Liquid Clustering With Databricks Delta Lake
Databricks introduced Liquid Clustering at the Data + AI Summit, a new approach that enhances read and write performance by optimizing data layout dynamically.
Join the DZone community and get the full member experience.
Join For FreeDatabricks unveiled Liquid Clustering at this year's Data + AI Summit, a new approach aimed at improving both read and write performance through a dynamic data layout.
Recap: Partitioning and Z-Ordering
Both partitioning and z-ordering rely on data layout to perform data processing optimizations. They are complementary since they operate on different levels and apply to different types of columns.
- Partition on most queried, low-cardinality columns.
- Do not partition tables that contains less than 1TB of data.
- Rule of thumb: All partitions to contain at least 1GB of data.
- Z-order on most queried, high-cardinality columns.
- Use Z-order indexes alongside partitions to speed up queries on large datasets.
- Z-order clustering only occurs within a partition and cannot be applied to fields used for partitioning.

Now, let's assume we've come up with the right partition strategy for our data and Z-ordered on the correct columns.
First off, insert, delete, and update operations break Z-ordering. Although Low shuffle merge tries to preserve the data layout on existing data that is not modified, that updated data layout may still end up not being optimal, so it may be necessary to run the OPTIMIZE ZORDER BY commands again each time. Although Z-ordering aims to be an incremental operation, the actual time it takes is not guaranteed to reduce over multiple runs.
But more importantly, query patterns change over time. The same partition that worked well in the past might now be suboptimal. Partition evolution is a real challenge, and to my knowledge, only the Iceberg table format has support for it so far.
Liquid Clustering
Liquid Clustering ( abbreviated as LC in this article) automatically adjusts the data layout based on clustering keys. In contrast to a fixed data layout, as in Hive-style partitioning, the flexible ("liquid") layout dynamically adjusts to changing query patterns, addressing the problem of suboptimal partitioning, column cardinality, etc. Clustering columns can be changed without rewriting the data.
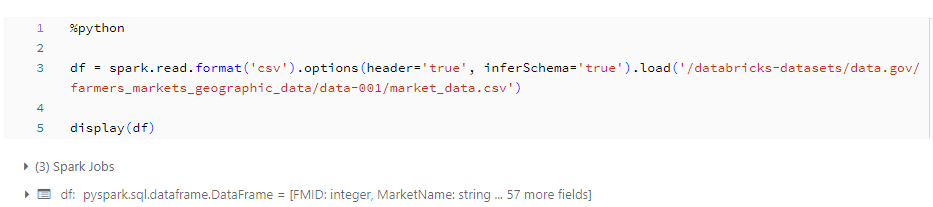
For this (very) short example, we're using the farmers markets geographic dataset just to try out the commands.
{kind=link}
{kind=link}
Next, let's switch to SQL, run a CTAS on the markets table, and cluster by the State and County columns without bothering with neither partitioning nor Z-ordering.

{kind=link}
{kind=link}

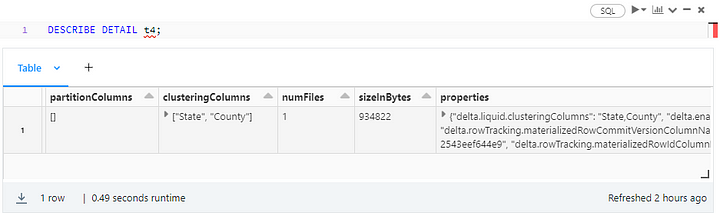
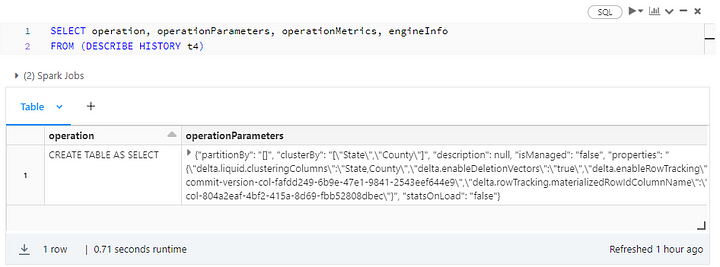
We enabled LC by specifying the clustering columns with CLUSTER BY and triggered the process with the OPTIMIZE command. We can verify the clustered columns this way:
{kind=link}
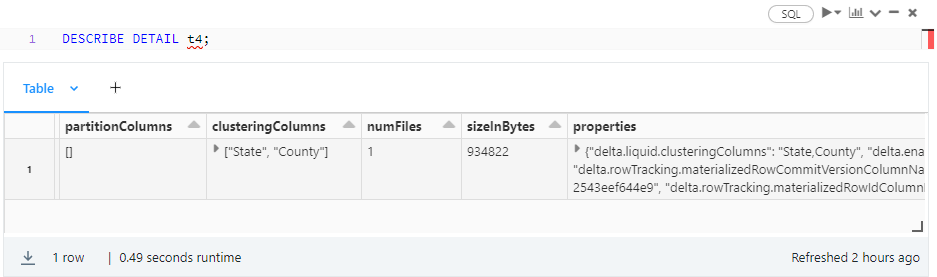
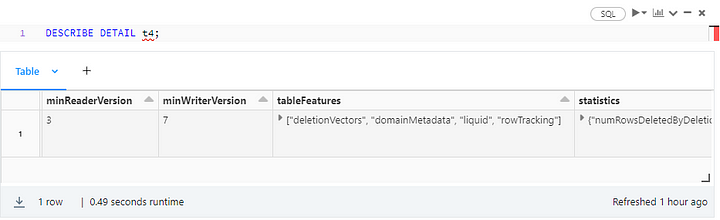
Sliding the results table to check the next columns:
{kind=link}
A few important details emerge from the screenshot above:
- Through table protocol versioning, Delta Lake tracks minimum reader and writer versions separately for Delta Lake evolution. As a new milestone in that evolution, LC automatically bumps up the reader and writer versions to 3 and 7, respectively. Be aware that protocol version upgrades are irreversible and may break existing Delta Lake table readers, writers, or both.
- By the same token, Delta Lake clients need to support deletion vectors. Those are optimization features (Databricks Runtime 12.1 and above) allowing you to mark deleted rows as such, but without rewriting the whole Parquet file.
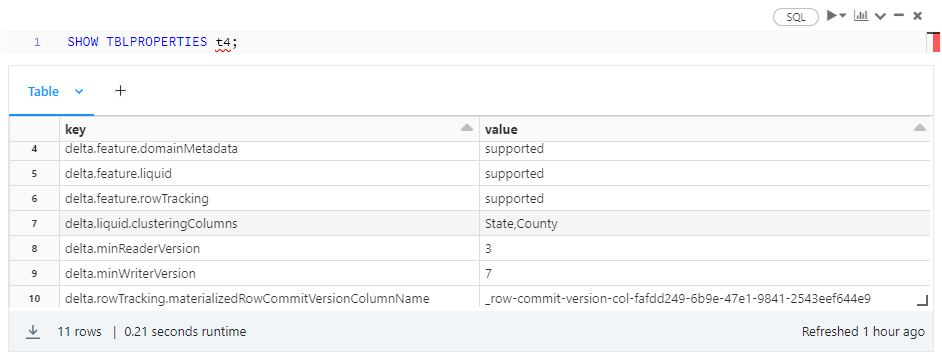
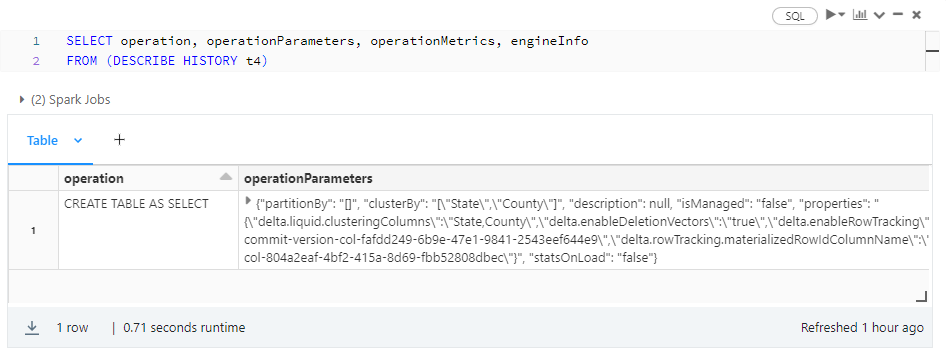
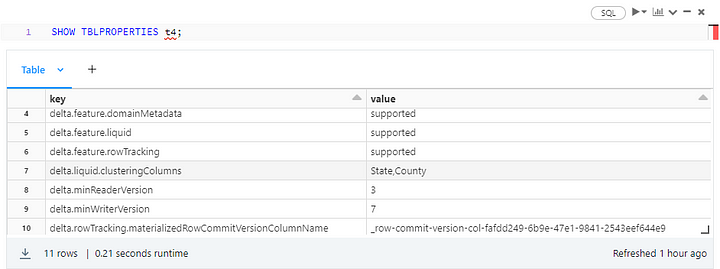
Just for the fun of it, here are a couple of other ways to display the same information:
{kind=link}
{kind=link}
Finally, we can read the table, filtering by the clustering keys, e.g.:
{kind=link}
Up to 4 columns with statistics collected for can be specified as clustering keys. Those keys can be changed at any time using the ALTER TABLE command. Remember that, by default, the first 32 columns in Delta tables have statistics collected on them. This number can be controlled through the table property delta.dataSkippingNumIndexedCols. All columns with a position index less than that property value will have statistics collected.
As for writing to a clustered table, there are some important limitations at this time. Only the following operations automatically cluster data on write, provided they do not exceed 512GB of data in size:
INSERT INTOCREATE TABLE AS SELECT(CTAS) statementsCOPY INTOfrom Parquet- Write appends, i.e.,
spark.write.format("delta").mode("append")
Because of the above limitations, LC should be scheduled on a regular basis using the OPTIMIZE command to ensure that data is effectively clustered. As the process is incremental, those jobs should not take long.
Note that LC is in Public Preview at this time and requires Databricks Runtime 13.2 and above. It aims at effectively replacing both Hive-style partitioning and Z-ordering, which relied on (static) physical data layout to perform their optimizations. Be sure to give it a try.
Published at DZone with permission of Tony Siciliani, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments