KEDA: Kubernetes Event Driven Auto-Scaling in Azure Kubernetes Services (AKS)
AutoScaling is a cloud computing feature that allows you to automatically adjust the capacity of your resources based on actual workload.
Join the DZone community and get the full member experience.
Join For FreeBefore we start with Kubernetes Event Driven AutoScaling (KEDA) and its details, we first need to understand what AutoScaling is in a cloud-native environment and what kinds of auto-scaling are available in a cloud environment.
AutoScaling, also known as automatic scaling, is a cloud computing feature that allows you to automatically adjust the capacity of your resources based on actual workload. This capability ensures that you have the right amount of computing resources available to handle varying levels of demand without manual intervention. AutoScaling is commonly used in cloud environments, like Amazon Web Services (AWS) and Microsoft Azure, to maintain high availability, optimize costs, and improve system performance.
There are several types of AutoScaling, each designed for specific use cases:
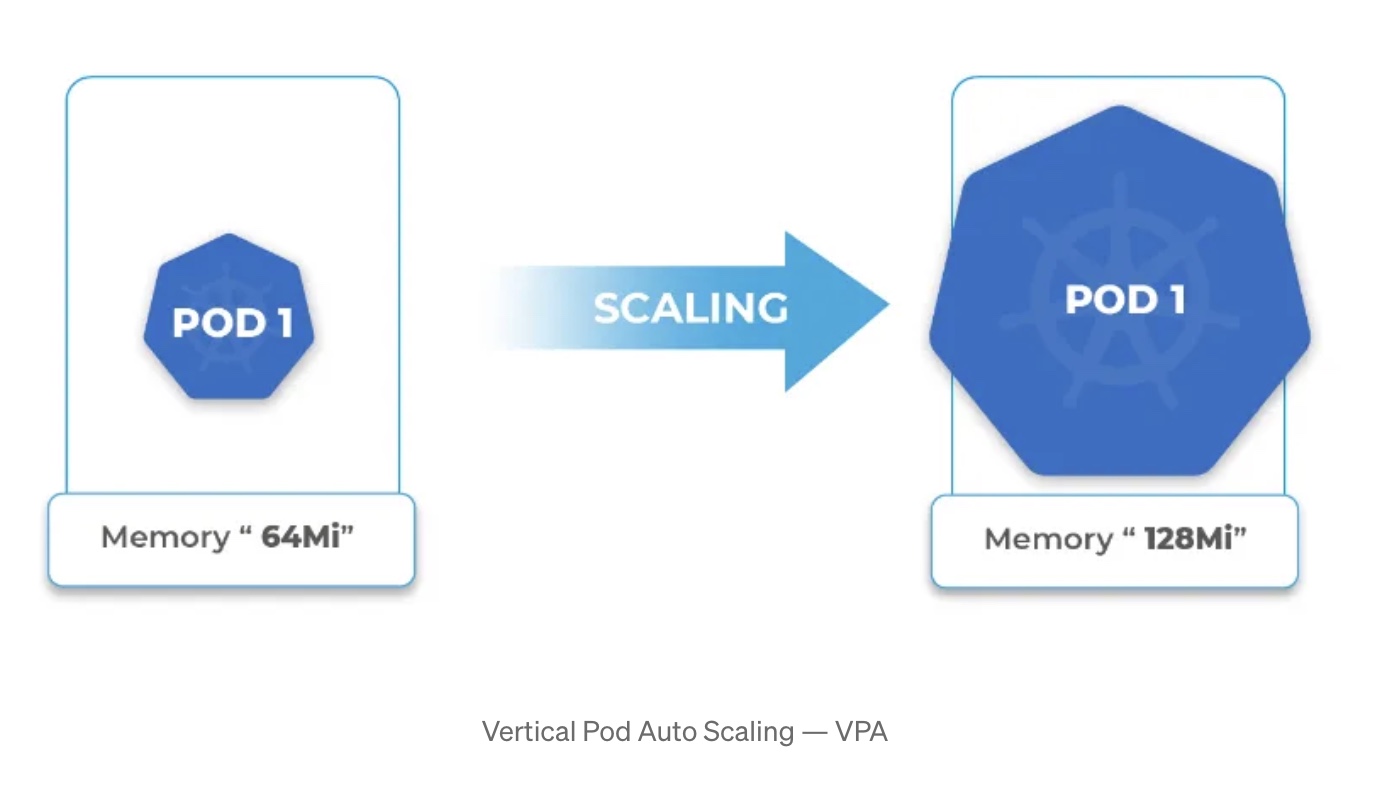
Vertical Pod AutoScaling — VPA (Up and Down)
- Up: This type of AutoScaling involves increasing the capacity of individual resources, such as adding more CPU, memory, or storage to a single instance. It’s suitable for applications that require vertical growth to handle increased loads.
- Down: Conversely, vertical downscaling reduces the capacity of individual resources. It’s typically used when resource requirements decrease, allowing you to save costs by downsizing instances.
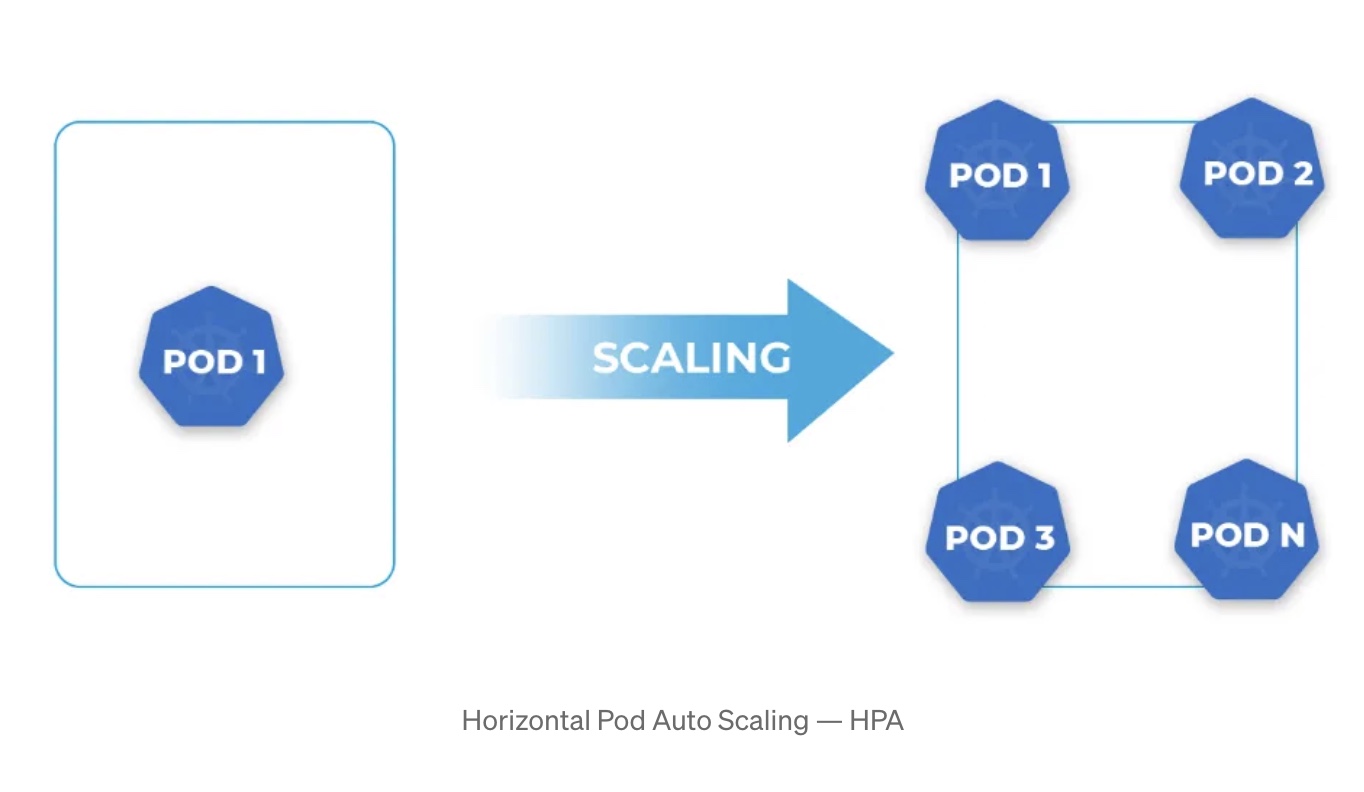
Horizontal Pod AutoScaling: HPA (Out and In)
- Out: Horizontal AutoScaling, also known as scaling out, involves adding more identical instances to your application. This approach is suitable for applications that can distribute workloads across multiple instances to meet increasing demand.
- In: Scaling in, or reducing the number of instances, is used to downsize your application’s capacity when the workload decreases. It helps optimize costs by removing unnecessary resources.
Dynamic AutoScaling
Dynamic AutoScaling combines both vertical and horizontal scaling. It adjusts the number of instances and the size of each instance based on workload changes. For example, it may add more instances increase the resources allocated to each instance during traffic spikes, and reduce them during quiet periods.
Scheduled AutoScaling
Scheduled AutoScaling allows you to define specific time-based schedules for adjusting the capacity of your resources. This is useful for applications with predictable changes in traffic patterns, such as daily or weekly surges.
Predictive AutoScaling
Predictive AutoScaling uses machine learning and historical data to forecast future resource requirements. It automates scaling decisions by predicting when additional capacity is needed, reducing the risk of under or over-provisioning.
Load-Based AutoScaling
Load-based autoscaling monitors specific metrics, such as CPU utilization or network traffic, and automatically adjusts resources based on the thresholds you define. When these metrics breach the thresholds, the system scales resources up or down accordingly.
Container Orchestration AutoScaling
Container orchestration platforms like Kubernetes include built-in AutoScaling features. They automatically adjust the number of container instances based on factors such as CPU and memory utilization or custom-defined metrics.
Event-Driven AutoScaling
Event-driven AutoScaling allows you to trigger scaling actions based on specific events or conditions. For example, you can scale your application in response to increased user traffic, the arrival of new data, or the launch of a specific job.
The choice of AutoScaling type depends on your specific use case, application architecture, and cloud platform. In many cases, a combination of these AutoScaling types may be used to ensure that your cloud resources are optimized for performance, cost, and high availability.
In this article, we are going to discuss Event Driven AutoScaling in the Kubernetes environment.
KEDA, which stands for Kubernetes Event-Driven Autoscaling, is an open-source project that provides event-driven auto-scaling for container workloads running on Kubernetes. It enables Kubernetes applications to scale based on external events, such as messages arriving in a queue, the number of HTTP requests, or custom event triggers. KEDA helps make your applications more efficient, cost-effective, and responsive to changes in workloads.
Key features and components of KEDA include:
- Scaler support: KEDA supports a variety of scalers, which are responsible for interpreting external events and providing scaling metrics. These scalers include Azure Queue Storage, RabbitMQ, Kafka, Prometheus, and custom scalers for your specific needs.
- Deployment annotations: You can configure KEDA by adding annotations to your Kubernetes deployments, specifying how they should scale based on the events monitored by the scalers.
- Horizontal pod autoscaler integration: KEDA seamlessly integrates with Kubernetes’ Horizontal Pod Autoscaler (HPA), allowing you to combine traditional resource-based scaling with event-driven scaling.
- Event source adapters: Event source adapters are responsible for connecting KEDA to external event sources. These adapters are available for a range of cloud and messaging platforms.
- Metrics server: KEDA relies on a metrics server to collect and expose the metrics needed for auto-scaling.
Using KEDA, you can build applications that automatically adjust their resources based on actual demand.
For example, if you have a message queue, KEDA can automatically scale your application based on the number of messages waiting in the queue. This ensures that you always have the right amount of resources available and can optimize costs by not over-provisioning.
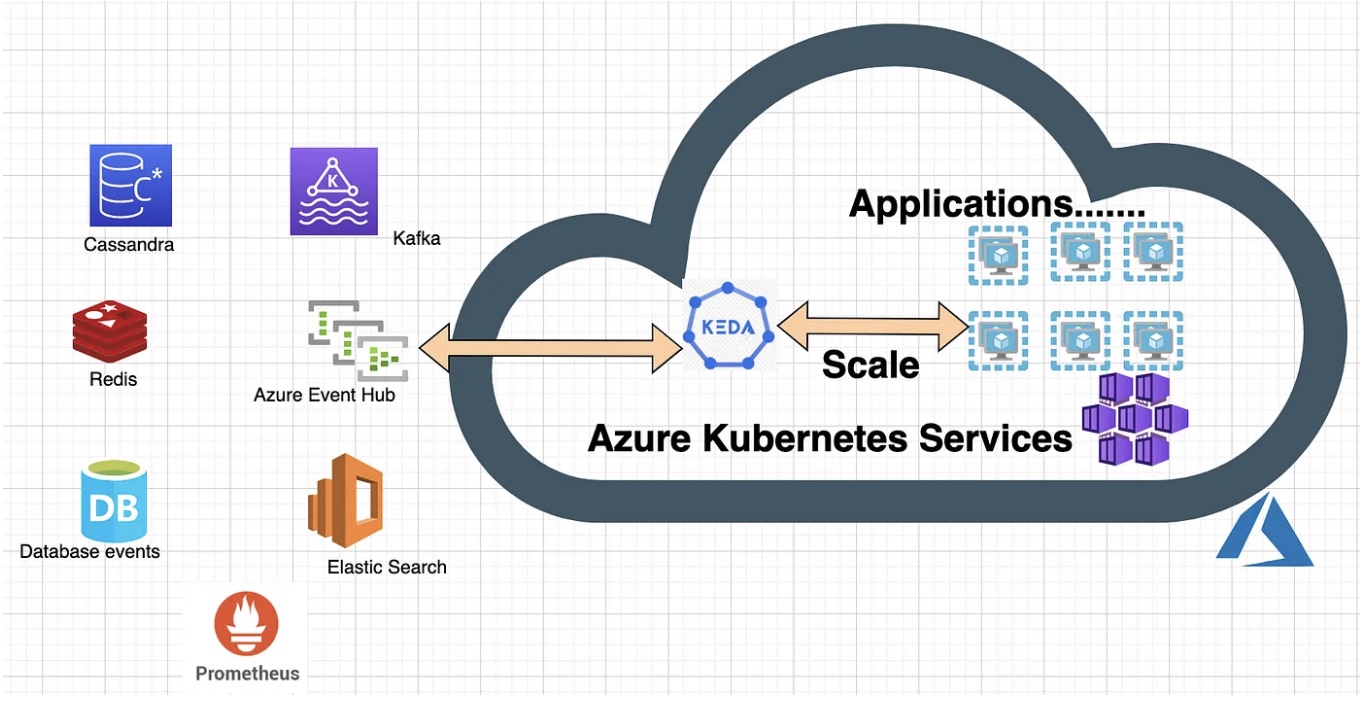
To demonstrate the value and ease of use of KEDA in a production environment, here are two examples:
- Example 1: Keda + Redis: A Video game company wants to scale its gaming application according to the number of messages in a queue.
- Example 2: Keda + Prometheus: A finance institution wants to scale its application according to the rate of payments request received by it.
To get started with KEDA, you typically need to install it in your Kubernetes cluster, define scalers for your event sources, configure deployments with appropriate annotations, and then KEDA will manage the scaling based on the configured events. It simplifies the process of building scalable and efficient applications in Kubernetes.
Here’s how to set up KEDA in AKS:
1. Set up AKS: If you haven’t already, create an AKS cluster using the Azure CLI, Azure Portal, or Infrastructure as Code (IaC) tools like Terraform.
2. Install Helm: To deploy KEDA, you’ll need Helm, a package manager for Kubernetes. If Helm is not already available in your environment, install it.
3. Install KEDA: Use Helm to install KEDA in your AKS cluster. Add the KEDA repository to Helm and install it with the following commands:

4. Set up event sources: Configure the event sources you want to monitor. KEDA supports a variety of event sources, such as Azure Queue Storage, RabbitMQ, Kafka, and custom events.
5. Define scalers: Scalers interpret external events and provide metrics for scaling. Define scalers specific to your event sources by following KEDA’s documentation.
6. Create a deployment: Define the Kubernetes deployment that you want to scale based on events. You’ll need to add annotations and resource definitions to the deployment to specify how it should scale.
7. Apply your deployment: Apply the deployment to your AKS cluster. KEDA will automatically manage the scaling of your deployment based on the configured event sources.
8. Monitor and test: Monitor your AKS cluster and your event source. Test the scaling behavior by sending events to your chosen event source and observing how your application scales in response.
KEDA simplifies the process of creating event-driven auto-scaling applications in AKS, allowing you to focus on defining event sources and scalers specific to your use case.
KEDA takes care of the scaling process, making it ideal for applications that need to efficiently and cost-effectively handle variable workloads.
Published at DZone with permission of Gaurav Shekhar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments