Lost in Translation: Gaps of GPT-3.5 in South Asian and Middle Eastern Languages
This article reveals disparities in performance, including grammatical errors and inappropriate tone, in responses to non-English prompts in LLMs like GPT-3.5.
Join the DZone community and get the full member experience.
Join For FreeLarge language models have made remarkable advancements in recent years. However, much of this progress has centered on English language tasks, with less attention to non-English languages. It is a missed opportunity as these languages represent some of the fastest-growing economies. In our analysis of the capabilities of GPT-3.5 on non-English prompts, specifically South Asian and Middle Eastern languages, we uncovered disparities. While performance on English language prompts continues to impress, responses to prompts in other languages surface grammatical errors, inappropriate tone, and factual inaccuracies.
Our study shows that LLMs (GPT-3.5) are 2x slower if the prompt is not in English. Also, the quality of response degrades compared to instruction-following performance in English. As large language models move towards broader multilingual availability, these deficiencies demand urgent attention to support business expansion worldwide and capture more significant customer adoption.
Excluding millions of non-English speakers from enjoying the benefits of these powerful models forfeits tremendous value. It inhibits education, business expansion, creativity, and human progress across much of the globe. Prioritizing multilingual equity aligns with business imperatives to serve the broadest possible audience and ethical principles of inclusive innovation.
Through expanded datasets, targeted model architecture changes, and refinement of underlying linguistics, we can collectively work to make the promise of large language models generally universal. Our shared goal must be to empower all people, regardless of their native language, to harness these technologies towards human flourishing.
In this article, we show that a simple manual translation layer improves LLMs' response quality to non-English prompts as well as English prompts. It can democratize information access, enhance LLM performance across diverse languages, and truly globalize the benefits of AI. Additionally, this article delves deep into the power of translation integrations, promising to revolutionize how we communicate and engage with AI, breaking linguistic barriers and bridging global communities like never before.
Millions of users use ChatGPT across the globe as an everyday companion. The tool's ability to converse in natural language format makes users feel like they have a second brain that is aided by increasing the efficiency of tasks and provides human-like support. Some of the scenarios/questions where ChatGPT is used are:
- General knowledge questions (What is the surface temperature of Mars?)
- Homework help (Help me write an essay about algae and fungi)
- Life advice (How do I improve my mental health)
- Creative writing (Write a short story about dragons and unicorns)
- Procedural or how-to questions (Give me a detailed step-by-step method to brew green tea)
Linguistic Challenges in South Asian and Middle Eastern Languages
South Asian and Middle Eastern languages are rich in cultural nuances and unique linguistic features that pose significant challenges for machine learning models like GPT-3.5. These languages often have complex grammar structures, diverse dialects, and unique writing systems vastly different from English and other widely supported languages. As a result, GPT-3.5 needs help to accurately comprehend and translate these languages, leading to a loss of meaning and context.
One of the main challenges lies in the lack of training data available for South Asian and Middle Eastern languages. GPT-3.5's performance heavily relies on the vast amount of data it has been trained on, and the scarcity of high-quality training data for these languages hampers its ability to understand and generate text effectively. Additionally, the cultural diversity within these regions further compounds the linguistic challenges, as GPT-3.5 may need to capture the subtle nuances and context-specific meanings crucial for accurate translation.
The Importance of Accurate Translation in These Languages
Today, most LLMs are focused on the English language, but there is a whole list of South Asian and Middle Eastern languages that are important for trade and the economy. These regions have populations in the millions and serve as critical markets for any business worldwide to expand. To communicate with the customers and partners in these regions, it is essential to have effective and efficient translation tools to converse and exchange intended information.
Given the sensitivity of the languages and the sentiment they carry, it is crucial to communicate effectively in the business world, as inaccurate translations will lead to degradation of brand value, loss of trust, and legal concerns. The LLMs must also understand the cultural nuances that come with the languages. These actions will bridge the gap in translating non-English languages using LLM.
Business Use Case of Non-English-Focused Large Language Models (LLMs) Across Various Sectors
Non-English LLMs have the potential to impact various industries worldwide significantly. The use of AI for generating text, engaging in conversations in local languages, translating content, and creating localized speech or video can facilitate personalized content creation. This expansion can foster increased cross-country trade collaboration, promote cross-cultural cooperation, and generate localization jobs that contribute to economic growth in developing nations. Here are a few examples:
- Media entertainment: AI can create personalized content, e.g., convert existing movies, TV shows, and books into local languages at low cost and expand the reach while increasing revenue.
- Retail e-commerce: AI solutions backed by LLM can be used to create localized product listings, images that meet local trends, and product descriptions in local languages — this will increase customer satisfaction and product sales in new and existing markets.
- Banking and finance: AI can convert financial documents and services like customer service and platforms into local language. This can help increase the global flow of capital.
- Healthcare: AI can convert medical documents and enable easy reach to products such as predictive healthcare of typical diseases to under-deserved populations, increasing affordability and providing healthcare access to all. This will make it easier for all health practitioners worldwide to support and care without language barriers.
- Education: LLMs can translate education materials, create personalized learning, and provide quality education for everyone across the globe. This will enable innovation and technological advancement as education can now reach all parts of the world without language barriers.
- Politics and government: AI solutions can be used to translate and cater to all the citizens of a given nation. This will enable transparency and provide diverse citizens access to government documents.
Limitations of GPT-3.5 in Understanding Cultural Nuances
Currently, GPT-3.5 is one of the most powerful LLMs. However, it still struggles to capture the cultural and ethnic nuances of South Asian and Middle Eastern languages. The culture of any region plays a critical role in language evolution. For example, proverbs are deeply rooted in a given region's day-to-day lifestyle and culture. When a model translates these expressions, they are likely to lose their authenticity and intended meaning. Hence, adding a layer of this nuanced culture along with the translation process is critical for the success of LLMs.
Performance of Non-English Prompts
While GPT-3.5 exhibits remarkable capabilities in English, it could be more effective when dealing with languages such as Arabic, Hindi, Urdu, and Tamil. We used Google Translate to translate the English prompt “Write three paragraphs of 4 lines each about the solar system” and sent the prompt to GPT-3.5.
Table 1: ChatGPT Response to Translated Prompt in South Asian and Middle Eastern Languages
| Language | link | screenshot |
|---|---|---|
| Arabic | Link | 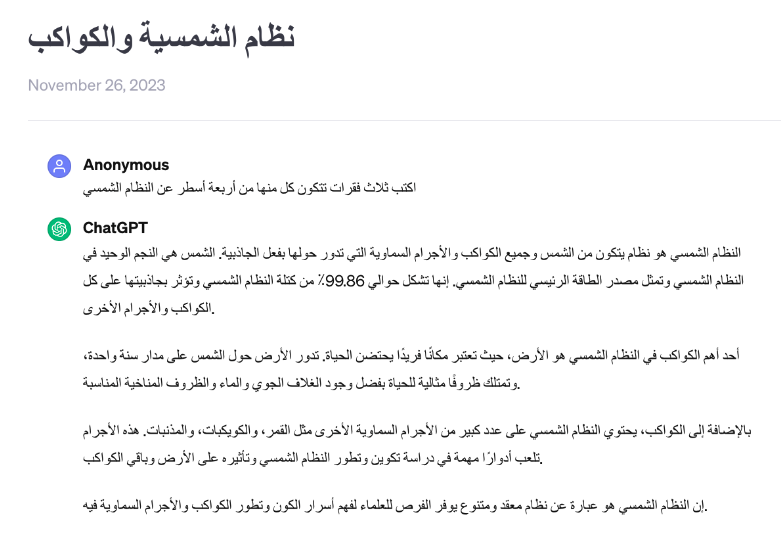 |
| Hindi | Link |  |
| Urdu | Link | 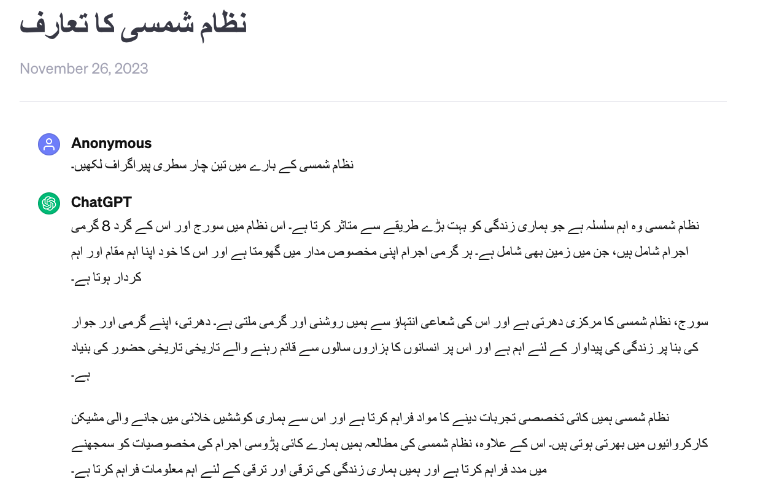 |
| Tamil | Link |  |
From the table, it can be observed that ChatGPT responses did not follow the instructions strictly.
- Regarding Hindi and Urdu, responses have three paragraphs but do not always have four lines.
- For Tamil, the response is just three bullet points.
- For Arabic, there are four paragraphs with varying line counts.
Apart from following the instructions, the quality of the response could be more useful in comparison to the response to the English prompt (link). We also found that inference is 1.5 times slower compared to English prompts. [4]
The leading causes for the lack of non-English support from GPT-3.5 are the following:
- Training data disparity: Quoting directly from Wikipedia, the common crawl dataset that GPT series models use has 46% English, followed by German, Russian, Japanese, French, Spanish, and Chinese, each less than 6%. With fewer examples to learn from, GPT’s understanding of non-English semantics and collective knowledge is poorer.
- Grammatical complexity: South Asian and Middle Eastern languages have complex morphology, case systems, tense rules, etc. These are more challenging for models to handle appropriately in non-English languages. Language-specific enhancements can help.
Steps to Address the Linguistic Gaps in GPT-3.5
Below are some of the ways we can systematically address the linguist gaps in LLMs:
- Extensive set of training data: LLMs should be trained on a large and wide variety of datasets in a given language. This is similar to how we learn by hearing more words and reading more about them. GPT-3.5 needs access to high-quality data for South Asian and Middle Eastern languages.
- Specific fine-tuning based on the language: Similar to how a chef knows the basics of cooking and has specialization in one particular cuisine. It is similar to how a doctor is trained in general medicine or has a degree in general medicine but specializes in a particular body part or disease. To provide an accurate translation, GPT-3.5 and other LLMs need to be trained and fine-tuned on a specific language as its focus is to ingrain the cultural, regional, or ethnic nuances.
- Review and test the results by language experts: Everyone needs a review and second opinion, even if the experts have coaches. Hence, it is crucial to seek review and feedback from native language experts to capture the language's regional and cultural nuances.
- Build dedicated translator models: It is critical to modularize and have individual smaller models focused on particular languages based on the similarity of origin or similarity in the grammar basics. This approach will lead to accurate translation and enable faster development.
Fine-Tuning as a Solution and Business Opportunity
With a billion people not speaking English as their primary language, LLMs needing help to perform similarly to English is a barrier to adoption. ChatGPT adoption outside of the U.S. has room for improvement [3]. One solution could be to build a large language model for every language. However, that might come at the cost of missing a wealth of knowledge available in English. A potential alternative solution could be to develop a translation agent [2] between an extensive language model and the prompt, thereby leveraging the capabilities of existing LLMs without retraining in each language.
[1] Improving the performance of large language models in languages other than English is an active area of research. Fine-tuning a large language model to underrepresented languages is a potential solution to improve the response quality of LLMs. By preparing a comprehensive dataset of underrepresented languages, it’s possible to fine-tune GPT-3.5 and improve its performance in the target language family.
The inference time of LLMs for non-English prompts is also slower than for English prompts. [4] Hence, a middleware layer of translation can help improve response time. The middleware could be as simple as translating from the target language to English and, later, getting the GPT response back to the target language.
GPT-3.5 and Translation Layer Potential Design
Implementing a dedicated middleware layer focused on translation can prove advantageous to address the linguistic gap and improve response times. This layer can consist of three components that will integrate with the GPT-3.5 LLM:
- A translation model: A machine learning model trained to translate text from one language to another
- An encoder: This is a service that takes in an English prompt as input and encodes input that the translation model can understand.
- A decoder: A service that the translation model outputs and converts into a response that the user can understand in their preferred language
The translation layer will take in the non-English prompt and provide a high-quality non-English response at a reduced latency. This design will also improve fluency and accuracy over time as it gets exposed to more non-English audience adoption.
To effectively implement this design, training the translation model on a dataset in the target language is critical. Develop the encoder and decoder services that can be compatible with GPT-3.5 LLM and extendable to other LLMs as needed. Lastly, integrate the translation model to the encoder and decoder and the ChatGPT or Bard interface to make it a seamless single system for the end user.
The Future of Language Models and Their Impact on Cross-Cultural Communication
As technology evolves, language models like GPT-3.5 will undoubtedly improve their capabilities in understanding and translating South Asian and Middle Eastern languages. The advancements in machine learning and natural language processing hold great promise for more accurate and culturally sensitive translations in the future.
With continued research and development, language models are expected to become more inclusive and better equipped to handle the linguistic challenges specific to these regions. It will profoundly impact cross-cultural communication, fostering better understanding and collaboration between individuals and organizations from diverse linguistic and cultural backgrounds.
In addition to enabling and democratizing the usage of LLMs across various non-English-speaking populations, companies worldwide can use this translation LLM to localize their products and services to cater to their local markets. Below are some ways this will accelerate and integrate the products into local markets.
- With chatbots, companies could use the translation layer/LLM to cater to the local population in banking, e-commerce, and restaurants.
- Translate customer support, marketing, and website documentation dynamically.
- Gaming companies can use this translation layer to cater to the local population by having a local language game guide, subtitles, and dialogue.
Similar to the above, this can be extended into healthcare and various other scenarios where ChatGPT, Bard, or LLMs can be applied — thus improving company brand value and expanding business opportunities.
Conclusion: Moving Toward More Inclusive and Accurate Language AI Models
LLMs today are English-dominant and have room for improvement in Asian and Middle Eastern languages. However, training an LLM for a specific language is costly and causes a loss of the wealth of information available in English. Hence, we see an opportunity to fine-tune large language models to the specific language or a family of related languages, making LLMs accessible for a billion more non-English-speaking prompt engineers.
References
[2] "SeamlessM4T—Massively Multilingual & Multimodal Machine Translation ...", ai.meta.com, (Accessed 4 Nov. 2023)
[3] ChatGPT users by region - https://explodingtopics.com/blog/chatgpt-users
[4] https://lablab.ai/event/ai-startup-hackathon-episode-4/polyglot-gpt/polyglot-gpt LLMs are slower with non-English prompts
Opinions expressed by DZone contributors are their own.
Comments