Revolutionizing Catalog Management for Data Lakehouse With Polaris Catalog
Achieve cross-query-engine interoperability and zero-data-copy architecture with Polaris Catalog, enhance data management, and streamline workflows.
Join the DZone community and get the full member experience.
Join For FreeThe data engineering landscape is evolving at a rapid pace, like many other areas of the software industry. While much of the spotlight is currently on AI/ML advancements, fueled by breakthroughs in large language models (LLMs) and generative AI, data engineering remains a foundational force driving innovation in software development.
Polaris, a catalog implementation tool for data lakehouse, is among the latest advancements in this field, accelerating progress in interoperability and enabling zero-data-copy architecture. At the recently concluded Snowflake Build conference in November 2024, Polaris Catalog was among the most talked about topics, along with Iceberg and AI/ML.
Open Table Format and Data Lakehouse
The concept of a data lakehouse with an open table format has become one of the most prominent topics in big data technologies. Open table format has been at the forefront in establishing data lakehouse patterns in the industry. While there are competing technologies for open table format, Iceberg is arguably the leader in this space. The data cloud giant Snowflake, which supports the traditional data warehouse pattern, is leading the industry with a data lakehouse pattern as well, with Iceberg as the backbone of the solution.
Iceberg's architecture shines with its three-layered architectural model. The root of that is a catalog which is the metadata holder for tables in Iceberg. Snowflake has brought in a revolution in the catalog space by building a catalog called Polaris which is fast gaining popularity and expected to grow in the coming months.
Before we talk in detail about Polaris, let’s take a step back and discuss a little more details about the data lakehouse, Iceberg, and Snowflake to set the stage for a discussion about Polaris. The software industry has been traditionally using data warehouses as analytical platforms for decades. The data lake emerged in 2010, driven by the rise of Hadoop-based big data technology that supports semi-structured and unstructured data. While the data lake grew rapidly over the last decade, it had its own set of problems, like lack of transactional support and absence of schema enforcement, to name a few.
The data lakehouse, the recent pattern in the big data world, emerged to solve the limitations of the data lake. The data lakehouse combined the benefits of a data warehouse and data lake by providing transactional support, schema enforcement like a data warehouse, as well as the support of heterogeneous data format like a data lake. Open file format, and especially open table format, serves as the foundation for the success of data lakehouse architecture. While there are other major players in an open table format like Delta Lake and Hudi, Iceberg stands out as a front-runner, backed by industry leader Snowflake.
Open table format was created to support zero copy of data and querying/mutating data in a single golden source from multiple query engines. Though Snowflake started with native tables like traditional, modern data warehouses and, along the way, also added support for unstructured data, Snowflake has been a leader in promoting and adopting an open table format with Iceberg to implement the data lakehouse solution.
The fundamental architecture concept of open table format is about storing table metadata. Open table format doesn’t store the actual data but the “data about data.” Different open table formats have their own metadata architecture. However, the common pattern in each of them is the presence of a catalog component. Catalog in open table format contains the metadata pointer for the actual tables that store the data in open file format (e.g., Parquet, ORC).
Challenges With Catalog: The Driver Behind Polaris
For the catalog implementation, there have been several technologies, such as Hive metastore, AWS Glue, Nessie, Unity Catalog, etc., that the industry has been using. This proliferation of available catalog technologies hindered interoperability and the zero data copy principle of open table format from reaching its full potential as different catalog technologies started causing vendor locking and data consistency issues in an organization. Figure 1 demonstrates the typical architecture that organizations have been implementing due to the lack of a unified catalog solution.
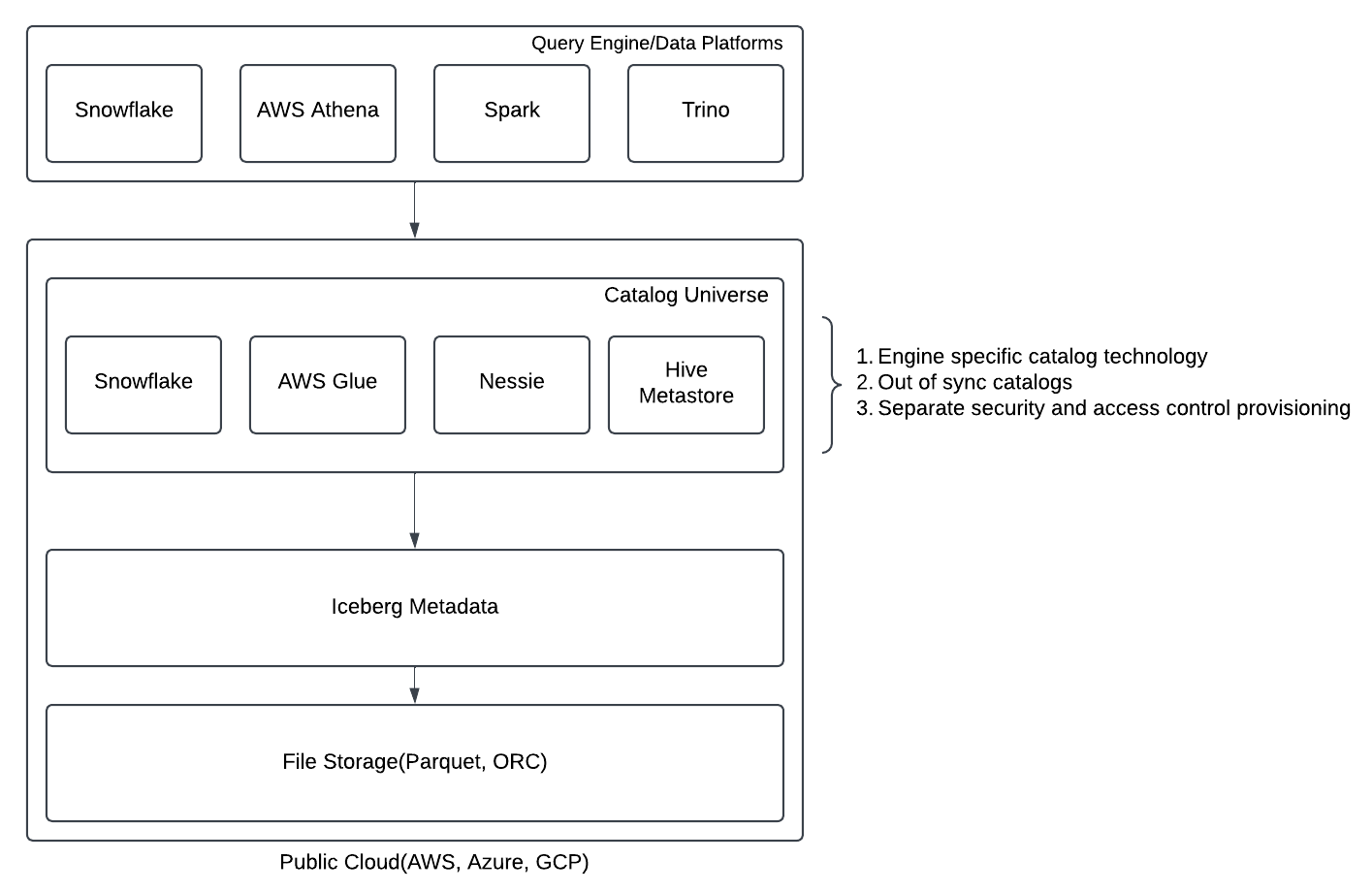 Figure 1: Multi-catalog technology solution in Iceberg Ecosystem
Figure 1: Multi-catalog technology solution in Iceberg Ecosystem
Different query engines or data platforms use catalogs developed in different technologies to access the metadata (Figure 1 above) and storage layer of Iceberg and, therefore, fail to provide a single view of the storage across the board in an organization. On top of this, without a shared standard of catalog, not only the catalog data is duplicated with inconsistencies, but other aspects such as security and access control provisioning need to be duplicated as well, causing unnecessary overhead.
To address this challenge of achieving true interoperability and zero data copy, Snowflake came up with the Polaris Catalog, a catalog with an aim to make it accessible for different query engines and also work as a catalog across all available open table formats (not just Iceberg) in the future.
About Polaris: Benefits and Current State
Polaris, as a catalog for open table format, provides primarily three benefits:
- Cross-engine interoperability for both read as well as write operations
- Enable hosting the catalog anywhere — in the cloud or at an organization’s data center as a containerized application
- Centralized security and role-based access control
Snowflake has outsourced the Polaris Catalog to Apache software foundation to encourage community-driven advancement of the technology and also to make it vendor-neutral to accomplish several long-term goals of Polaris, as listed below.
- Make it compatible across all open table formats (e.g., Delta Lake, Hudi)
- Support of table maintenance API
- Broader security and access control, such as support of IDP like Okta/Auth0, fine-grained access control, etc.
Currently, the Polaris software is incubating under the Apache software foundation. Even though Snowflake has outsourced Polaris to Apache, Snowflake continues to support the Polaris Catalog within its own deployment. The Snowflake-hosted Polaris Catalog is called the Snowflake Open Catalog.
Polaris Architecture
The architecture of the Polaris Catalog within the Iceberg ecosystem is demonstrated below in Figure 2. Query engines will use Polaris REST API to access table metadata in the Polaris Catalog. The core business logic of Polaris API will work as an interface to provide access to the actual data stored in open file format (e.g., Parquet, ORC) through Iceberg metadata.
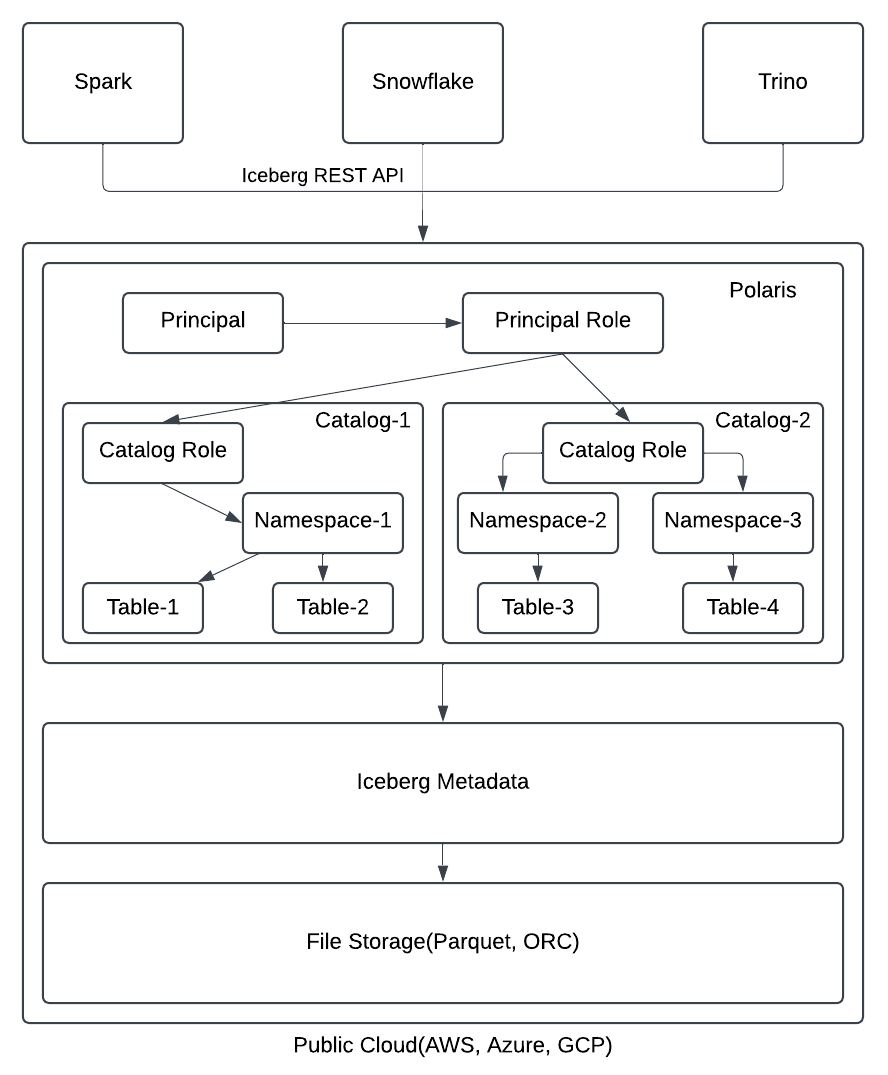
Figure 2: Polaris Architecture in Iceberg Ecosystem
Polaris architecture is structured around two core components: role-based access control (RBAC) for data security and the Data Catalog for managing metadata of tables. In RBAC, a Principal represents a user or system identity, while a Principal Role defines the permissions assigned to that Principal. A Principal can have multiple Principal Roles, and each Principal Role can include several Principals. On the catalog side, a Catalog serves as a logical database or schema organized into Namespaces that group Iceberg Tables or Views. Permissions are managed through Catalog Roles, which define direct privileges for catalog objects, whereas Principal Roles inherit these privileges through their association with Catalog Roles.
This architecture ensures secure, scalable, and efficient management of Iceberg tables and views within a logically organized framework.
From an infrastructure deployment standpoint, though Polaris can be run in a cloud platform as well as within an organization's data center as a containerized application, appropriate networking needs to be done for query engines to be able to access Polaris REST API-based catalog. It is not a very common use case at this moment to deploy the Polaris Catalog outside of public cloud platforms, as typically, we would expect the actual open file format storage to be in the cloud platform.
With the advancement of technology and to cater to data privacy and geo-restriction requirements for organizations across various sectors (e.g., Finance, healthcare), deploying Polaris within an organization's firewall might be a valuable use case down the line.
Hands-On With Polaris
Snowflake announced Polaris in June 2024 and then open-sourced to Apache Software Foundation in July. The project is currently in incubation status at Apache. The open-source version of the Polaris Catalog is available in the GitHub repository. It takes a few simple steps for a developer to get started with Polaris in a local workstation.
1. Install OpenJDK and Docker
The minimum version required for JDK is 21, and for Docker, it is 27. Apart from that Gradle needs to be installed as well to compile the project source code.
2. Clone the Repository
To set up Polaris in a local workstation, the first step is pretty obvious, which is cloning the repository.
3. Run Polaris in a Docker Container
docker compose -f docker-compose.yml up --build4. Run as a Local Java Application
gradle runAppThe Polaris project in GitHub is organized into two primary modules.
- polaris-core: This contains the entity definitions and business logic. This is the layer that interacts with open file format storage through Iceberg metadata
- API: Contains the definition of the REST API for Polaris. Query engines communicate with the API to get access to the underlying data
Conclusion
In the evolving landscape of data lakehouse and open table format, Polaris is the next big thing. This technology helps take the stride forward to eliminate the query engine-specific data catalog need and brings in an interoperable harmonized solution.
Polaris, originally built for Iceberg, not only aims to be the common platform for query engines, but future development targets this to work across other open table formats as well, such as Delta Lake. Having an interoperable catalog technology reduces complexity in the architecture of an organization, helps to achieve the zero-data-copy principle, reduces support overhead for IT, and, last but not least, cuts down costs for the organization. Polaris is growing, and its adoption is expected to rise under Apache Software Foundation and Snowflake in the coming months.
Opinions expressed by DZone contributors are their own.
Comments