(Document document) {
var myDocument = this.documentRepository.save(document);
Resource resource = new ByteArrayResource(document.getDocumentContent());
var tikaDocuments = new TikaDocumentReader(resource).get();
record TikaDocumentAndContent(org.springframework.ai.document.Document
document, String content) { }
var aiDocuments = tikaDocuments.stream()
.flatMap(myDocument1 -> this.splitStringToTokenLimit(
myDocument1.getContent(), CHUNK_TOKEN_LIMIT)
.stream().map(myStr -> new TikaDocumentAndContent(myDocument1, myStr)))
.map(myTikaRecord -> new org.springframework.ai.document.Document(
myTikaRecord.content(), myTikaRecord.document().getMetadata()))
.peek(myDocument1 -> myDocument1.getMetadata()
.put(ID, myDocument.getId().toString())).toList();
LOGGER.info("Name: {}, size: {}, chunks: {}", document.getDocumentName(),
document.getDocumentContent().length, aiDocuments.size());
this.documentVsRepository.add(aiDocuments);
return Optional.ofNullable(myDocument.getDocumentContent()).stream()
.map(myContent -> Integer.valueOf(myContent.length).longValue())
.findFirst().orElse(0L);
}
private List<String> splitStringToTokenLimit(String documentStr,
int tokenLimit) {
List<String> splitStrings = new ArrayList<>();
var tokens = new StringTokenizer(documentStr).countTokens();
var chunks = Math.ceilDiv(tokens, tokenLimit);
if (chunks == 0) {
return splitStrings;
}
var chunkSize = Math.ceilDiv(documentStr.length(), chunks);
var myDocumentStr = new String(documentStr);
while (!myDocumentStr.isBlank()) {
splitStrings.add(myDocumentStr.length() > chunkSize ?
myDocumentStr.substring(0, chunkSize) : myDocumentStr);
myDocumentStr = myDocumentStr.length() > chunkSize ?
myDocumentStr.substring(chunkSize) : "";
}
return splitStrings;
}The 'storeDocument(...)' method saves the document to the relational database. Then, the document is converted in a 'ByteArrayResource' and read with the 'TikaDocumentReader' of Spring AI to turn it in a AIDocument list. Then the AIDocument list is flatmapped to split the documents into chunks with the the 'splitToTokenLimit(...)' method that are turned in new AIDocuments with the 'id' of the stored document in the Metadata map. The 'id' in the Metadata enables loading the matching document entity for the AIDocuments. Then the embeddings for the AIDocuments are created implicitly with calls to the 'documentVsRepository.add(...)' method that calls the OpenAI Embedding model and stores the AIDocuments with the embeddings in the vector database. Then the result is returned.
The method 'queryDocument(...)' looks like this:
public AiResult queryDocuments(SearchDto searchDto) {
var similarDocuments = this.documentVsRepository
.retrieve(searchDto.getSearchString());
var mostSimilar = similarDocuments.stream()
.sorted((myDocA, myDocB) -> ((Float) myDocA.getMetadata().get(DISTANCE))
.compareTo(((Float) myDocB.getMetadata().get(DISTANCE)))).findFirst();
var documentChunks = mostSimilar.stream().flatMap(mySimilar ->
similarDocuments.stream().filter(mySimilar1 ->
mySimilar1.getMetadata().get(ID).equals(
mySimilar.getMetadata().get(ID)))).toList();
Message systemMessage = switch (searchDto.getSearchType()) {
case SearchDto.SearchType.DOCUMENT -> this.getSystemMessage(
documentChunks, (documentChunks.size() <= 0 ? 2000
: Math.floorDiv(2000, documentChunks.size())));
case SearchDto.SearchType.PARAGRAPH ->
this.getSystemMessage(mostSimilar.stream().toList(), 2000);
};
UserMessage userMessage = new UserMessage(searchDto.getSearchString());
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
LocalDateTime start = LocalDateTime.now();
AiResponse response = aiClient.generate(prompt);
LOGGER.info("AI response time: {}ms",
ZonedDateTime.of(LocalDateTime.now(),
ZoneId.systemDefault()).toInstant().toEpochMilli()
- ZonedDateTime.of(start, ZoneId.systemDefault()).toInstant()
.toEpochMilli());
var documents = mostSimilar.stream().map(myGen ->
myGen.getMetadata().get(ID)).filter(myId ->
Optional.ofNullable(myId).stream().allMatch(myId1 ->
(myId1 instanceof String))).map(myId ->
Long.parseLong(((String) myId)))
.map(this.documentRepository::findById)
.filter(Optional::isPresent)
.map(Optional::get).toList();
return new AiResult(searchDto.getSearchString(),
response.getGenerations(), documents);
}
private Message getSystemMessage(
List<org.springframework.ai.document.Document> similarDocuments,
int tokenLimit) {
String documents = similarDocuments.stream()
.map(entry -> entry.getContent())
.filter(myStr -> myStr != null && !myStr.isBlank())
.map(myStr -> this.cutStringToTokenLimit(myStr, tokenLimit))
.collect(Collectors.joining("\n"));
SystemPromptTemplate systemPromptTemplate =
new SystemPromptTemplate(this.systemPrompt);
Message systemMessage = systemPromptTemplate
.createMessage(Map.of("documents", documents));
return systemMessage;
}
private String cutStringToTokenLimit(String documentStr, int tokenLimit) {
String cutString = new String(documentStr);
while (tokenLimit < new StringTokenizer(cutString, " -.;,").countTokens()){
cutString = cutString.length() > 1000 ?
cutString.substring(0, cutString.length() - 1000) : "";
}
return cutString;
}The method first loads the documents best matching the 'searchDto.getSearchString()' from the vector database. To do that the OpenAI Embedding model is called to turn the search string into an embedding and with that embedding the vector database is queried for the AIDocuments with the lowest distance(the distance between the vectors of the search embedding and the database embedding). Then the AIDocument with the lowest distance is stored in the 'mostSimilar' variable. Then all the AIDocuments of the document chunks are collected by matching the document entity id of their Metadata 'id's. The 'systemMessage' is created with the 'documentChunks' or the 'mostSimilar' content. The 'getSystemMessage(...)' method takes them and cuts the contentChunks to a size that the OpenAI GPT models can handle and returns the 'Message'. Then the 'systemMessage' and the 'userMessage' are turned into a 'prompt' that is send with 'aiClient.generate(prompt)' to the OpenAi GPT model. After that the AI answer is available and the document entity is loaded with the id of the metadata of the 'mostSimilar' AIDocument. The 'AiResult' is created with the search string, the GPT answer, the document entity and is returned.
The vector database repository DocumentVsRepositoryBean with the Spring AI 'VectorStore' looks like this:
@Repository
public class DocumentVSRepositoryBean implements DocumentVsRepository {
private final VectorStore vectorStore;
public DocumentVSRepositoryBean(JdbcTemplate jdbcTemplate,
EmbeddingClient embeddingClient) {
this.vectorStore = new PgVectorStore(jdbcTemplate, embeddingClient);
}
public void add(List<Document> documents) {
this.vectorStore.add(documents);
}
public List<Document> retrieve(String query, int k, double threshold) {
return new VectorStoreRetriever(vectorStore, k,
threshold).retrieve(query);
}
public List<Document> retrieve(String query) {
return new VectorStoreRetriever(vectorStore).retrieve(query);
}
}The repository has the 'vectorStore' property that is used to access the vector database. It is created in the constructor with the injected parameters with the 'new PgVectorStore(...)' call. The PgVectorStore class is provided as the Postgresql Vector database extension. It has the 'embeddingClient' to use the OpenAI Embedding model and the 'jdbcTemplate' to access the database.
The method 'add(...)' calls the OpenAI Embedding model and adds AIDocuments to the vector database.
The methods 'retrieve(...)' query the vector database for embeddings with the lowest distances.
Conclusion
Angular made the creation of the front end easy. The standalone components with lazy loading have made the initial load small. The Angular Material components have helped a lot with the implementation and are easy to use.
Spring Boot with Spring AI has made the use of Large Language Models easy. Spring AI provides the framework to hide the creation of embeddings and provides an easy-to-use interface to store the AIDocuments in a vector database(several are supported). The creation of the embedding for the search prompt to load the nearest AIDocuments is also done for you and the interface of the vector database is simple. The Spring AI prompt classes make the creation of the prompt for the OpenAI GPT models also easy. Calling the model is done with the injected 'aiClient,' and the results are returned.
Spring AI is a very good Framework from the Spring Team. There have been no problems with the experimental version.
With Spring AI, the Large Language Models are now easy to use on our own documents.
Opinions expressed by DZone contributors are their own.
Comments