Apache Kafka + Flink + Snowflake: Cost-Efficient Analytics and Data Governance
Explore shift-left architecture with Snowflake, Apache Kafka, Flink, and Iceberg for cost-efficient analytics and data governance in the cloud.
Join the DZone community and get the full member experience.
Join For FreeSnowflake is a leading cloud data warehouse and transitions into a data cloud that enables various use cases. The major drawback of this evolution is the significantly growing cost of the data processing. This blog post explores how data streaming with Apache Kafka and Apache Flink enables a "shift left architecture" where business teams can reduce cost, provide better data quality, and process data more efficiently. The real-time capabilities and unification of transactional and analytical workloads using Apache Iceberg's open table format enable new use cases and a best-of-breed approach without a vendor lock-in and the choice of various analytical query engines like Dremio, Starburst, Databricks, Amazon Athena, Google BigQuery, or Apache Flink.
Snowflake and Apache Kafka
Snowflake is a leading cloud-native data warehouse. Its usability and scalability made it a prevalent data platform in thousands of companies. This blog series explores different data integration and ingestion options, including traditional ETL/iPaaS and data streaming with Apache Kafka. The discussion covers why point-to-point Zero-ETL is only a short-term win, why Reverse ETL is an anti-pattern for real-time use cases, and when a Kappa Architecture and shifting data processing “to the left” into the streaming layer helps to build transactional and analytical real-time and batch use cases in a reliable and cost-efficient way.
This is part of a blog series:
- Snowflake Integration Patterns: Zero ETL and Reverse ETL vs. Apache Kafka
- Snowflake Data Integration Options for Apache Kafka (including Iceberg)
- THIS POST: Apache Kafka + Flink + Snowflake: Cost-Efficient Analytics and Data Governance
Stream Processing With Kafka and Flink BEFORE the Data Hits Snowflake
The first two blog posts explored the different design patterns and ingestion options for Snowflake via Kafka or other ETL tools. But let's make it very clear: ingesting all raw data into a single data lake at rest is an anti-pattern in almost all cases. It is not cost-efficient and blocks real-time use cases. Why?
Real-time data beats slow data. That’s true for almost every use case. Enterprise architects build infrastructures with the Lambda architecture that often includes a data lake for all the analytics. The Kappa architecture is a software architecture that is event-based and able to handle all data at all scales in real time for transactional AND analytical workloads.
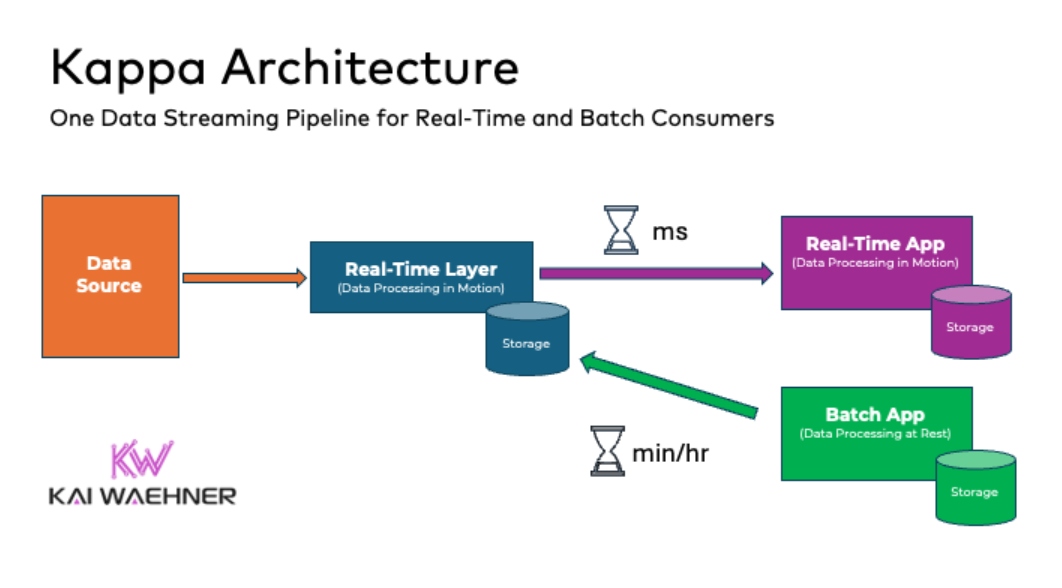
Reverse ETL Is NOT a Good Strategy for Real-Time Apps
The central premise behind the Kappa architecture is that you can perform both real-time and batch processing with a single technology stack. The heart of the infrastructure is streaming architecture. First, the data streaming platform log stores incoming data. From there, a stream processing engine processes the data continuously in real-time or ingests the data into any other analytics database or business application via any communication paradigm and speed, including real-time, near real-time, batch, and request-response.
The business domains have the freedom of choice. In the above diagram, a consumer could be:
- Batch app: Snowflake (using Snowpipe for ingestion)
- Batch app: Elasticsearch for search queries
- Near real-time app: Snowflake (using Snowpipe Streaming for ingestion)
- Real-time app: Stream processing with Kafka Streams or Apache Flink
- Near real-time app: HTTP/REST API for request-response communication or 3rd party integration
I explored in a thorough analysis why Reverse ETL with a Data Warehouse or Data Lake like Snowflake is an ANTI-PATTERN for real-time use cases.

Reverse ETL is unavoidable in some scenarios, especially in larger organizations. Tools live FiveTran or Hightouch do a good job if you need Reverse ETL. But never design your enterprise architecture to store data in a data lake just to reverse it afterward.
Cheap Object Storage -> Cloud Data Warehouse = Data Swamp
The cost of storage has gotten extremely cheap with object storage in the public cloud.
With the explosion of more data and more data types/formats, object storage has risen as de facto cheap, ubiquitous storage serving the traditional “data lake."
However, even with that in place the data lake was still the “data swamp," with lots of different file sizes/types, etc., still, the cloud data warehouse was probably easier, and probably why it made more sense to still point most raw data for analysis in the data warehouse.
Snowflake is a very good analytics platform. It provides strict SLAs and concurrent queries that need that speed. However, many of the workloads done in Snowflake don’t have that requirement. Instead, some use cases require ad hoc queries and are exploratory in nature with no speed SLAs. Data warehousing should often be a destination of processed data, not an entry point for all things raw data. And on the other side, some applications require low latency for query results. Purpose-built databases do analytics much faster than Snowflake, even at scale and for transactional workloads.
The Right Engine for the Job
The combination of an object store with a table format like Apache Iceberg enables openness for different teams. You add a query engine on top, and it’s like a composable data warehouse. Now your team can run Apache Spark on your tables. Maybe data science can run Ray on it for machine learning, and maybe some aggregations run with Apache Flink.
It was never easier to choose the best-of-breed approach in each business unit when you leverage data streaming in combination with SaaS analytics offerings.
Therefore, teams should choose the best price/performance for their unique needs/requirements. Apache Iceberg makes that shift between different lakehouses and data platforms a lot easier as it helps with the compaction of small file issues.
Still, the performance of running SQL Engine on the data lake was slow/not performant and did not support key characteristics that are expected, like ACID transactions.
Dremio, Starburst Data, Spark SQL, Databricks Photon, Ray/Anyscale, Amazon Athena, Google BigQuery, Flink, etc. are all the query engine ecosystem systems that the data product in a governed Kafka Topic unlocks.
Why did I add a stream processor here with Flink? Flink as an option to query streams in real-time/as ad hoc exploratory questions on both real-time/historical upstream.
Not Every Query Needs to Be (Near) Real-Time!
Keep in mind that not every application requires the performance of Snowflake, a real-time analytics engine like Druid or Pinot, or modern data virtualization with Starburst. If you don’t need your random ad hoc query to see how many customers today are buying red shoes in the store to share results in 20 seconds/can wait for 3-5 minutes, and if the price of that query can be cheaper and done efficiently, shifting left gives you the option to decide where lane to put your queries:
- The stream processor as part of the data streaming platform for continuous or interactive queries (e.g., Apache Flink)
- The batch analytics platform for long-running big data calculations (e.g., Spark or even Flink's batch API)
- The analytics platform for fast, complex queries (e.g., Snowflake)
- The low latency user-facing analytics (e.g., Druid or Pinot)
- Other use cases with the best engine for the job (like search with Elasticsearch)
Shift Processing “To the Left” Into the Data Streaming Layer With Apache Flink
If storing all data in a single data lake/data warehouse/lakehouse AND Reverse ETL are anti-patterns, how can we solve it? The answer is simpler than you might think: move the processing "to the left" in the enterprise architecture!
Most architectures ingest raw data into multiple data sinks, i.e., databases, warehouses, lakes, and other applications:
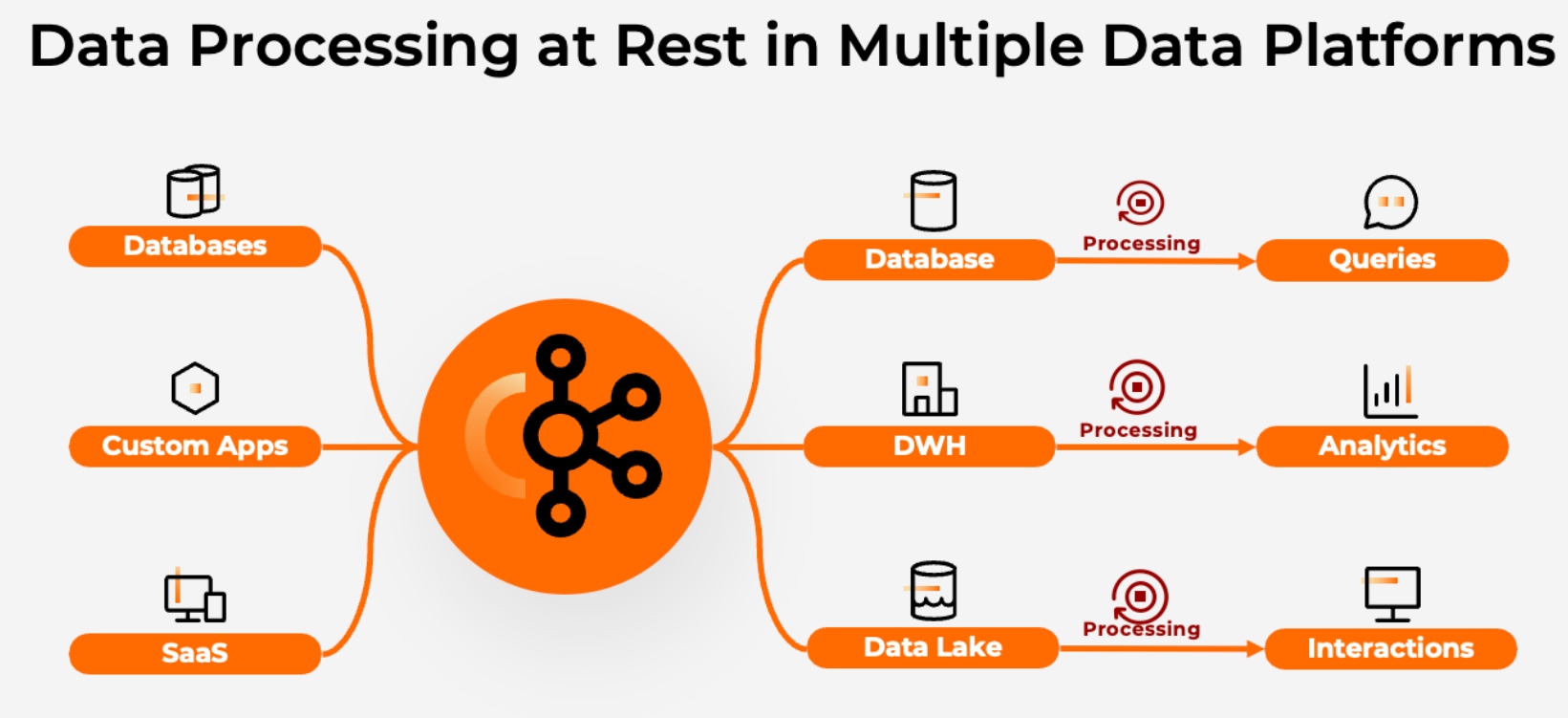
Source: Confluent
This has several drawbacks:
- Expensive and inefficient: The same data is cleaned, transformed, and enriched in multiple locations (often using legacy technologies).
- Varying degree of staleness: Every downstream system receives and processes the same data at different times/different time intervals and provides slightly different semantics. This leads to inconsistencies and degraded customer experience downstream.
- Complex and error-prone: The same business logic needs to be maintained at multiple places. Multiple processing engines need to be maintained and operated.
Hence, it is much more consistent and cost-efficient to process data once in real-time when it is created. A data streaming platform with Apache Kafka and Flink is perfect for this:
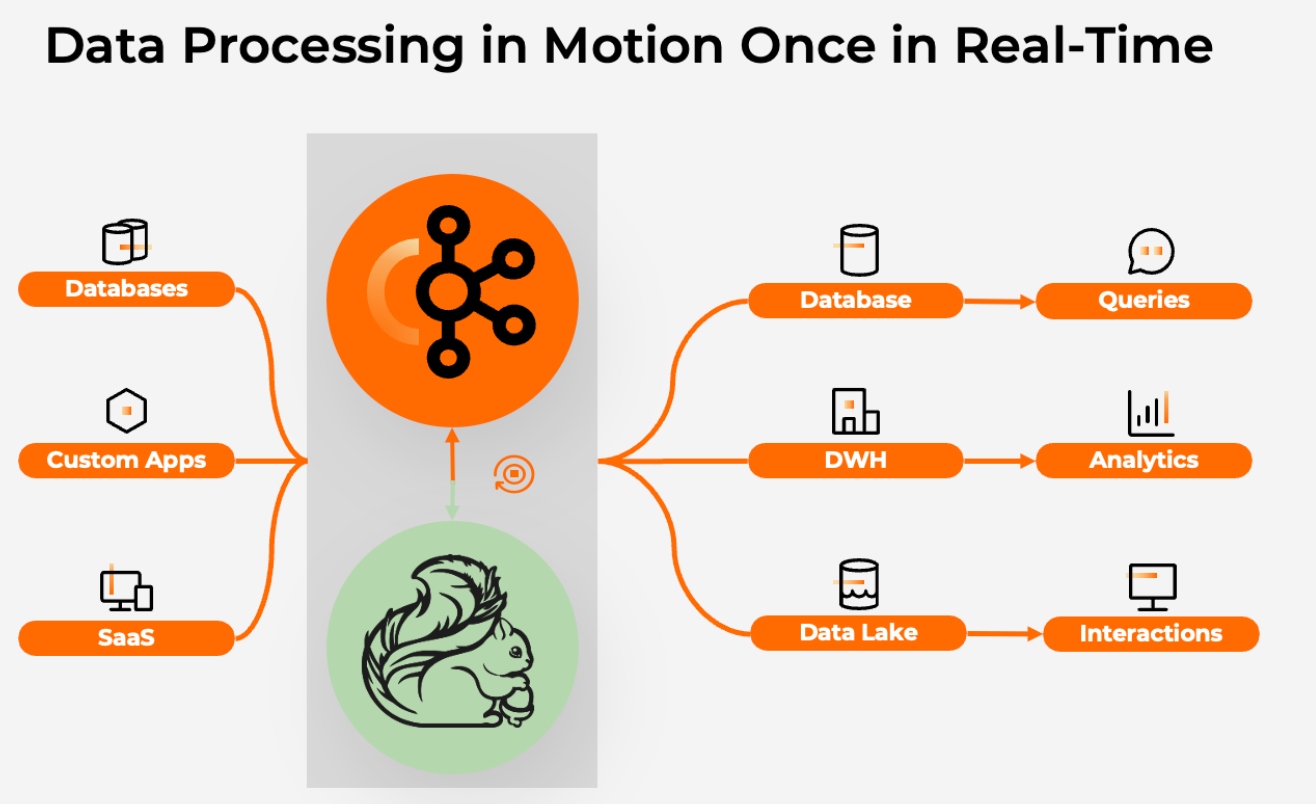
Source: Confluent
With the shift-left approach providing a data product with good quality in the streaming layer, each business team can look at the price/performance of the most popular/common/frequent/expensive queries and determine if they truly should live in the warehouse or choose another solution.
Processing the data with a data streaming platform "on the left side of the architecture" has various advantages:
- Cost efficient: Data is only processed once in a single place and it is processed continuously, spreading the work over time.
- Fresh data everywhere: All applications are supplied with equally fresh data and represent the current state of your business.
- Reusable and consistent: Data is processed continuously and meets the latency requirements of the most demanding consumers, which further increases reusability.
Universal Data Products and Cost-Efficient Data Sharing in Real-Time AND Batch
This is just a primer for its own discussion. Kafka and Snowflake are complementary. However, the right integration and ingestion architecture can make a difference for your entire data architecture (not just the analytics with Snowflake). Hence, check out my in-depth article "Kappa Architecture is Mainstream Replacing Lambda" to understand why data streaming is much more than just ingestion into your cloud data warehouse.
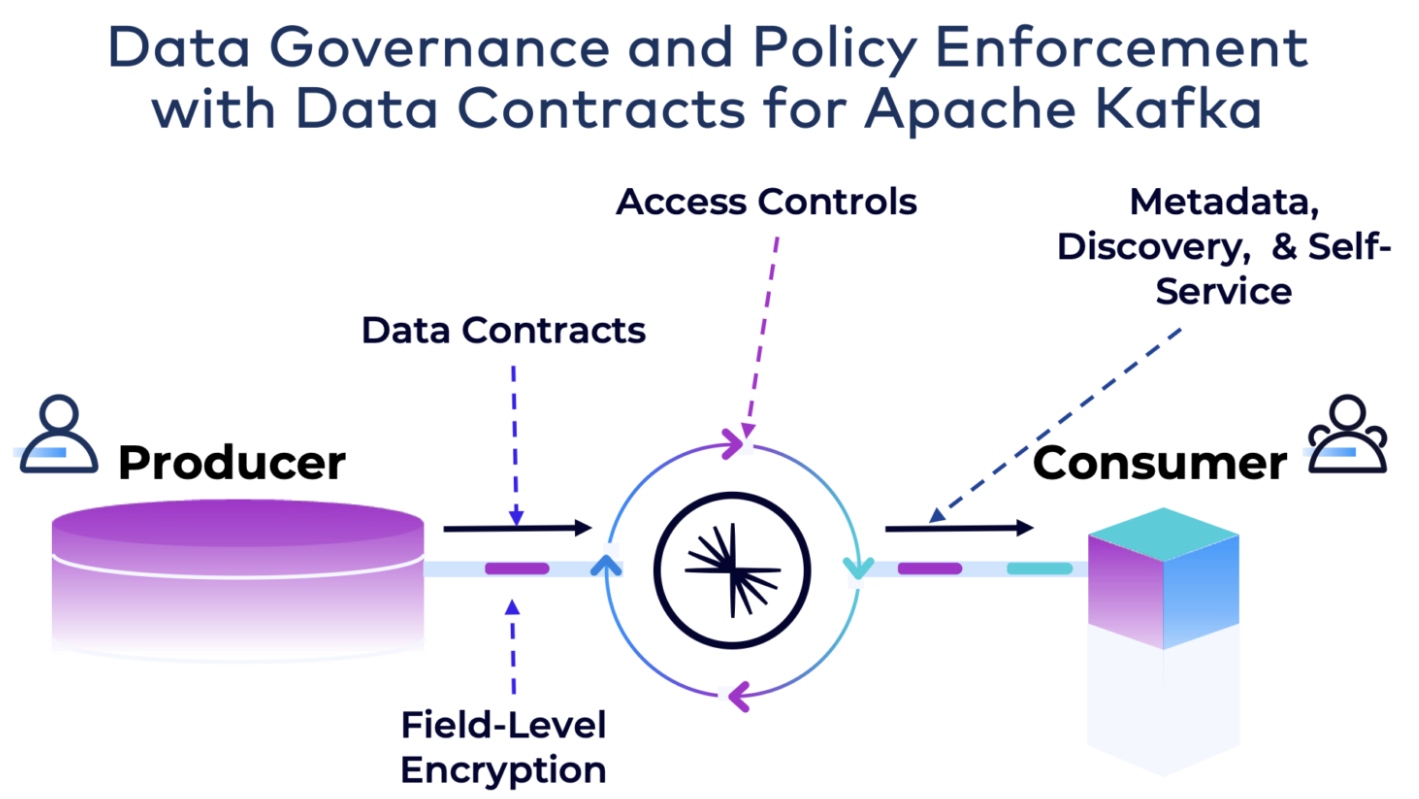
Source: Confluent
Building (real-time or batch) data products in modern microservice and data mesh enterprise architectures is the future. Data streaming enforces good data quality and cost-efficient data processing (instead of "DBT'ing" everything again and again in Snowflake).
This gives companies options to disaggregate the compute layer, and perhaps shift left queries that really don’t need a purpose-built analytics engine, i.e., where a stream processor like Apache Flink can do the job. That reduces data replication/copies. Different teams can query that data with the query engine of choice, based on the key requirements for the workload. But already built into good data quality is the data product (i.e., Kafka Topic) with data quality rules and policy enforcement (Topic Schema + rules engine).
The Need for Enterprise-Wide Data Governance Across Data Streaming With Apache Kafka and Lakehouses Like Snowflake
Enterprise-wide data governance plays a critical role in ensuring that organizations derive value from their data assets, maintain compliance with regulations, and mitigate risks associated with data management across diverse IT environments.
Most data platforms provide data governance capabilities like data catalog, data lineage, self-service data portals, etc. This includes data warehouses, data lakes, lakehouses, and data streaming platforms.
On the contrary, enterprise-wide data governance solutions look at the entire enterprise architecture. They collect information from all different warehouses, lakes, and streaming platforms. If you apply the shift left strategy for consistent and cost-efficient data processing across real-time and batch platforms, then the data streaming layer MUST integrate with the enterprise-wide data governance solution. But frankly, you SHOULD integrate all platforms into the enterprise-wide governance view anyway, no matter if you shift some workloads to the left or not.
Today, most companies built their own enterprise-wide governance suite (if they have one already at all). In the future, more and more companies adopt dedicated solutions like Collibra or Microsoft Purview. No matter what you choose, the data streaming governance layer needs to integrate with this enterprise-wide platform. Ideally, via direct integrations, but at least via APIs.
While the “shift left” approach disrupts the data teams that processed all data in analytics platforms like Snowflake or Databricks in the past, the enterprise-wide governance ensures that the data teams are comfortable across different data platforms. The benefit is the unification of real-time and batch data and operational and analytical workloads.
The Past, Present, and Future of Kafka and Snowflake Integration
Apache Kafka and Snowflake are complementary technologies with various integration options to build an end-to-end data pipeline with reporting and analytics in the cloud data warehouse or data cloud.
Real-time data beats slow data in almost all use cases. Some scenarios benefit from Snowpipe Streaming with Kafka Connect to build near-real-time use cases in Snowflake. Other use cases leverage stream processing for real-time analytics and operational use cases.
Independent Data Products with a Shift-Left Architecture and Data Governance
To ensure good data quality and cost-efficient data pipelines with data governance and policy enforcement in an enterprise architecture, a "shift left architecture" with data streaming is the best choice to build data products.
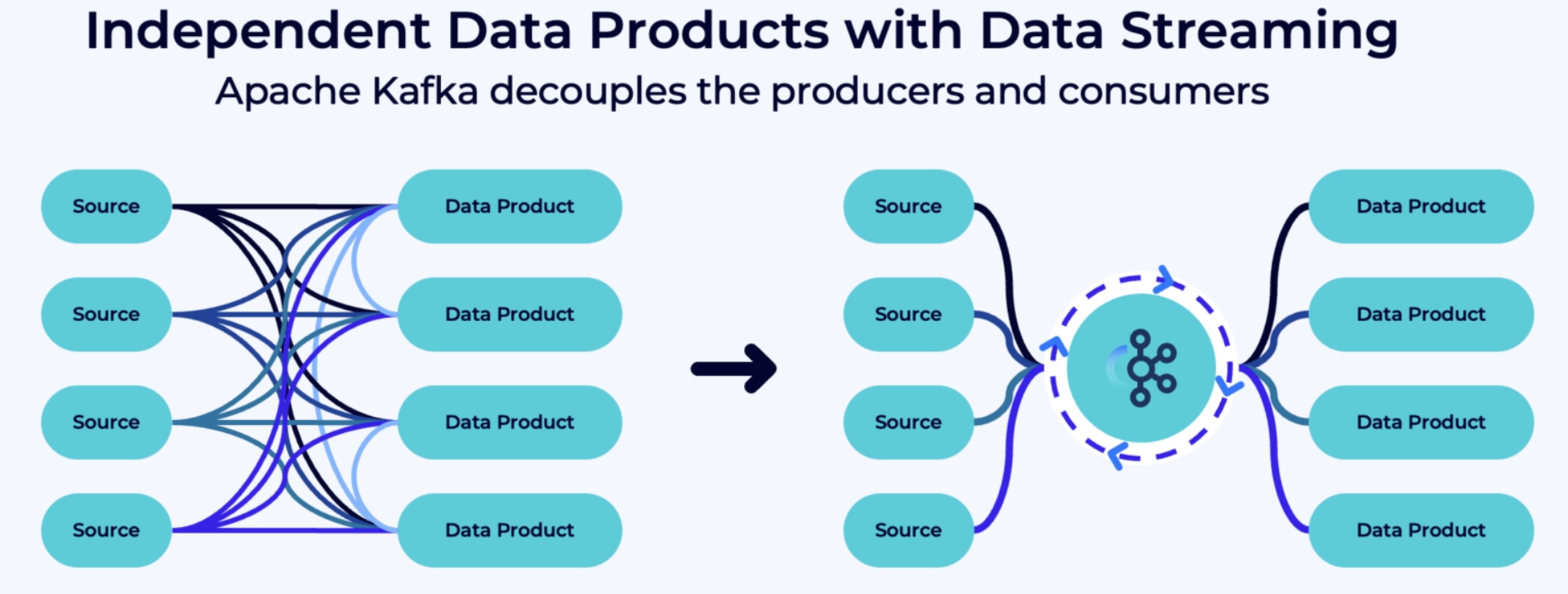
Source: Confluent
Instead of using DBT or similar tools to process data again and again at rest in Snowflake, consider pre-processing the data once in the streaming platform with technologies like Kafka Streams or Apache Flink and reduce the cost in Snowflake significantly. The consequence is that each data product consumes events of good data quality to focus on building business logic instead of ETL. And you can choose your favorite analytical query engine per use case or business unit.
Apache Iceberg as Standard Table Format to Unify Operational and Analytical Workloads
Apache Iceberg and competing technologies like Apache Hudi or Databricks' Delta Lake make the future integration between data streaming and data warehouses/data lakes even more interesting. I have already explored the adoption of Apache Iceberg as an open table format in between the streaming and analytics layer. Most vendors (including Confluent, Snowflake, and Amazon) already support Iceberg today.
How do you build data pipelines for Snowflake today? Already with Apache Kafka and a "shift left architecture", or still with traditional ETL tools? What do you think about Snowflake’s Snowpipe Streaming? Or do you already go all in with Apache Iceberg? Let’s connect on LinkedIn and discuss it!
Published at DZone with permission of Kai Wähner, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments