Leveraging Event-Driven Data Mesh Architecture With AWS for Modern Data Challenges
Explore event-driven data mesh architecture, and how when combined with AWS, it becomes a robust solution for addressing complex data management challenges.
Join the DZone community and get the full member experience.
Join For FreeIn today's data-driven world, businesses must adapt to rapid changes in how data is managed, analyzed, and utilized. Traditional centralized systems and monolithic architectures, while historically sufficient, are no longer adequate to meet the growing demands of organizations that need faster, real-time access to data insights. A revolutionary framework in this space is event-driven data mesh architecture, and when combined with AWS services, it becomes a robust solution for addressing complex data management challenges.
The Data Dilemma
Many organizations face significant challenges when relying on outdated data architectures. These challenges include:
Centralized, Monolithic, and Domain Agnostic Data Lake
A centralized data lake is a single storage location for all your data, making it easy to manage and access but potentially causing performance issues if not scaled properly. A monolithic data lake combines all data handling processes into one integrated system, which simplifies setup but can be hard to scale and maintain. A domain-agnostic data lake is designed to store data from any industry or source, offering flexibility and broad applicability but may be complex to manage and less optimized for specific uses.
Traditional Architecture Failure Pressure Points
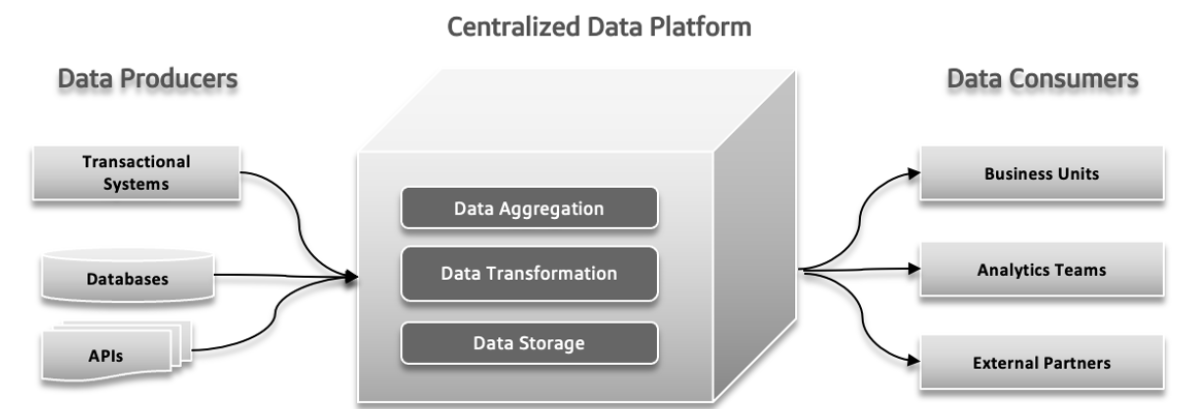
In traditional data systems, several problems can occur. Data producers may send large volumes of data or data with errors, creating issues downstream. As data complexity increases and more diverse sources contribute to the system, the centralized data platform can struggle to handle the growing load, leading to crashes and slow performance. Increased demand for rapid experimentation can overwhelm the system, making it hard to quickly adapt and test new ideas. Data response times may become a challenge, causing delays in accessing and using data, which affects decision-making and overall efficiency.
Divergence Between Operational and Analytical Data Landscapes
In software architecture, issues like siloed ownership, unclear data use, tightly coupled data pipelines, and inherent limitations can cause significant problems. Siloed ownership occurs when different teams work in isolation, leading to coordination issues and inefficiencies. Lack of a clear understanding of how data should be used or shared can result in duplicated efforts and inconsistent results. Coupled data pipelines, where components are too dependent on each other, make it difficult to adapt or scale the system, leading to delays. Finally, inherent limitations in the system can slow down the delivery of new features and updates, hindering overall progress. Addressing these pressure points is crucial for a more efficient and responsive development process.
Challenges With Big Data
Online Analytical Processing (OLAP) systems organize data in a way that makes it easier for analysts to explore different aspects of the data. To answer queries, these systems must transform operational data into a format suitable for analysis and handling large volumes of data. Traditional data warehouses use ETL (Extract, Transform, Load) processes to manage this. Big data technologies, like Apache Hadoop, improved data warehouses by addressing scaling issues and being open source, which allowed any company to use it as long as they could manage the infrastructure. Hadoop introduced a new approach by allowing unstructured or semi-structured data, rather than enforcing a strict schema upfront. This flexibility, where data could be written without a predefined schema and structured later during querying, made it easier for data engineers to handle and integrate data. Adopting Hadoop often meant forming a separate data team: data engineers handled data extraction, data scientists managed cleaning and restructuring, and data analysts performed analytics. This setup sometimes led to problems due to limited communication between the data team and application developers, often to prevent impacting production systems.
Problem 1: Issues With Data Model Boundaries
The data used for analysis is closely linked to its original structure, which can be problematic with complex, frequently updated models. Changes to the data model affect all users, making them vulnerable to these changes, especially when the model involves many tables.
Problem 2: Bad Data, The Costs of Ignoring the Problem
Bad data often goes unnoticed until it causes issues in a schema, leading to problems like incorrect data types. Since validation is often delayed until the end of the process, bad data can spread through pipelines, resulting in expensive fixes and inconsistent solutions. Bad data can lead to significant business losses, such as billing errors costing millions. Research indicates that bad data costs businesses trillions annually, wasting substantial time for knowledge workers and data scientists.
Problem 3: Lack of Single Ownership
Application developers, who are experts in the source data model, typically do not communicate this information to other teams. Their responsibilities often end at their application and database boundaries. Data engineers, who manage data extraction and movement, often work reactively and have limited control over data sources. Data analysts, far removed from developers, face challenges with the data they receive, leading to coordination issues and the need for separate solutions.
Problem 4: Custom Data Connections
In large organizations, multiple teams may use the same data but create their own processes for managing it. This results in multiple copies of data, each managed independently, creating a tangled mess. It becomes difficult to track ETL jobs and ensure data quality, leading to inaccuracies due to factors like synchronization issues and less secure data sources. This scattered approach wastes time, money, and opportunities.
Data mesh addresses these issues by treating data as a product with clear schemas, documentation, and standardized access, reducing bad data risks and improving data accuracy and efficiency.
Data Mesh: A Modern Approach
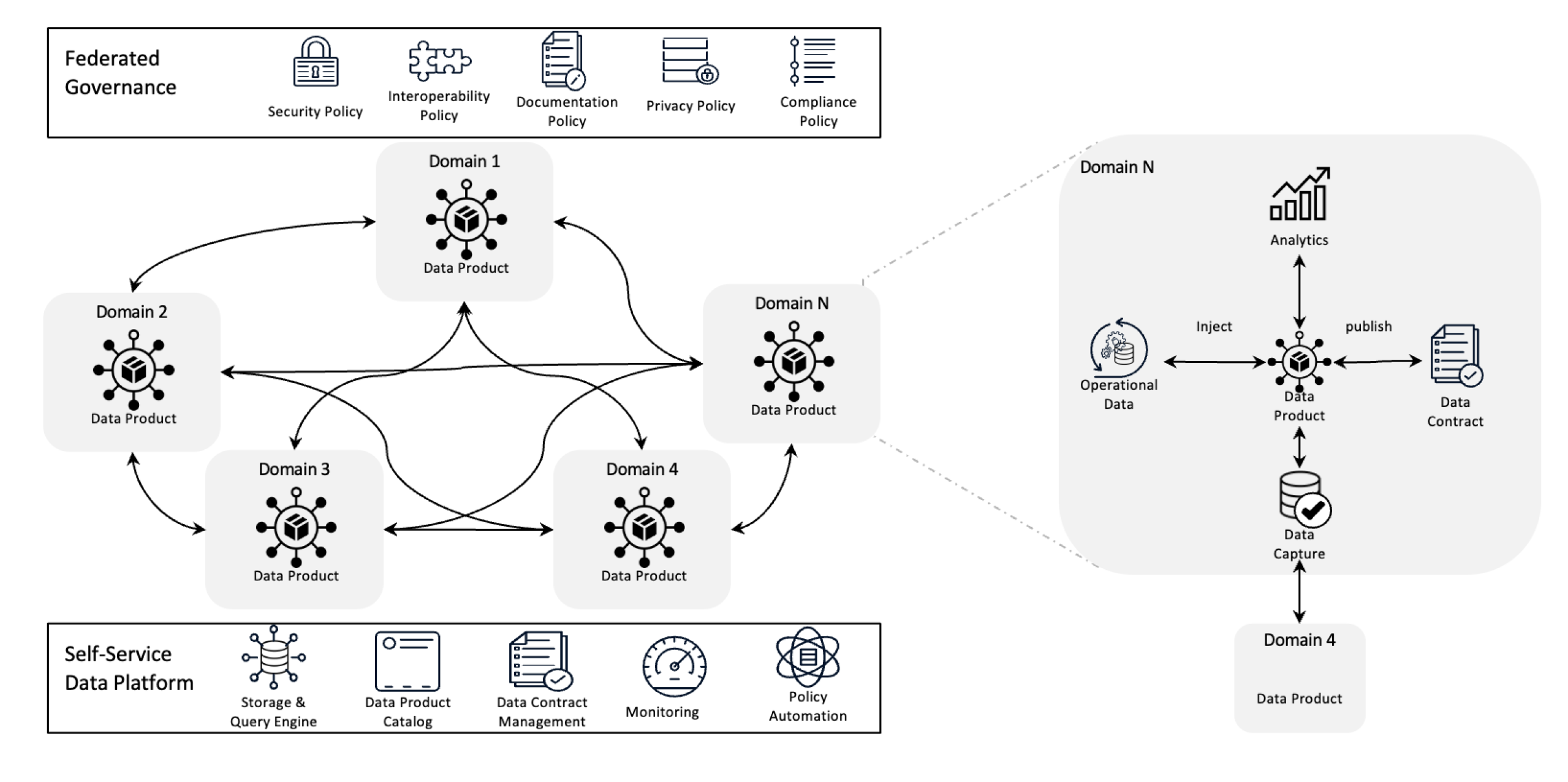
Data Mesh Architecture
Data mesh redefines data management by decentralizing ownership and treating data as a product, supported by self-service infrastructure. This shift empowers teams to take full control over their data while federated governance ensures quality, compliance, and scalability across the organization.
In simpler terms, It is an architectural framework that is designed to resolve complex data challenges by using decentralized ownership and distributed methods. It is used to integrate data from various business domains for comprehensive data analytics. It is also built on top of strong data sharing and governance policies.
Goals of Data Mesh
Data mesh helps various organizations get some valuable insights into the data at scale; in short, handling an ever-changing data landscape, the growing number of data sources and users, the variety of data transformations needed, and the need to quickly adapt to changes.
Data mesh solves all the above-mentioned problems by decentralizing control, so teams can manage their own data without it being isolated in separate departments. This approach improves scalability by distributing data processing and storage, which helps avoid slowdowns in a single central system. It speeds up insights by allowing teams to work directly with their own data, reducing delays caused by waiting for a central team. Each team takes responsibility for their own data, which boosts quality and consistency. By using easy-to-understand data products and self-service tools, data mesh ensures that all teams can quickly access and manage their data, leading to faster, more efficient operations and better alignment with business needs.
Key Principles of Data Mesh
- Decentralized data ownership: Teams own and manage their data products, making them responsible for their quality and availability.
- Data as a product: Data is treated like a product with standardized access, versioning, and schema definitions, ensuring consistency and ease of use across departments.
- Federated governance: Policies are established to maintain data integrity, security, and compliance, while still allowing decentralized ownership.
- Self-service infrastructure: Teams have access to scalable infrastructure that supports the ingestion, processing, and querying of data without bottlenecks or reliance on a centralized data team.
How Do Events Help Data Mesh?
Events help a data mesh by allowing different parts of the system to share and update data in real-time. When something changes in one area, an event notifies other areas about it, so everyone stays up-to-date without needing direct connections. This makes the system more flexible and scalable because it can handle lots of data and adapt to changes easily. Events also make it easier to track how data is being used and managed, and let each team handle their own data without relying on others.
Finally, let us look at the event-driven data mesh architecture.
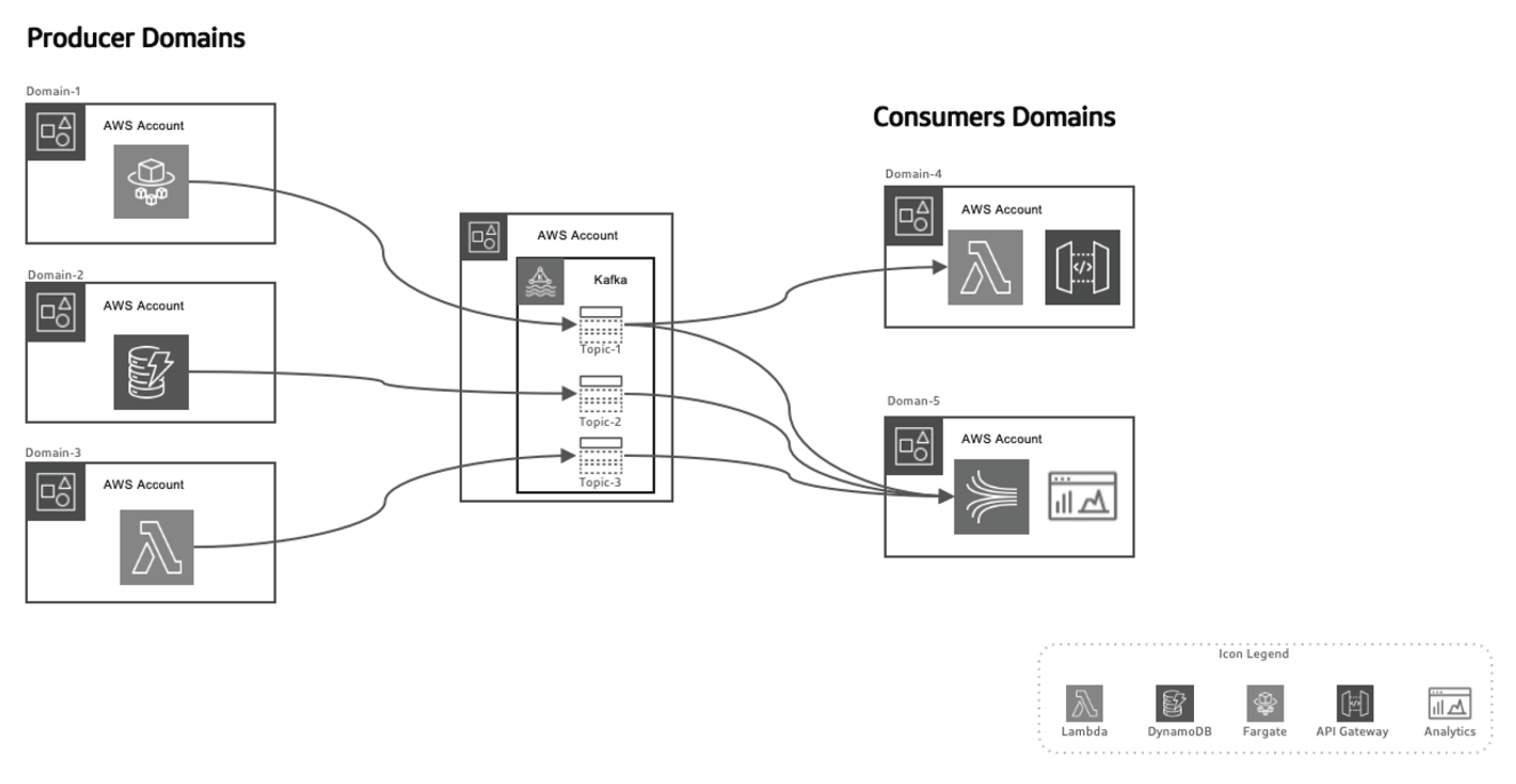
This event-driven approach lets us separate the producers of data from the consumers, making the system more scalable as domains evolve over time without needing major changes to the architecture. Producers are responsible for generating events, which are then sent to a data-in-transit system. The streaming platform ensures these events are delivered reliably. When a producer microservice or datastore publishes a new event, it gets stored in a specific topic. This triggers listeners on the consumer side, like Lambda functions or Kinesis, to process the event and use it as needed.
Leveraging AWS for Event-Driven Data Mesh Architecture
AWS offers a suite of services that perfectly complement the event-driven data mesh model, allowing organizations to scale their data infrastructure, ensure real-time data delivery, and maintain high levels of governance and security.
Here’s how various AWS services fit into this architecture:
AWS Kinesis for Real-Time Event Streaming
In an event-driven data mesh, real-time streaming is a crucial element. AWS Kinesis provides the ability to collect, process, and analyze real-time streaming data at scale.
Kinesis offers several components:
- Kinesis Data Streams: Ingest real-time events and process them concurrently with multiple consumers.
- Kinesis Data Firehose: Delivers event streams directly to S3, Redshift, or Elastic search for further processing and analysis.
- Kinesis Data Analytics: Processes data in real-time to derive insights on the fly, allowing immediate feedback loops in data processing pipelines.
AWS Lambda for Event Processing
AWS Lambda is the backbone of serverless event processing in the data mesh architecture. With its ability to automatically scale and process incoming data streams without requiring server management,
Lambda is an ideal choice for:
- Processing Kinesis streams in real-time
- Invoking API Gateway requests in response to specific events
- Interacting with DynamoDB, S3, or other AWS services to store, process, or analyze data
AWS SNS and SQS for Event Distribution
AWS Simple Notification Service (SNS) acts as the primary event broadcasting system, sending real-time notifications across distributed systems. AWS Simple Queue Service (SQS) ensures that messages between decoupled services are delivered reliably, even in the event of partial system failures. These services allow decoupled microservices to interact without direct dependencies, ensuring that the system remains scalable and fault-tolerant.
AWS DynamoDB for Real-Time Data Management
In decentralized architectures, DynamoDB provides a scalable, low-latency NoSQL database that can store event data in real time, making it ideal for storing the results of data processing pipelines. It supports the Outbox pattern, where events generated from the application are stored
in DynamoDB and consumed by the streaming service (e.g., Kinesis or Kafka).
AWS Glue for Federated Data Catalog and ETL
AWS Glue offers a fully managed data catalog and ETL service, essential for federated data governance in the data mesh. Glue helps catalog, prepare, and transform data in distributed domains, ensuring discoverability, governance, and integration across the organization.
AWS Lake Formation and S3 for Data Lakes
While the data mesh architecture moves away from centralized data lakes, S3 and AWS Lake Formation play a crucial role in storing, securing, and cataloging data that flows between various domains, ensuring long-term storage, governance, and compliance.
Event-Driven Data Mesh in Action With AWS and Python
Event Producer: AWS Kinesis + Python
In this example, we use AWS Kinesis to stream events when a new customer is created:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')Event Processing: AWS Lambda + Python
This Lambda function consumes Kinesis events and processes them in real time.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")Conclusion
By leveraging AWS services such as Kinesis, Lambda, DynamoDB, and Glue, organizations can fully realize the potential of event-driven data mesh architecture. This architecture provides agility, scalability, and real-time insights, ensuring that organizations remain competitive in today’s rapidly evolving data landscape. Adopting an event-driven data mesh architecture is not just a technical enhancement but a strategic imperative for businesses that want to thrive in the era of big data and distributed systems.
Opinions expressed by DZone contributors are their own.
Comments