Is RBAC Still Relevant in 2024?
Explore the state of Role-Based Access Control (RBAC), why and how developers should use it, and what are the best practices to implement it in applications.
Join the DZone community and get the full member experience.
Join For FreeOver the past few years, role-based access control (RBAC) has been considered synonymous with app-level authorization. It’s so common that developers casually describe their authorization service as an “RBAC service,” and CTOs describe it as “the thing we’ll implement at some point.”
On the other hand, applications are becoming increasingly complex by the pull request, and in most cases, a simple RBAC implementation just isn't enough. So does that mean RBAC is going obsolete? Should you start researching newer models? This blog will cover everything you need to know about using RBAC in 2024.
What Is RBAC?
Before we dive in, let's do a quick recap. RBAC is an authorization model used to determine access based on predefined roles. Permissions are assigned to roles (like “Admin or “User”), and roles are assigned to users. This structure allows you to understand who has access to what easily. The combination of who (which identity, and what role are they assigned?) can do what (what actions are they allowed to perform?) with a resource (on which aspects of the software?) is called a policy.
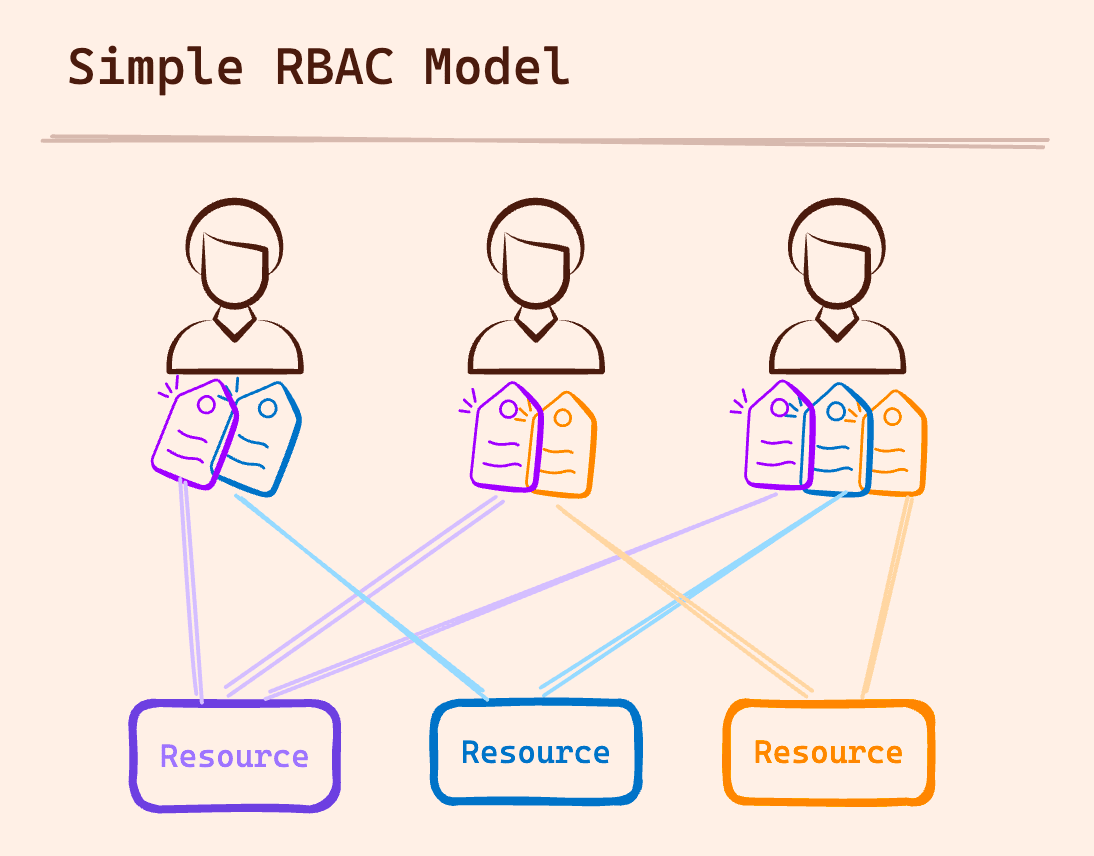
What Are the Benefits of RBAC?
RBAC’s main advantage comes from its simplicity. By categorizing users into roles and assigning permissions to these roles, RBAC creates a system that is easy and understandable for both developers and users.
For the developer, RBAC decouples the relationship between users and the permissions they need. Instead of explicitly assigning permissions to a user and applying that across different resources in the system, we assign permissions to roles and roles to users. That means that when we want to add more permissions, we can add them to a role instead of manually adding them to individual users. This means easy management and auditing.
For the user, RBAC makes app permissions easy to understand, with users not having to focus on how the app is built but rather on their own roles. Knowing if you are a standard user or an admin is a much more straightforward way of understanding the permissions you have within the app (Unlike ACLs and other, older models that were common before RBAC's popularity).
When Is RBAC Not Enough?
As simple as RBAC might be, that simplicity comes with a price, and RBAC doesn't work when a more fine-grained approach is needed. RBAC's user-centric approach makes the user the only dynamic component in the policy. That means that if we want to get more dynamic and granular policies, like, for example, where attributes of resources constantly change, RBAC proves insufficient. This issue is true for most modern applications, considering their complexity and the amount of data they rely on.
What brought RBAC to fame is the same thing that is now promoting the use of other models — user requirements. Users both have a better understanding of software, and they expect more control over their permissions than ever before. Things like privacy, data, and ownership are becoming very basic requirements that RBAC can no longer satisfy. This makes us ask whether RABC can be relevant at all.
How Can RBAC Be Useful Today?
Two prominent models have emerged in the past few years, threatening RBAC’s dominance of the authorization space: Relationship-Based Access Control (ReBAC) and Attribute-Based Access Control (ABAC).
ReBAC extends on basic RBAC by considering the in-app relationship between objects, users, and roles. If you look at something like a "Google Drive" style authorization system, you’ll quickly notice that it uses the baseline of roles, actions, and resources you already know from RBAC and extends upon them with relationships. The same goes for ABAC—it uses RBAC as a baseline structure and extends it by adding attributes to existing RBAC elements.
The simplicity of RBAC makes it a great baseline for modeling your authorization system, while other models, such as ABAC and ReBAC, are layered on top to cater to more granular requirements.
The Key: Policy-as-Code
As long as you implement RBAC while following the best practices, especially writing policy as code, it will help you cover the basics of your authorization requirements and allow you to extend it using other models if the need arises.
Defining policy as code allows us to create authorization policies that are not only readable but also provide us with the ability to ensure they are consistently enforced across different systems and environments, helping prevent policy violations and reducing the risk of unauthorized access. It allows you to easily manage and update policies, as you do that with the same tools and processes used to manage and deploy software. This makes it easier to track changes to policies over time, roll back changes if necessary, and in general, enjoy the well-thought-through best practices of the code world (e.g., GitOps).
If you embed your authorization by using policy-as-code or policy-as-graph, separating configuration and data, it becomes quite easy to scale from RBAC to more complex models.
RBAC is also great for streamlining your fine-grained authorization with feature-toggling - managing the visibility of resources in your frontend apps, with the frontend authorization layer benefiting from RBAC’s simplified abstraction and simplicity.
So, is RBAC still relevant? Of course, it is, maybe more than ever, because every complex architecture should have a simple baseline. But the challenge doesn't end there. . .
RBAC Enhanced: Live Data and Policy Updates
As we mentioned before, extending RBAC to other models is made even easier if we follow authorization best practices and base our authorization system on the policy as code. Since the nature of policy-as-code or policy-as-graph systems separates the concern between the configuration (code itself) and the data, it becomes easier to write policies that require less data, allowing us to benefit from RBAC’s simplicity while utilizing any required data with fine-grained models.
However, extensive amounts of data are still required to make most decisions in modern applications, and while using policy engines like OPA and Cedar provides us with a great basis for creating a separate microservice for authorization (allowing for a policy-as-code setup), there’s still the issue of keeping these engines up to date with the most relevant policies and data. Let’s look at a quick example.
Say our policy requires a user to be a subscriber to see parts of our site. To make a policy decision, we need to know the user’s subscription status from our billing service (e.g., PayPal or Stripe) and be immediately aware of any changes to it. A new subscriber expects immediate access to our site, and a churned user should lose access on the spot.
That means our policy engine needs to be updated in real time from outside data sources while all of our policy engines are in sync with each other.
Open Policy Administration Layer (OPAL) is an OSS project created to aid with Policy Engine management, which keeps them updated in real-time with data and policy updates. Supporting multiple policy engines, OPAL offers two important features:
- OPAL allows tracking a specific policy repository (like GitHub, GitLab, or Bitbucket) for updates. It does this by either using a webhook or checking for changes every few seconds. This makes the system act as a Policy Administration Point (PAP), which sends the policy changes to your policy engine, ensuring it is always up to date.
- The ability to track any relevant data source (API, database, external service) for updates via a REST API, and fetch up-to-date data back into your policy engine.
Using these capabilities allows you to take advantage of the full benefits of RBAC and more complex policy models by keeping your policy engines up to date with all the relevant policies and data in real time.
Published at DZone with permission of Gabriel L. Manor. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments