LazyPredict: A Utilitarian Python Library to Shortlist the Best ML Models for a Given Use Case
Discussing LazyPredict to create simple ML models without writing a lot of code, and determine which models perform best without modifying their parameters!
Join the DZone community and get the full member experience.
Join For FreeTable of Contents
- Introduction
- Installation of the LazyPredict Module
- Implementing LazyPredict in a Classification Model
- Implementing LazyPredict in a Regression Model
- Conclusion
Introduction
The development of machine learning models is being revolutionized by the state-of-the-art Python package known as LazyPredict. By using LazyPredict, we can quickly create a variety of fundamental models with little to no code, freeing up our time to choose the model that would work best with our data.
Model selection may be made easier using the library without requiring considerable parameter adjustment, which is one of its main benefits. LazyPredict offers a quick and effective way to find and fit the best models to our data.
Let’s explore and learn more about the usage of this library in this article.
Installation of the LazyPredict Module
Installation of the LazyPredict library is a pretty easy task. We need to use only one line of code as we usually do for installing any other Python library:
!pip install lazypredictImplementing LazyPredict in a Classification Model
We’ll utilize the breast cancer dataset from the Sklearn package in this example.
Now, let’s load the data:
from sklearn.datasets import load_breast_cancer
from lazypredict.Supervised import LazyClassifier
data = load_breast_cancer()
X = data.data
y= data.targetTo choose the best classifier model, let’s now deploy the “LazyClassifier” algorithm. These characteristics and input parameters apply to the class:
LazyClassifier(
verbose=0,
ignore_warnings=True,
custom_metric=None,
predictions=False,
random_state=42,
classifiers='all',
)Let’s now apply it to our data and fit it:
from lazypredict.Supervised import LazyClassifier
from sklearn.model_selection import train_test_split
# split the data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state =0)
# build the lazyclassifier
clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None)
# fit it
models, predictions = clf.fit(X_train, X_test, y_train, y_test)
# print the best models
print(models)The code above outputs:
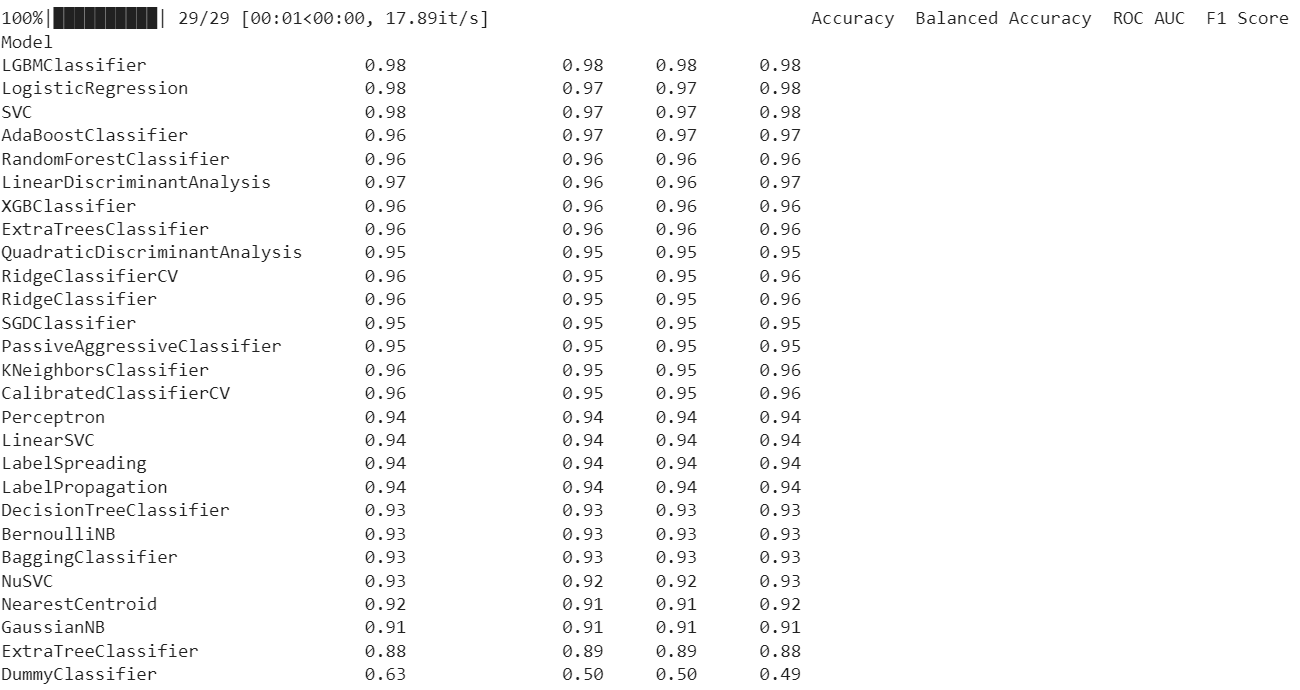
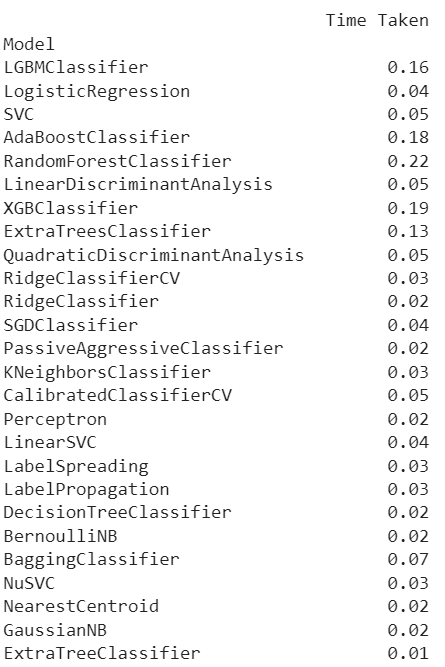
Then, we may conduct the following to examine these models’ individual details:
model_dictionary = clf.provide_models(X_train,X_test,y_train,y_test)Next, use the name of the model that interests us (let’s choose the best model) to determine precisely which steps were used:
model_dictionary['LGBMClassifier']
Here, we can see that a SimpleImputer was used on the entire set of data, followed by a StandardScaler on the numerical features. There are no categorical or ordinal features in this dataset, but if there were, OneHotEncoder and OrdinalEncoder would have been used, respectively. The LGBMClassifier model receives the data after transformation and imputation.
LazyClassifier’s internal machine-learning models are evaluated and fitted using the sci-kit-learn toolkit. The LazyClassifier function automatically builds and fits a variety of models, including decision trees, random forests, support vector machines, and others, on our data when it is called. A set of performance criteria, like accuracy, recall, or F1 score, that you provide are then used to evaluate the models. The training set is used for fitting, while the test set is used for evaluation.
Following the models’ evaluation and fitting, LazyClassifier offers a summary of the findings (the table above), along with a list of the top models and performance metrics for each model. With no need for manual tweaking or model selection, you can quickly and simply evaluate the performance of many models and choose the best one for our data.
Implementing LazyPredict in a Regression Model
Using the “LazyRegressor” function, we can, once again, accomplish the same for regression models.
Let’s import a dataset that will be suitable for a regression task (Here, we can use the Boston dataset).
Let’s now fit our data to the LazyRegressor using it:
from lazypredict.Supervised import LazyRegressor
from sklearn import datasets
from sklearn.utils import shuffle
import numpy as np
# load the data
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=0)
X = X.astype(np.float32)
# split the data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state =0)
# fit the lazy object
reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)
# print the results in a table
print(models)The code above outputs:
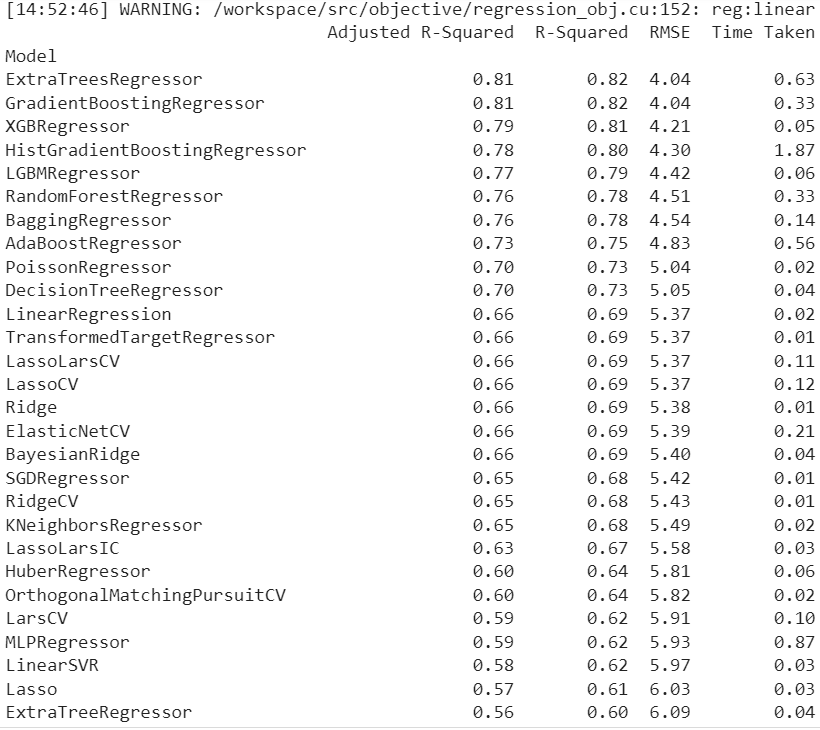
The following is a detailed examination of the best regression model:
model_dictionary = reg.provide_models(X_train,X_test,y_train,y_test)
model_dictionary['ExtraTreesRegressor']
Here, we can see that a SimpleImputer was used on the entire set of data, followed by a StandardScaler on the numerical features. There are no categorical or ordinal features in this dataset, but if there were, OneHotEncoder and OrdinalEncoder would have been used, respectively. The ExtraTreesRegressor model receives the data after transformation and imputation.
Conclusion
The LazyPredict library is a useful resource for anybody involved in the machine learning industry. LazyPredict saves time and effort by automating the process of creating and assessing models, which greatly improves the effectiveness of the model selection process. LazyPredict offers a quick and simple method for comparing the effectiveness of several models and determining which model family is best for our data and problem due to its capacity to fit and assess numerous models simultaneously.
The following link has all the programming examples uploaded to the GitHub repository so that you can play around with the codes according to your requirements.
I hope that now you got an intuitive understanding of the LazyPredict library, and these concepts will help you in building some really valuable projects.
Opinions expressed by DZone contributors are their own.
Comments