Operationalize a Scalable AI With LLMOps Principles and Best Practices
This deep dive into MLOps and LLMOps looks at key components, practices, tools, and reference architecture with examples.
Join the DZone community and get the full member experience.
Join For FreeOrganizations are fully adopting Artificial Intelligence (AI) and proving that AI is valuable. Enterprises are looking for valuable AI use cases that abound in their industry and functional areas to reap more benefits. Organizations are responding to opportunities and threats, gain improvements in sales, and lower costs. Organizations are recognizing the special requirements of AI workloads and enabling them with purpose-built infrastructure that supports the consolidated demands of multiple teams across the organization. Organizations adopting a shift-left paradigm by planning for good governance early in the AI process will minimize AI efforts for data movement to accelerate model development.
In an era of rapidly evolving AI, data scientists should be flexible in choosing platforms that provide flexibility, collaboration, and governance to maximize adoption and productivity. Let's dive into the workflow automation and pipeline orchestration world. Recently, two prominent terms have appeared in the artificial intelligence and machine learning world: MLOps and LLMOps.
What Is MLOps?
MLOps (Machine Learning Operations) is a set of practices and technology to standardize and streamline the process of construction and deployment of machine learning systems. It covers the entire lifecycle of a machine learning application from data collection to model management. MLOps provides a provision for huge workloads to accelerate time-to-value. MLOps principles are architected based on the DevOps principles to manage applications built-in ML (Machine Learning).
The ML model is created by applying an algorithm to a mass of training data, which will affect the behavior of the model in different environments. Machine learning is not just code, its workflows include the three key assets Code, Model, and Data.
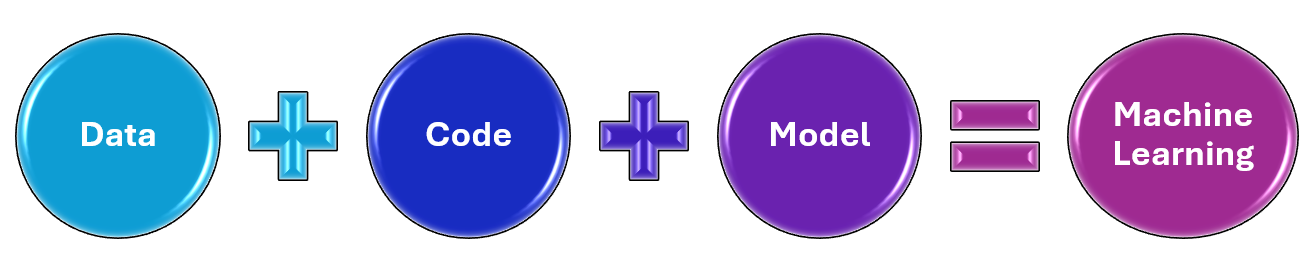
Figure 1: ML solution is comprised of Data, Code, and Model
These assets in the development environment will have the least restrictive access controls and less quality guarantee, while those in production will be the highest quality and tightly controlled. The data is coming from the real world in production where you cannot control its change, and this raises several challenges that need to be resolved. For example:
- Slow, shattered, and inconsistent deployment
- Lack of reproducibility
- Performance reduction (training-serving skew)
To resolve these types of issues, there are combined practices from DevOps, data engineering, and practices unique to machine learning.
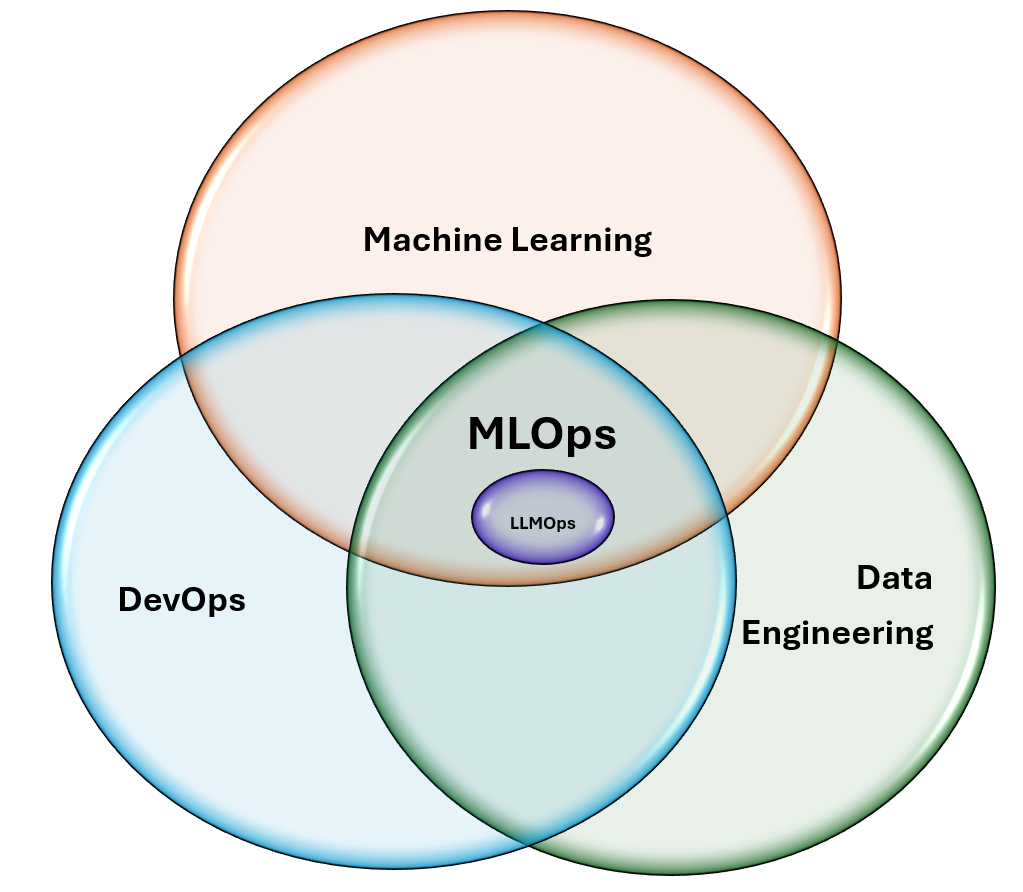
Figure 2: MLOps is the intersection of Machine Learning, DevOps, and Data Engineering - LLMOps rooted in MLOps
Hence, MLOps is a set of practices that combines machine learning, DevOps, and data engineering, which aims to deploy and maintain ML systems in production reliably and efficiently.
What Is LLMOps?
The recent rise of Generative AI with its most common form of large language models (LLMs) prompted us to consider how MLOps processes should be adapted to this new class of AI-powered applications.
LLMOps (Large Language Models Operations) is a specialized subset of MLOps (Machine Learning Operations) tailored for the efficient development and deployment of large language models. LLMOps ensures that model quality remains high and that data quality is maintained throughout data science projects by providing infrastructure and tools.
Use a consolidated MLOps and LLMOps platform to enable close interaction between data science and IT DevOps to increase productivity and deploy a greater number of models into production faster. MLOps and LLMOps will both bring Agility to AI Innovation to the project.
LLMOps tools include MLOps tools and platforms, LLMs that offer LLMOps capabilities, and other tools that can help with fine-tuning, testing, and monitoring. Explore more on LLMOps tools.
Differentiate Tasks Between MLOps and LLMOps
MLOps and LLMOps have two different processes and techniques in their primary tasks. Table 1 shows a few key tasks and a comparison between the two methodologies:
|
Task |
MLOps |
LLMOps |
|
Primary focus |
Developing and deploying machine-learning models |
Specifically focused on LLMs |
|
Model adaptation |
If employed, it typically focuses on transfer learning and retraining. |
Centers on fine-tuning pre-trained models like GPT with efficient methods and enhancing model performance through prompt engineering and retrieval augmented generation (RAG) |
|
Model evaluation |
Evaluation relies on well-defined performance metrics. |
Evaluating text quality and response accuracy often requires human feedback due to the complexity of language understanding (e.g., using techniques like RLHF) |
|
Model management |
Teams typically manage their models, including versioning and metadata. |
Models are often externally hosted and accessed via APIs. |
|
Deployment |
Deploy models through pipelines, typically involving feature stores and containerization. |
Models are part of chains and agents, supported by specialized tools like vector databases. |
|
Monitoring |
Monitor model performance for data drift and model degradation, often using automated monitoring tools. |
Expands traditional monitoring to include prompt-response efficacy, context relevance, hallucination detection, and security against prompt injection threats |
Table 1: Key tasks of MLOPs and LLMOps methodologies
Adapting any implications into MLOps required minimal changes to existing tools and processes. Moreover, many aspects do not change:
- The separation of development, staging, and production remains the same.
- The version control tool and the model registry in the catalog remain the primary channels for promoting pipelines and models toward production.
- The data architecture for managing data remains valid and essential for efficiency.
- Existing CI/CD infrastructure should not require changes.
- The modular structure of MLOps remains the same, with pipelines for model training, model inference, etc., A summary of key properties of LLMs and the implications for MLOps are listed in Table 2.
|
KEY PROPERTIES OF LLMS |
IMPLICATIONS FOR MLOPS |
|---|---|
|
LLMs are available in many forms:
|
Projects often develop incrementally, starting from existing, third-party, or open-source models and ending with custom fine-tuned models. This has an impact on the development process. |
|
Prompt Engineering: Many LLMs take queries and instructions as input in the form of natural language. Those queries can contain carefully engineered “prompts” to elicit the desired responses. |
Designing text templates for querying LLMs is often an important part of developing new LLM pipelines. Many LLM pipelines will use existing LLMs or LLM serving endpoints; the ML logic developed for those pipelines may focus on prompt templates, agents, or “chains” instead of the model itself. The ML artifacts packaged and promoted to production may frequently be these pipelines, rather than models. |
|
Context-based prompt engineering: Many LLMs can be given prompts with examples and context, or additional information to help answer the query. |
When augmenting LLM queries with context, it is valuable to use previously uncommon tooling such as vector databases to search for relevant context. |
|
Model Size: LLMs are very large deep-learning models, often ranging from gigabytes to hundreds of gigabytes. |
Many LLMs may require GPUs for real-time model serving. Since larger models require more computation and are thus more expensive to serve, techniques for reducing model size and computation may be required. |
|
Model evaluation: LLMs are hard to evaluate via traditional ML metrics since there is often no single “right” answer. |
Since human feedback is essential for evaluating and testing LLMs, it must be incorporated more directly into the MLOps process, both for testing and monitoring and for future fine-tuning. |
Table 2: Key properties of LLMs and implications for MLOps
Semantics of Development, Staging, and Production
An ML solution comprises data, code, and models. These assets are developed, tested, and moved to production through deployments. For each of these stages, we also need to operate within an execution environment. Each of the data, code, models, and execution environments is ideally divided into development, staging, and production.
- Data: Some organizations label data as either development, staging, or production, depending on which environment it originated in.
- Code: Machine learning project code is often stored in a version control repository, with most organizations using branches corresponding to the lifecycle phases of development, staging, or production.
- Model: The model and code lifecycle phases often operate asynchronously and model lifecycles do not correspond one-to-one with code lifecycles. Hence it makes sense for model management to have its model registry to manage model artifacts directly. The loose coupling of model artifacts and code provides flexibility to update production models without code changes, streamlining the deployment process in many cases.
- Semantics: Semantics indicates that when it comes to MLOps, there should always be an operational separation between development, staging, and production environments. More importantly, observe that data, code, and model, which we call Assets, in development will have the least restrictive access controls and quality guarantee, while those in production will be the highest quality and tightly controlled.
Deployment Patterns
Two major patterns can be used to manage model deployment.
The training code (Figure 3, deploy pattern code) which can produce the model is promoted toward the production environment after the code is developed in the dev and tested in staging environments using a subset of data.
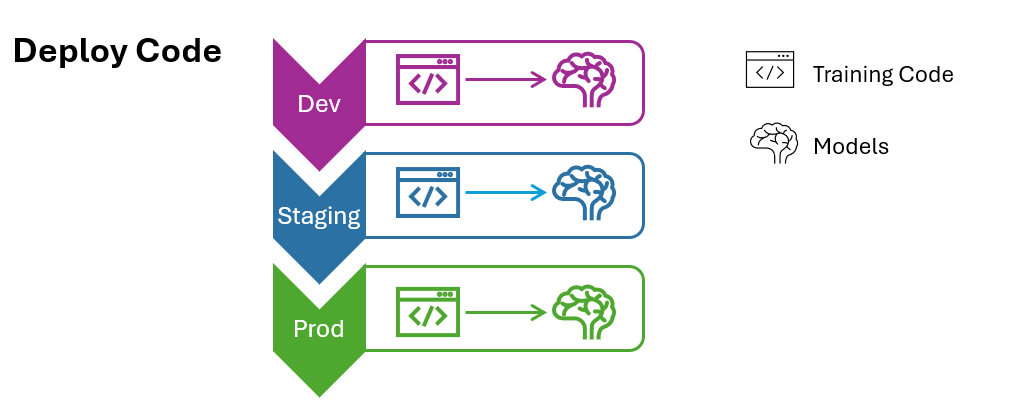
Figure 3: Deploy pattern code
The packaged model (Figure 4, deploy pattern model) is promoted through different environments, and finally to production. Model training is executed in the dev environment. The produced model artifact is then moved to the staging environment for model validation checks, before deployment of the model to the production environment. This approach requires two separate paths, one for deploying ancillary code such as inference and monitoring code and the other “deploy code” path where the code for these components is tested in staging and then deployed to production. This pattern is typically used when deploying a one-off model, or when model training is expensive and read-access to production data from the development environment is possible.
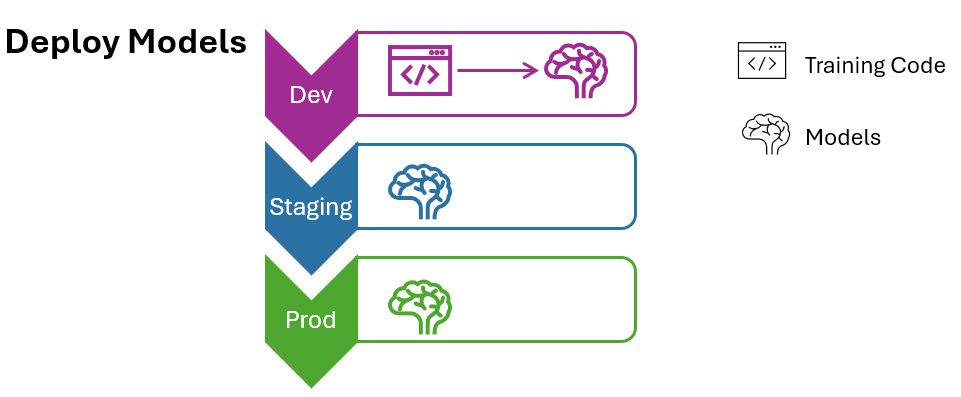
Figure 4: Deploy pattern model
The choice of process will also depend on the business use case, maturity of the machine learning infrastructure, compliance and security guidelines, resources available, and what is most likely to succeed for that particular use case. Therefore, it is a good idea to use standardized project templates and strict workflows. Your decisions around packaging ML logic as version-controlled code vs. registered models will help inform your decision about choosing between the deploy models, deploy code, and hybrid architectures.
With LLMs, it is common to package machine-learning logic in new forms. These may include:
- MLflow can be used to package LLMs and LLM pipelines for deployment.
- Built-in model flavors include:
- PyTorch and TensorFlow
- Hugging Face Transformers (relatedly, see Hugging Face Transformers’ MLflowCallback)
- LangChain
- OpenAI API
- MLflow can package the LLM pipelines via the MLflow Pyfunc capability, which can store arbitrary Python code.
Figure 5 is a machine learning operations architecture and process that uses Azure Databricks.
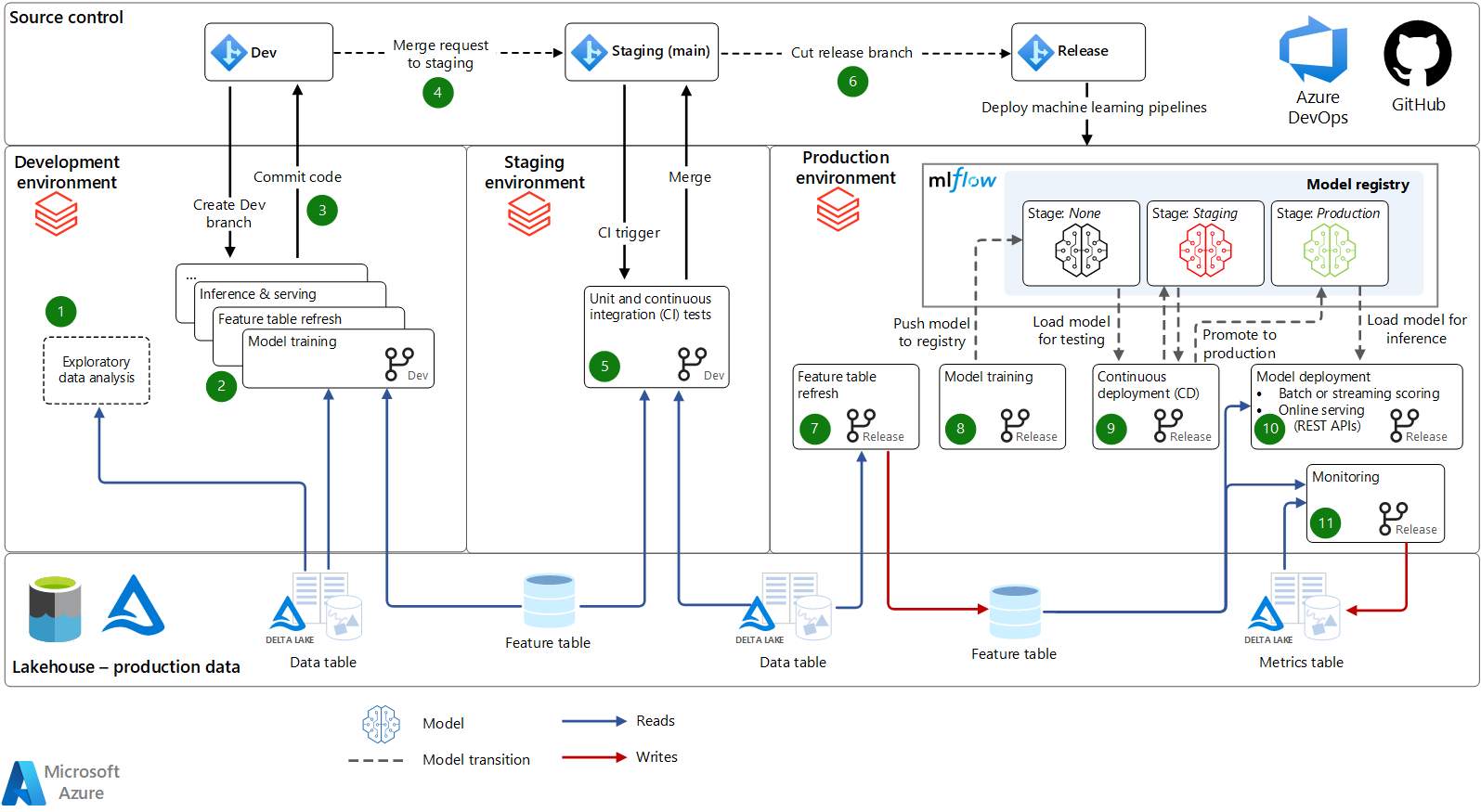
Figure 5: MLOps Architecture (Image source, Azure Databricks)
Key Components of LLM-Powered Applications
The field of LLMOps is quickly evolving. Here are key components and considerations to bear in mind. Some, but not necessarily all of the following approaches make up a single LLM-based application. Any of these approaches can be taken to leverage your data with LLMs.
- Prompt engineering is the practice of adjusting the text prompts given to an LLM to extract more accurate or relevant responses from the model. It is very important to craft effective and specialized prompt templates to guide LLM behavior and mitigate risks such as model hallucination and data leakage. This approach is fast, cost-effective, with no training required, and less control than fine-tuning.
- Retrieval Augmented Generation (RAG), combining an LLM with external knowledge retrieval, requires an external knowledge base or database (e.g., vector database) with moderate training time (e.g., computing embeddings). The primary use case of this approach is dynamically updated context and enhanced accuracy but it significantly increases prompt length and inference computation.
RAG LLMs use two systems to obtain external data:
- Vector databases: Vector databases help find relevant documents using similarity searches. They can either work independently or be part of the LLM application.
- Feature stores: These are systems or platforms to manage and store structured data features used in machine learning and AI applications. They provide organized and accessible data for training and inference processes in machine learning models like LLMs.
- Fine-tuning LLMs: Fine-tuning is the process of adapting a pre-trained LLM on a comparatively smaller dataset that is specific to an individual domain or task. During the fine-tuning process, only a small number of weights are updated, allowing it to learn new behaviors and specialize in certain tasks. The advantage of this approach is granular control, and high specialization but it requires labeled data and comes with a computational cost. The term “fine-tuning” can refer to several concepts, with the two most common forms being:
- Supervised instruction fine-tuning: This approach involves continuing training of a pre-trained LLM on a dataset of input-output training examples - typically conducted with thousands of training examples. Instruction fine-tuning is effective for question-answering applications, enabling the model to learn new specialized tasks such as information retrieval or text generation. The same approach is often used to tune a model for a single specific task (e.g. summarizing medical research articles), where the desired task is represented as an instruction in the training examples.
- Continued pre-training: This fine-tuning method does not rely on input and output examples but instead uses domain-specific unstructured text to continue the same pre-training process (e.g. next token prediction, masked language modeling). This approach is effective when the model needs to learn new vocabulary or a language it has not encountered before.
- Pre-training a model from scratch refers to the process of training a language model on a large corpus of data (e.g. text, code) without using any prior knowledge or weights from an existing model. This is in contrast to fine-tuning, where an already pre-trained model is further adapted to a specific task or dataset. The output of full pre-training is a base model that can be directly used or further fine-tuned for downstream tasks. The advantage of this approach is maximum control, tailored for specific needs, but it is extremely resource-intensive, and it requires longer training from days to weeks.
A good rule of thumb is to start with the simplest approach possible, such as prompt engineering with a third-party LLM API, to establish a baseline. Once this baseline is in place, you can incrementally integrate more sophisticated strategies like RAG or fine-tuning to refine and optimize performance. The use of standard MLOps tools such as MLflow is equally crucial in LLM applications to track performance over different approach iterations. Quick, on-the-fly model guidance.
Model Evaluation Challenges
Evaluating LLMs is a challenging and evolving domain, primarily because LLMs often demonstrate uneven capabilities across different tasks. LLMs can be sensitive to prompt variations, demonstrating high proficiency in one task but faltering with slight deviations in prompts. Since most LLMs output natural language, it is very difficult to evaluate the outputs via traditional Natural Language Processing metrics. For domain-specific fine-tuned LLMs, popular generic benchmarks may not capture their nuanced capabilities. Such models are tailored for specialized tasks, making traditional metrics less relevant. It is often the case that LLM performance is being evaluated in domains where text is scarce or there is a reliance on subject matter expert knowledge. In such scenarios, evaluating LLM output can be costly and time-consuming.
Some prominent benchmarks used to evaluate LLM performance include:
- BIG-bench (Beyond the Imitation Game Benchmark): A dynamic benchmarking framework, currently hosting over 200 tasks, with a focus on adapting to future LLM capabilities
- Elluether AI LM Evaluation Harness: A holistic framework that assesses models on over 200 tasks, merging evaluations like BIG-bench and MMLU, promoting reproducibility and comparability
- Mosaic Model Gauntlet: An aggregated evaluation approach, categorizing model competency into six broad domains (shown below) rather than distilling it into a single monolithic metric
LLMOps Reference Architecture
A well-defined LLMOps architecture is essential for managing machine learning workflows and operationalizing models in production environments.
Here is an illustration of the production architecture with key adjustments to the reference architecture from traditional MLOps, and below is the reference production architecture for LLM-based applications:
- RAG workflow using a third-party API:
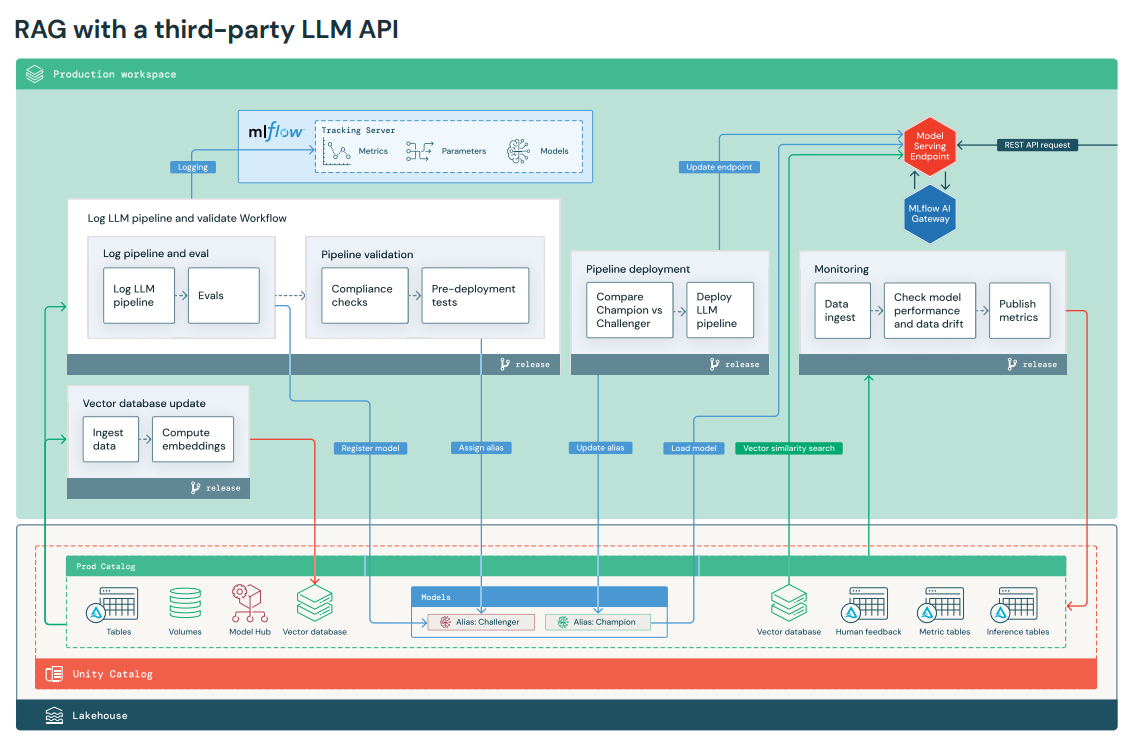
Figure 6: RAG workflow using a third-party API (Image Source: Databricks)
- RAG workflow using a self-hosted fine-tuned model and an existing base model from the model hub that is then fine-tuned in production:
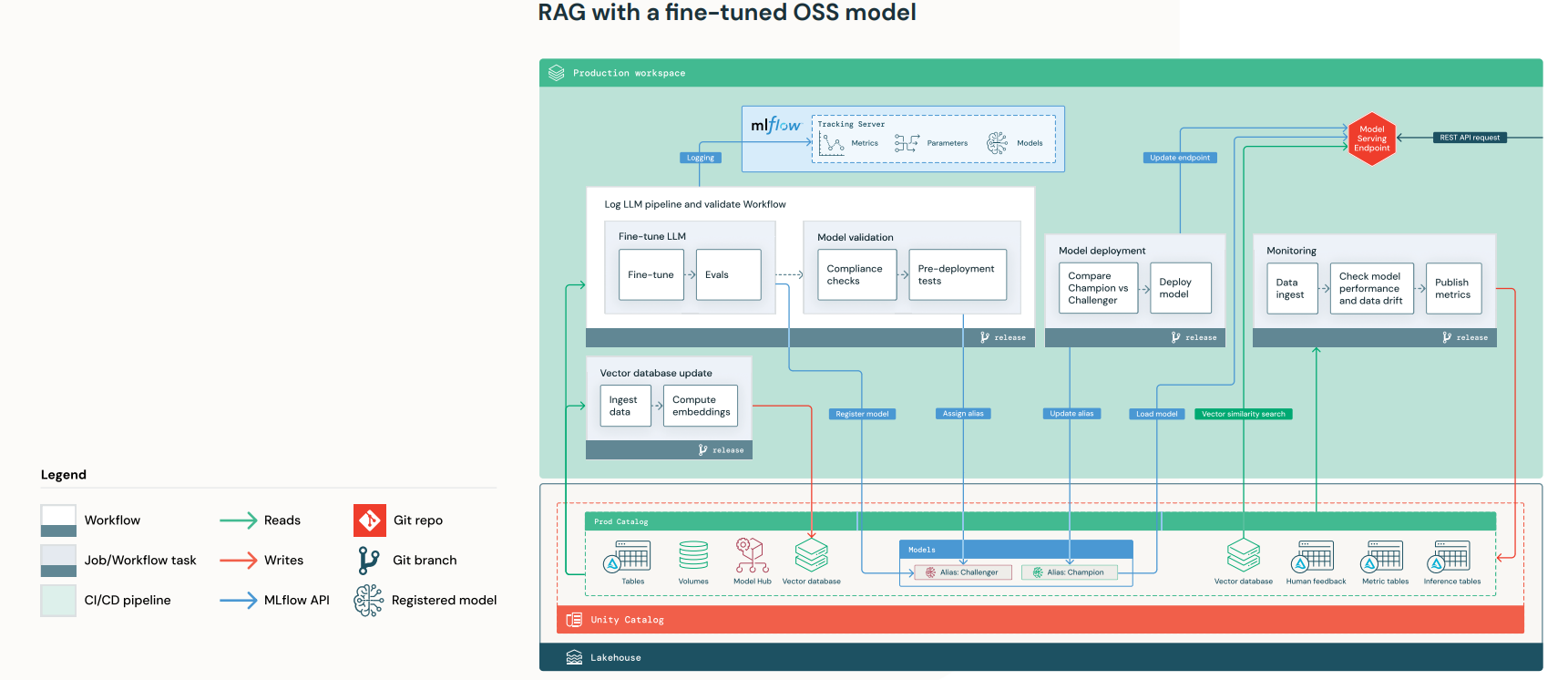
Figure 7: RAG workflow using a self-hosted fine-tuned model (Image Source: Databricks)
LLMOps: Pros and Cons
Pros
- Minimal changes to base model: Most of the LLM applications often make use of existing, pre-trained models, and an internal or external model hub becomes a valuable part of the infrastructure. It is easy and requires simple changes to adopt it.
- Easy to model and deploy: The complexities of model construction, testing, and fine-tuning are overcome in LLMOps, enabling quicker development cycles. Also, deploying, monitoring, and enhancing models is made hassle-free. You can leverage expansive language models directly as the engine for your AI applications.
- Advanced language models: By utilizing advanced models like the pre-trained Hugging Face model (e.g., meta-llama/Llama-2-7b, google/gemma-7b) or one from OpenAI (e.g., GPT-3.5-turbo or GPT-4). LLMOps enables you to harness the power of billions or trillions of parameters, delivering natural and coherent text generation across various language tasks.
Cons
- Human feedback: Human feedback in monitoring and evaluation loops may be used in traditional ML but becomes essential in most LLM applications. Human feedback should be managed like other data, ideally incorporated into monitoring based on near real-time streaming.
- Limitations and quotas: LLMOps comes with constraints such as token limits, request quotas, response times, and output length, affecting its operational scope.
- Risky and complex integration: The LLM pipeline will make external API calls, from the model serving endpoint to internal or third-party LLM APIs. This adds complexity, potential latency, and another layer of credential management. Also, integrating large language models as APIs requires technical skills and understanding. Scripting and tool utilization have become integral components, adding to the complexity.
Conclusion
Automation of workload is variable and intensive and will help in filling the gap between the data science team and the IT operations team. Planning for good governance early in the AI process will minimize AI efforts for data movement to accelerate model development. The emergence of LLMOps highlights the rapid advancement and specialized needs of the field of Generative AI and LLMOps is still rooted in the foundational principles of MLOps.
In this article, we have looked at key components, practices, tools, and reference architecture with examples such as:
- Major similarities and differences between MLOPs and LLOPs
- Major deployment patterns to migrate data, code, and model
- Schematics of Ops such as development, staging, and production environments
- Major approaches to building LLM applications such as prompt engineering, RAGs, fine-tuned, and pre-trained models, and key comparisons
- LLM serving and observability, including tools and practices for monitoring LLM performance
-
The end-to-end architecture integrates all components across dev, staging, and production environments. CI/CD pipelines automate deployment upon branch merges.
Opinions expressed by DZone contributors are their own.
Comments