Introduction to Spark With Python: PySpark for Beginners
In this post, we take a look at how to use Apache Spark with Python, or PySpark, in order to perform analyses on large sets of data.
Join the DZone community and get the full member experience.
Join For FreeApache Spark is one the most widely used frameworks when it comes to handling and working with Big Data and Python is one of the most widely used programming languages for Data Analysis, Machine Learning, and much more. So, why not use them together? This is where Spark with Python also known as PySpark comes into the picture.
With an average salary of $110,000 per annum for an Apache Spark Developer, there's no doubt that Spark is used in the industry a lot. Because of its rich library set, Python is used by the majority of Data Scientists and Analytics experts today. Integrating Python with Spark was a major gift to the community. Spark was developed in the Scala language, which is very much similar to Java. It compiles the program code into bytecode for the JVM for Spark big data processing. To support Spark with Python, the Apache Spark community released PySpark. In this Spark with Python blog, I'll discuss the following topics.
- Introduction to Apache Spark and its features
- Why go for Python?
- Setting up Spark with Python (PySpark)
- Spark in Industry
- PySpark SparkContext and Data Flow
- PySpark KDD Use Case
Apache Spark is an open-source cluster-computing framework for real-time processing developed by the Apache Software Foundation. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
Below are some of the features of Apache Spark which gives it an edge over other frameworks:
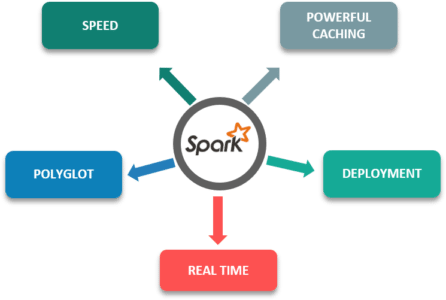
- Speed: It is 100x faster than traditional large-scale data processing frameworks.
- Powerful Caching: Simple programming layer provides powerful caching and disk persistence capabilities.
- Deployment: Can be deployed through Mesos, Hadoop via Yarn, or Spark's own cluster manager.
- Real Time: Real-time computation and low latency because of in-memory computation.
- Polyglot: It is one of the most important features of this framework as it can be programmed in Scala, Java, Python, and R.
Although Spark was designed in Scala, which makes it almost 10 times faster than Python, Scala is faster only when the number of cores being used is less. As most of the analyses and processes nowadays require a large number of cores, the performance advantage of Scala is not that much.

For programmers, Python is comparatively easier to learn because of its syntax and standard libraries. Moreover, it's a dynamically typed language, which means RDDs can hold objects of multiple types.

Although Scala has SparkMLlib it doesn't have enough libraries and tools for Machine Learning and NLP purposes. Moreover, Scala lacks Data Visualization.

Setting Up Spark With Python (PySpark)
I hope you guys know how to download Spark and install it. So, once you've unzipped the spark file, installed it and added it's path to the .bashrc file, you need to type in source .bashrc
export SPARK_HOME = /usr/lib/hadoop/spark-2.1.0-bin-hadoop2.7
export PATH = $PATH:/usr/lib/hadoop/spark-2.1.0-bin-hadoop2.7/binTo open PySpark shell, you need to type in the command ./bin/pyspark
Apache Spark, because of it's amazing features like in-memory processing, polyglot, and fast processing is being used by many companies all around the globe for various purposes in various industries:

Yahoo! uses Apache Spark for its Machine Learning capabilities to personalize its news and web pages and also for target advertising. They use Spark with Python to find out what kind of news users are interested in reading and categorizing the news stories to find out what kind of users would be interested in reading each category of news.
TripAdvisor uses Apache Spark to provide advice to millions of travelers by comparing hundreds of websites to find the best hotel prices for its customers. The time taken to read and process the reviews of the hotels in a readable format is done with the help of Apache Spark.
One of the world's largest e-commerce platforms, Alibaba, runs some of the largest Apache Spark jobs in the world in order to analyze hundreds of petabytes of data on its e-commerce platform.
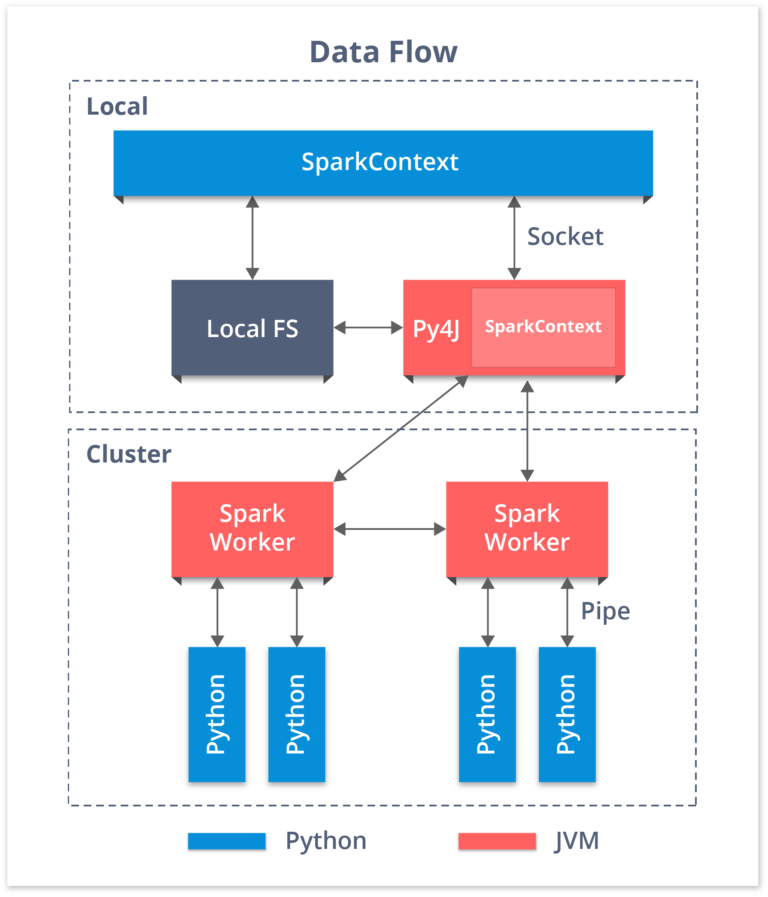
PySpark SparkContext and Data Flow
Talking about Spark with Python, working with RDDs is made possible by the library Py4j. PySpark Shell links the Python API to Spark Core and initializes the Spark Context. Spark Context is at the heart of any Spark application.
- Spark Context sets up internal services and establishes a connection to a Spark execution environment.
- The Spark Context object in driver program coordinates all the distributed processes and allows for resource allocation.
- Cluster Managers provide Executors, which are JVM processes with logic.
- Spark Context objects send the application to executors.
- Spark Context executes tasks in each executor.
PySpark KDD Use Case
Now let's have a look at a use case: KDD'99 Cup (International Knowledge Discovery and Data Mining Tools Competition). Here we will take a fraction of the dataset because the original dataset is too big.
import urllib
f = urllib.urlretrieve ("http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data_10_percent.gz", "kddcup.data_10_percent.gz")Creating RDD:
Now we can use this file to create our RDD.
data_file = "./kddcup.data_10_percent.gz"
raw_data = sc.textFile(data_file)Filtering
Suppose we want to count how many normal interactions we have in our dataset. We can filter our raw_data RDD as follows.
from time import time
t0 = time()
normal_count = normal_raw_data.count()
tt = time() - t0
print "There are {} 'normal' interactions".format(normal_count)
print "Count completed in {} seconds".format(round(tt,3))Count:
Now we can count how many elements we have in the new RDD.
from time import time
t0 = time()
normal_count = normal_raw_data.count()
tt = time() - t0
print "There are {} 'normal' interactions".format(normal_count)
print "Count completed in {} seconds".format(round(tt,3))Output:
There are 97278 'normal' interactions
Count completed in 5.951 secondsMapping:
In this case, we want to read our data file as a CSV formatted one. We can do this by applying a lambda function to each element in the RDD as follows. Here we will use the map() and take() transformation.
from pprint import pprint
csv_data = raw_data.map(lambda x: x.split(","))
t0 = time()
head_rows = csv_data.take(5)
tt = time() - t0
print "Parse completed in {} seconds".format(round(tt,3))
pprint(head_rows[0])Output:
Parse completed in 1.715 seconds
[u'0',
u'tcp',
u'http',
u'SF',
u'181',
u'5450',
u'0',
u'0',
.
.
u'normal.']Splitting:
Now we want to have each element in the RDD as a key-value pair where the key is the tag (e.g. normal) and the value is the whole list of elements that represents the row in the CSV formatted file. We could proceed as follows. Here we use line.split()and map().
def parse_interaction(line):
elems = line.split(",")
tag = elems[41]
return (tag, elems)
key_csv_data = raw_data.map(parse_interaction)
head_rows = key_csv_data.take(5)
pprint(head_rows[0])Output:
(u'normal.',
[u'0',
u'tcp',
u'http',
u'SF',
u'181',
u'5450',
u'0',
u'0',
u'0.00',
u'1.00',
.
.
.
.
u'normal.'])The Collect Action:
Here we are going to use the collect() action. It will get all the elements of RDD into memory. For this reason, it has to be used with care when working with large RDDs.
t0 = time()
all_raw_data = raw_data.collect()
tt = time() - t0
print "Data collected in {} seconds".format(round(tt,3))Output:
Data collected in 17.927 secondsThat took longer than any other action we used before, of course. Every Spark worker node that has a fragment of the RDD has to be coordinated in order to retrieve its part and then reduce everything together.
As a final example that will combine all the previous ones, we want to collect all the normal interactions as key-value pairs.
# get data from file
data_file = "./kddcup.data_10_percent.gz"
raw_data = sc.textFile(data_file)
# parse into key-value pairs
key_csv_data = raw_data.map(parse_interaction)
# filter normal key interactions
normal_key_interactions = key_csv_data.filter(lambda x: x[0] == "normal.")
# collect all
t0 = time()
all_normal = normal_key_interactions.collect()
tt = time() - t0
normal_count = len(all_normal)
print "Data collected in {} seconds".format(round(tt,3))
print "There are {} 'normal' interactions".format(normal_count)Output:
Data collected in 12.485 seconds
There are 97278 normal interactionsSo this is it, guys!
I hope you enjoyed this Spark with Python article. If you are reading this, congratulations! You are no longer a newbie to PySpark. Try out this simple example on your systems now.
Published at DZone with permission of Kislay Keshari, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments