Introduction to Event Streaming with Kafka and Kafdrop
Join the DZone community and get the full member experience.
Join For Free
Event sourcing, eventual consistency, microservices, CQRS... These are quickly becoming household names in mainstream application development. But do you know what makes them tick? What are the basic building blocks required to assemble complex, business-centric applications from fine-grained services without turning the lot into a big ball of mud?
This article examines a fundamental building block — event streaming. Leading the charge will be Apache Kafka — the de facto standard in event streaming platforms, which we'll observe through Kafdrop — a feature-packed web UI.
A Brief Intro
Event streaming platforms reside in the broader class of Message-oriented Middleware (MoM) and are similar to traditional message queues and topics but offer stronger temporal guarantees and typically order-of-magnitude performance gains due to log-structured immutability. In simple terms, write operations are mostly limited to sequential appends, which make them fast. Really fast.
Whereas messages in a traditional Message Queue (MQ) tend to be arbitrarily ordered and generally independent of one another, events (or records) in a stream tend to be strongly ordered, often chronologically or causally. Also, a stream persists its records, whereas an MQ will discard a message as soon as it has been read.
For this reason, event streaming tends to be a better fit for Event-Driven Architectures, encompassing event sourcing, eventual consistency, and CQRS concepts. (Of course, there are FIFO message queues too, but the differences between FIFO queues and fully-fledged event streaming platforms are quite substantial, not limited to ordering alone.)
Event streaming platforms are a comparatively recent paradigm within the broader MoM domain. There are only a handful of mainstream implementations available, compared to hundreds of MQ-style brokers, some going back to the 1980s (e.g. Tuxedo). Compared to established standards such as AMQP, MQTT, XMPP, and JMS, there are no equivalent standards in the streaming space.
Event streaming platforms are an active area of continuous research and experimentation. In spite of this, streaming platforms aren't just a niche concept or an academic idea with a few esoteric use cases; they can be applied effectively to a broad range of messaging and eventing scenarios, routinely displacing their more traditional counterparts.
You may also like: A Kafka Tutorial for Everyone, no Matter Your Stage in Development.
Architecture Overview
The diagram below offers a brief overview of the Kafka component architecture. While the intention isn't to indoctrinate you with all of Kafka's inner workings, some appreciation of its design will go a long way in explaining the key concepts that we will cover shortly.
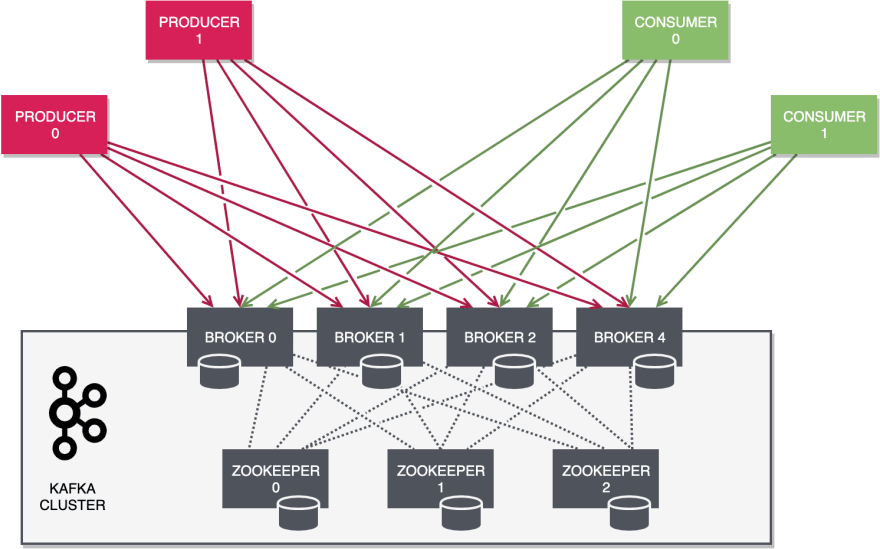
Kafka is a distributed system comprising several key components:
- Broker nodes: Responsible for the bulk of I/O operations and durable persistence within the cluster. Brokers accommodate the append-only log files that comprise the topic partitions hosted by the cluster. Partitions can be replicated across multiple brokers for both horizontal scalability and increased durability — these are called replicas. A broker node may act as the leader for certain replicas, while being a follower for others. A single broker node will also be elected as the cluster controller — responsible for the internal management of partition states. This includes the arbitration of the leader-follower roles for any given partition.
- ZooKeeper nodes: Under the hood, Kafka needs a way to manage the overall controller status in the cluster. Should the controller drop out for whatever reason, there is a protocol in place to elect another controller from the set of remaining brokers. The actual mechanics of controller election, heart-beating, and so forth, are largely implemented in ZooKeeper. ZooKeeper also acts as a configuration repository of sorts, maintaining cluster metadata, leader-follower states, quotas, user information, ACLs, and other housekeeping items. Due to the underlying gossiping and consensus protocol, the number of ZooKeeper nodes must be odd.
- Producers: These are client applications responsible for appending records to Kafka topics. Because of the log-structured nature of Kafka and the ability to share topics across multiple consumer ecosystems, only producers are able to modify the data in the underlying log files. The actual I/O is performed by the broker nodes on behalf of the producer clients. Any number of producers may publish to the same topic, selecting the partitions used to persist the records.
- Consumers: These are client applications that read from topics. Any number of consumers may read from the same topic; however, depending on the configuration and grouping of consumers, there are rules governing the distribution of records among the consumers.
Topics, Partitions, Records, and Offsets
A partition is a totally ordered sequence of records and is fundamental to Kafka. A record has an ID — a 64-bit integer offset and a millisecond-precise timestamp. Also, it may have a key and a value; both are byte arrays and both are optional. The term "totally ordered" simply means that for any given producer, records will be written in the order they were emitted by the application. If record P was published before Q, then P will precede Q in the partition. (Assuming P and Q share a partition.)
Furthermore, they will be read in the same order by all consumers; P will always be read before Q, for every possible consumer. This ordering guarantee is vital in a large majority of use cases. Published records will generally correspond to some real-life events, and preserving the timeline of these events is often essential.
Note: Kafka uses the term "record," where others might use "message" or "event." In this article, we will use the terms interchangeably, depending on the context. Similarly, you might see the term "stream" as a generic substitute for "topic."
There is no recognized ordering across producers. If two (or more) producers emit records simultaneously, those records may materialize in arbitrary order. That said, this order will still be observed uniformly across all consumers.
A record's offset uniquely identifies it in the partition. The offset is a strictly monotonically-increasing integer in a sparse address space, meaning that each successive offset is always higher than its predecessor and there may be varying gaps between neighboring offsets. Gaps might legitimately appear if compaction is enabled or as a result of transactions; we don't need to delve into the details at this stage. Suffice it to say that offsets need not be contiguous.
Your application shouldn't attempt to literally interpret an offset or guess what the next offset might be. It may, however, infer the relative order of any record pair based on their offsets, sort the records by their offset, and so forth.
The diagram below shows what a partition looks like on the inside.
start of partition
+--------+-----------------+
|0..00000|First record |
+--------+-----------------+
|0..00001|Second record |
+--------+-----------------+
|0..00002|Third record |
+--------+-----------------+
|0..00003|Fourth record |
+--------+-----------------+
|0..00007|Fifth record |
+--------+-----------------+
|0..00008|Sixth record |
+--------+-----------------+
|0..00010|Seventh record |
+--------+-----------------+
...
+--------+-----------------+
|0..56789|Last record |
+--------+-----------------+
end of partitionThe beginning offset, also called the low-water mark, is the first message that will be presented to a consumer. Due to Kafka's bounded retention, this is not necessarily the first message that was published. Records may be pruned on the basis of time and/or partition size. When this occurs, the low-water mark will appear to advance, and records earlier than the low-water mark will be truncated.
Conversely, the high-water mark is the offset immediately following the last record in the partition, also known as the end offset. It is the offset that will be assigned to the next record that will be published. It is not the offset of the last record.
A topic is a logical composition of partitions. A topic may have one or more partitions, and a partition must be a part of exactly one topic. Topics are fundamental to Kafka, allowing for both parallelism and load balancing.
Earlier, we said that partitions exhibit total order. Because partitions within a topic are mutually independent, the topic is said to exhibit partial order. In simple terms, this means that certain records may be ordered in relation to one another while being unordered with respect to certain other records. The concepts of total and partial order, while sounding somewhat academic, are hugely important in the construction of performant event streaming pipelines. They enables us to process records in parallel where we can, while maintaining order where we must. We'll explore the concepts of record order, consumer parallelism, and topic sizing in a short while.
Example: Publishing Messages
Let's put some of this theory into practice. We are going to spin up a pair of Docker containers — one for Kafka and another for Kafdrop. Rather than launching them individually, we'll use Docker Compose.
Create a docker-compose.yaml file in a directory of your choice, containing the following:
version: "2"
services:
kafdrop:
image: obsidiandynamics/kafdrop
restart: "no"
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka:29092"
depends_on:
- "kafka"
kafka:
image: obsidiandynamics/kafka
restart: "no"
ports:
- "2181:2181"
- "9092:9092"
environment:
KAFKA_LISTENERS: "INTERNAL://:29092,EXTERNAL://:9092"
KAFKA_ADVERTISED_LISTENERS: "INTERNAL://kafka:29092,EXTERNAL://localhost:9092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT"
KAFKA_INTER_BROKER_LISTENER_NAME: "INTERNAL"Note: We're using the
obsidiandynamics/kafkaimage for convenience because it neatly bundles Kafka and ZooKeeper into a single image. If you wanted to, you could replace this with images from Confluent or Wurstmeister, but then you'd have to wire it all up properly. Theobsidiandynamics/kafkaimage does all this for you, so it's highly recommended for beginners (and lazy pros).
Then, start it with docker-compose up. Once it boots, navigate to localhost:9000 in your browser. You should see the Kafdrop landing screen.
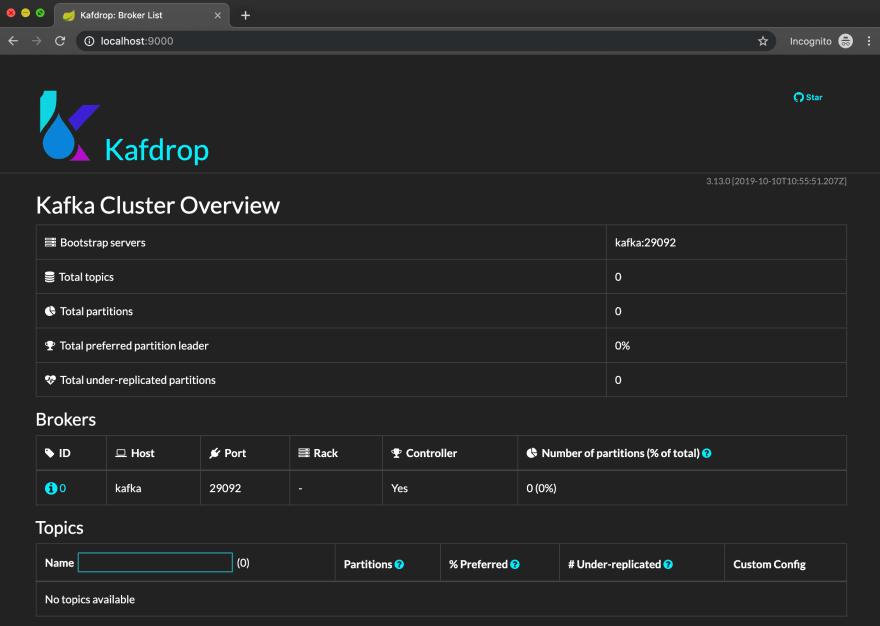
You should see our single-broker cluster. It's a promising start, but there are no topics. Not a problem; let's create a topic and publish some messages using Kafka's command-line tools. Conveniently, we already have a Kafka image running as part of our docker-compose stack, so we can shell into it to use the built-in CLI tools.
docker exec -it kafka-kafdrop_kafka_1 bashThis gets you into a Bash shell. The tools are in the /opt/kafka/bin directory, so let's cd into it:
cd /opt/kafka/binCreate a topic named streams-intro with three partitions:
./kafka-topics.sh --bootstrap-server localhost:9092 \
--create --partitions 3 --replication-factor 1 \
--topic streams-introSwitching back to Kafdrop, we should now see the new topic in the list.
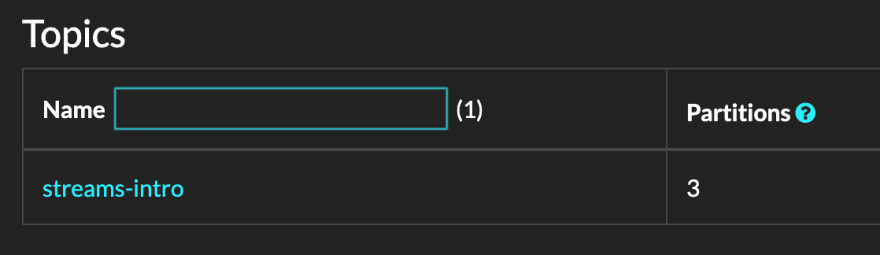
Time to publish stuff. We are going to use the kafka-console-producer tool:
./kafka-console-producer.sh --broker-list localhost:9092 \
--topic streams-intro --property "parse.key=true" \
--property "key.separator=:"Note:
kafka-topicsuses the--bootstrap-serverargument to configure the Kafka broker list, whilekafka-console-produceruses the--broker-listargument for the same purpose. Also,--propertyarguments are largely undocumented; be prepared to Google your way around.
Records are separated by newlines. The key and the value parts are delimited by colons, as indicated by the key.separator property. For the sake of an example, type in the following (a copy-paste will do):
foo:first message
foo:second message
bar:first message
foo:third message
bar:second messagePress CTRL+D when done. Then, switch back to Kafdrop and click on the streams-intro topic. You'll see an overview of the topic, along with a detailed breakdown of the underlying partitions:
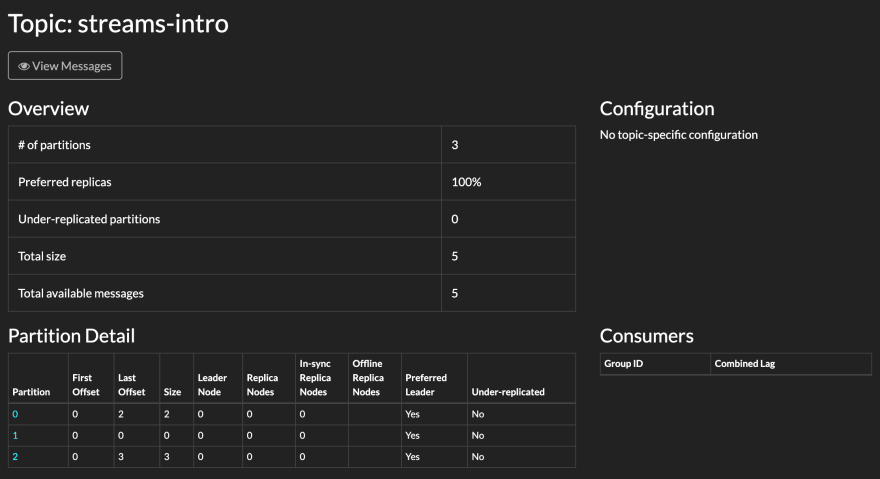
Let's pause for a moment and dissect what's been done. We created a topic with three partitions. We then published five records using two unique keys — foo and bar. Kafka uses keys to map records to partitions, such that all records with the same key will always appear on the same partition. Handy, but also important because it lets the publisher dictate the precise order of records. We'll discuss key hashing and partition assignments in more detail later; in the meanwhile, sit back and enjoy the ride.
Looking at the partitions table, partition #0 has the first and last offsets at zero and two respectively. Partition #2 has them at zero and three, while partition #1 appears to blank. Clicking on #0 in the Kafdrop web UI sends us to a topic viewer:
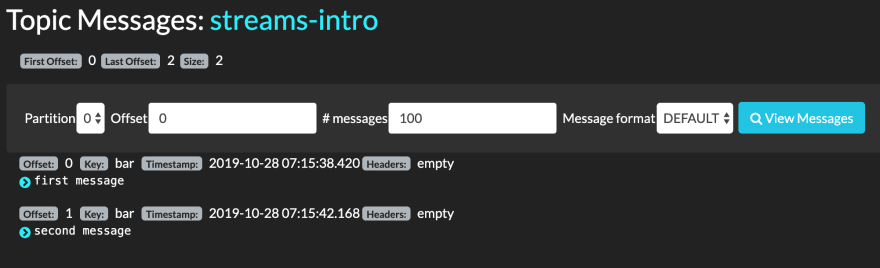
We can see the two records published under the bar key. Note, they are completely unrelated to the foo records. Other than being collated within the same topic, there is nothing that binds records across partitions.
Note: In case you were wondering, the arrow to the left of the message lets you expand and pretty-print JSON-encoded messages. As our examples didn't use JSON, there's nothing to pretty-print.
It can be said without exaggeration that Kafka's built-in tooling is an abomination. There is no consistency in the naming of command arguments and the simple act of publishing keyed messages requires you to jump through hoops — passing in obscure, undocumented properties. The usability of the built-in tools is a well-known heartache within the Kafka community. This is a real shame. It's like buying a Ferrari, only to have it delivered with plastic hub caps. Fortunately, there are alternatives — both commercial and open source — that can fill the glaring gaps in tooling and observability.
Consumers and Consumer Groups
So far we have learned that producers emit records into the stream; these records are organized into nicely ordered partitions. Kafka's pub-sub topology adheres to a flexible multipoint-to-multipoint model, meaning that there may be any number of producers and consumers simultaneously interacting with a stream. Depending on the actual solution context, stream topologies may also be point-to-multipoint, multipoint-to-point, and point-to-point. It's about time we looked at how records are consumed.
A consumer is a process or a thread that attaches to a Kafka cluster via a client library. (One is available for most languages.) A consumer generally, but not necessarily, operates as part of an encompassing consumer group. The group is specified by the group.id property. Consumer groups are effectively a load-balancing mechanism within Kafka — distributing partition assignments approximately evenly among the individual consumer instances within the group.
When the first consumer in a group joins the topic, it will receive all partitions in that topic. When a second consumer subsequently joins, it will get approximately half of the partitions, relieving the first consumer of half of its prior load. The process runs in reverse when consumers leave (by disconnecting or timing out) — the remaining consumers will absorb a greater number of partitions.
So, a consumer siphons records from a topic, pulling from the share of partitions that have been assigned to it by Kafka, alongside the other consumers in its group. As far as load-balancing goes, this should be fairly straightforward. But here's the kicker — the act of consuming a record does not remove it. This might seem contradictory at first, especially if you associate the act of consuming with depletion. (If anything, a consumer should have been called a 'reader', but let's not dwell on the choice of terminology.)
The simple fact is, consumers have absolutely no impact on topics and their partitions. A topic is an append-only ledger that may only be mutated by the producer, or by Kafka itself (as part of compaction or cleanup). Consumers are "cheap," so you can have quite a number of them tail the logs without stressing the cluster. This is yet another point of distinction between an event stream and a traditional message queue, and it's a crucial one.
A consumer internally maintains an offset that points to the next record in a partition, advancing the offset for every successive read. When a consumer first subscribes to a topic, it may elect to start at either the head-end or the tail-end of the topic. This behavior is controlled by setting the auto.offset.reset property to one of latest, earliest or none. In the latter case, an exception will be thrown if no previous offset exists for the consumer group.
Consumers retain their offset state vector locally. Since consumers across different consumer groups do not interfere, there may be any number of them reading concurrently from the same topic. Consumers run at their own pace — a slow or backlogged consumer has no impact on its peers.
To illustrate this concept, consider a scenario involving a topic with two partitions. Two consumer groups, A and B, are subscribed to the topic. Each group has three instances, the consumers being named A1, A2, A3, B1, B2, and B3. The diagram below illustrates how the two groups might share the topic and how the consumers advance through the records independently of one another.
Partition 0 Partition 1
+--------+ +--------+
|0..00000| |0..00000|
+--------+ +--------+
|0..00001| <= consumer A2 |0..00001|
+--------+ +--------+
|0..00002| |0..00002| <= consumer A1
+--------+ +--------+
|0..00003| |0..00003|
+--------+ +--------+
... ...
+--------+ +--------+
|0..00008| <= consumer B3 |0..00008| <= consumer B2
+--------+ +--------+
|0..00009| |0..00009|
+--------+ +--------+
producer P1 => |0..00010| |0..00010|
+--------+ +--------+
producer P1 => |0..00011|
+--------+
Look carefully and you'll notice something is missing. Consumers A3 and B1 aren't there. That's because Kafka guarantees that a partition may only be assigned to at most one consumer within its consumer group. (We say 'at most' to cover the case when all consumers are offline.) Because there are three consumers in each group, but only two partitions, one consumer will remain idle — waiting for another consumer in its respective group to depart before being assigned a partition.
In this manner, consumer groups are not only a load-balancing mechanism, but also a fence-like exclusivity control, used to build highly performant pipelines without sacrificing safety, particularly when there is a requirement that a record may only be handled by one thread or process at any given time.
Consumer groups are also used to ensure availability. By periodically pulling records from a topic, the consumer implicitly signals to the cluster that it's in a 'healthy' state, thereby extending the lease over its partition assignment. However, should the consumer fail to read again within the allowable deadline, it will be deemed faulty and its partitions will be reassigned — apportioned among the remaining 'healthy' consumers within its group. This deadline is controlled by the max.poll.interval.ms consumer client property, set to five minutes by default.
To use a transportation analogy, a topic is like a highway, while a partition is a lane. A record is the equivalent of a car, and its occupants correspond to the record's value. Several cars can safely travel on the same highway, providing they keep to their lane. Cars sharing the same line ride in a sequence, forming a queue. Now, suppose each lane leads to an off-ramp, diverting its traffic to some location. If one off-ramp gets banked up, other off-ramps may still flow smoothly.
It's precisely this highway-lane metaphor that Kafka exploits to achieve its end-to-end throughput, easily reaching millions of records per second on commodity hardware. When creating a topic, one can choose the partition count — the number of lanes, if you will.
The partitions are divided approximately evenly among the individual consumers in a consumer group, with a guarantee that no partition will be assigned to two (or more) consumers at the same time, providing that these consumers are part of the same consumer group. Referring to our analogy, a car will never end up in two off-ramps simultaneously; however, two lanes might conceivably lead to the same off-ramp.
Note: A topic may be resized after creation by increasing the number of partitions. It is not possible, however, to decrease the partition count without recreating the topic.
Records correspond to events, messages, commands, or any other streamable content. Precisely how records are partitioned is left to the discretion of the producer(s). A producer may explicitly assign a partition index when publishing a record, although this approach is rarely used. A much more common approach is to assign a key to a record, as we have done in our earlier example. The key is completely opaque to Kafka. In other words, Kafka doesn't attempt to interpret the contents of the key, treating it as an array of bytes. These bytes are hashed to derive a partition index, using a consistent hashing technique.
Records sharing the same hash are guaranteed to occupy the same partition. Assuming a topic with multiple partitions, records with a different key will likely end up in different partitions. However, due to hash collisions, records with different hashes may also end up in the same partition. Such is the nature of hashing. If you understand how a hash table works, this is no different.
Producers rarely care which specific partition the records will map to, only that related records end up in the same partition, and that their order is preserved. Similarly, consumers are largely indifferent to their assigned partitions, so long that they receive the records in the same order as they were published, and their partition assignment does not overlap with any other consumer in their group.
Committing Offsets
We already said that consumers maintain an internal state with respect to their partition offsets. At some point, that state must be shared with Kafka, so that when a partition is reassigned, the new consumer can resume processing from where the outgoing consumer left off. Similarly, if the consumers were to disconnect, upon reconnection they would ideally skip over those records that have already been processed.
Persisting the consumer state back to the Kafka cluster is called committing an offset. Typically, a consumer will read a record (or a batch of records) and commit the offset of the last record, plus one. If a new consumer takes over the topic, it will commence processing from the last committed offset, hence the plus-one step is essential. (Otherwise, the last processed record would be handled a second time.)
Fun fact: Kafka employs a recursive approach to managing committed offsets, elegantly utilising itself to persist and track offsets. When an offset is committed, Kafka will publish a binary record on the internal
__consumer_offsetstopic. The contents of this topic are compacted in the background, creating an efficient event store that progressively reduces to only the last known commit points for any given consumer group.
Controlling the point when an offset is committed provides a great deal of flexibility around delivery guarantees, handing Kafka a yet another trump card. The term 'delivery' assumes not just reading a record, but the full processing cycle, complete with any side-effects. One can shift from an at-most-once to an at-least-once delivery model by simply moving the commit operation from a point before the processing of a record is commenced, to a point sometime after the processing is complete. With this model, should the consumer fail midway through processing a record, the record will be re-read the following partition reassignment.
By default, a Kafka consumer will automatically commit offsets every five seconds, regardless of whether the consumer has finished processing the record. Often, this is not what you want, as it may lead to mixed delivery semantics. For example, in the event of consumer failure, some records might be delivered twice, while others might not be delivered at all. To enable manual offset committing, set the enable.auto.commit property to false.
Note: There are a few gotchas like this in Kafka. Pay close attention to the (producer and consumer) client properties in the official Kafka documentation, particularly to the stated defaults. Don't assume for a moment that the defaults are sensible, insofar as they ought to favour safety over other competing qualities. Kafka defaults tend to be optimised for performance, and will need to be explicitly overridden on the client when safety is a critical objective. Fortunately, setting the properties to insure safety has only a minor impact on performance — Kafka is still a beast. Remember the first rule of optimisation: Don't do it. Kafka would have been even better, had their creators given this more thought.
Getting offset committing right can be tricky, and routinely catches out beginners. A committed offset implies that the record one below that offset and all prior records have been dealt with by the consumer. When designing at-least-once or exactly-once applications, an offset should only be committed when the application is dealt with with the record in question and all records before it.
In other words, the record has been processed to the point that any actions that would have resulted from the record have been carried out and finalized. This may include calling other APIs, updating a database, committing transactions, persisting the record's payload, or publishing more records. Stated otherwise, if the consumer were to fail after committing the record, then not ever seeing this record again must not be detrimental to its correctness.
In the at-least-once (and by extension, the exactly-once) scenario, a typical consumer implementation will commit its offset linearly, in tandem with the processing of the records. That is, read a record, commit it (plus-one), read the next, commit it (plus one), and so on. A common tactic is to process a batch of records concurrently (where this makes sense), using a thread pool, and only confirm the last record when the entire batch is done. The commit process in Kafka is very efficient, the client library will send commit requests asynchronously to the cluster using an in-memory queue, without blocking the consumer. The client application can register an optional callback, notifying it when the commit has been acknowledged by the cluster.
The consumer group is a somewhat understated concept that is pivotal to the versatility of an event streaming platform. By simply varying the affinity of consumers with their groups, one can arrive at vastly different distribution topologies — from a topic-like, pub-sub behavior to an MQ-style, point-to-point model. Because records are never truly consumed (the advancing offset only creates the illusion of consumption), one can concurrently superimpose disparate distribution topologies over a single event stream.
Free Consumers
Consumer groups are completely optional; a consumer does not need to be encompassed in a consumer group to pull messages from a topic. A free consumer omits the group.id property. Doing so allows it to operate under relaxed rules, entirely transferring the responsibility for consumer management to the application.
Note: The use of the term 'free' to denote a consumer without an encompassing group is not part of the standard Kafka nomenclature. As Kafka lacks a canonical term to describe this, the term 'free' was adopted here.
Free consumers do not subscribe to a topic. Instead, the consuming application is responsible for manually assigning a set of topic-partitions to the consumer, individually specifying the starting offset for each topic-partition pair. Free consumers do not commit their offsets to Kafka; it is up to the application to track the progress of such consumers and persist their state as appropriate, using a datastore of their choosing. The concepts of automatic partition assignment, rebalancing, offset persistence, partition exclusivity, consumer heart-beating and failure detection, and other so-called niceties accorded to consumer groups cease to exist in this mode.
Free consumers are not observed in the wild as often as their grouped counterparts. There are predominantly two use cases where a free consumer is an appropriate choice. The first, is when you genuinely need full control of the partition assignment scheme and/or you require an alternative place to store consumer offsets. This is very rare.
Needless to say, it's also very difficult to implement correctly, given the multitude of scenarios one must account for. The second, more commonly seen use case, is when you have a stateless or ephemeral consumer that needs to monitor a topic. For example, you might be interested in tailing a topic to identify specific records, or just as a debugging tool. You might only care about records that were published when your stateless consumer was online, so concerns such as persisting offsets and resuming from the last processed record are completely irrelevant.
A good example of where this is used routinely is the Kafdrop web UI, which we've already seen. When you click on a topic to view the messages, Kafdrop creates a free consumer and assigns the requested partition to it, reading the records from the supplied offsets. Navigating to a different topic or partition will reset the consumer, discarding any prior state.
The illustration below outlines the relationship between producers, topics, partitions, consumers, and consumer groups.
+----------+ +----------+
|PRODUCER 1| |PRODUCER 2|
+-----v----+ +-----v----+
| |
| |
| |
+----V---------------------V-----------------------------------------+
| >>> TOPIC >>> |
| +---------------------------------------------------+ |
| PARTITION 0|record 0..00|record 0..01|record 0..02|record 0..03| |
| +--------------------v------------------------------+ |
| | |
| +--------------------|------------------------------+ |
| PARTITION 1|record 0..00| | |record 0..02|record 0..03| |
| +--------------------|-------------v----------------+ |
| | | |
+----------v----------------------|-------------|--------------------+
| | |
| | |
| | |
| +-------|-------------|----------------------+
| | | | |
+----V-----+ | +-----V----+ +----V-----+ +----------+ |
|CONSUMER 1| | |CONSUMER 2| |CONSUMER 3| |CONSUMER 4| |
+----------+ | +----------+ +----------+ +----------+ |
| CONSUMER GROUP |
+--------------------------------------------+
The key takeaways are:
- Topics are subdivided into partitions, each forming an independent, totally-ordered sequence within a wider, partially-ordered stream.
- Multiple producers are able to publish to a topic, picking a partition at will. This may be accomplished either directly, by specifying a partition index, or indirectly, by way of a record key, which deterministically hashes to a consistent partition index. (In the diagram above, both Producer 1 and Producer 2 publish to the same topic.)
- Partitions in a topic can be load-balanced across a population of consumers in a consumer group, allocating partitions approximately evenly among the members of that group. (Consumer 2 and Consumer 3 each get one partition.)
- A consumer in a group is not guaranteed a partition assignment. Where the group's population outnumbers the partitions, some consumers will remain idle until this balance equalizes or tips in favor of the other side. (Consumer 4 remains partition-less.)
- Partitions may be manually assigned to free consumers. If necessary, an entire topic may be assigned to a single free consumer — this is done by individually assigning all partitions. (Consumer 1 can be freely assigned any partition.)
Exactly-Once Delivery
When contrasting at-least-once with at-most-once delivery semantics, an often-asked question is: Why can't we have it exactly once?
Without delving into the academic details, which involve conjectures and impossibility proofs, it is sufficient to say that exactly-once semantics are not possible without collaboration with the consumer application. What does this mean in practice?
Consumers in event streaming applications must be idempotent. In other words, processing the same record repeatedly should have no net effect on the consumer ecosystem. If a record has no additive effects, the consumer is inherently idempotent. (For example, if the consumer simply overwrites an existing database entry with a new one, then the update is naturally idempotent.) Otherwise, the consumer must check whether a record has already been processed, and to what extent, prior to processing a record. The combination of at-least-once delivery and consumer idempotence collectively leads to exactly-once semantics.
Example: A Trading Platform
With all this theory looming over us like Kubrick's Monolith, it would be inappropriate to conclude without offering the reader a practical scenario.
Let's say you were looking for specific price patterns in listed stocks, emitting trading signals when a particular pattern is identified. There are a large number of stocks, and understandably you'd like them processed in parallel. However, the time series for any given ticker code must be processed sequentially on a single consumer.
Kafka makes this use case, and others like it, almost trivial to implement. We would create a pair of topics: prices for the raw price data, and orders for any resulting orders. We can be fairly generous with our partition counts, as the nature of the data gives us ample opportunities for parallelism.
At the feed source, we could publish a record for each price on the prices topic, keyed by the ticker code. Kafka's automatic partition assignment will ensure that every ticker code is handled by (at most) one consumer in its group. The consumer instances are free to scale in and out to match the processing load. Consumer groups should be meaningfully named, ideally reflecting the purpose of the consuming application. A good example might be trading-strategy.abc, for a fictitious trading strategy named 'ABC'.
Once a price pattern is identified by the consumer, it can publish another message — the order request — on the orders topic. We'll muster up another consumer group — order-execution — responsible for reading the orders and forwarding them to the broker.
In this simple example, we have created an end-to-end trading pipeline that is entirely event-driven and highly scalable — at least theoretically, assuming there are no other bottlenecks. We can dynamically add more processing nodes to the individual stages to cope with the increased load where it's called for.
Now, let's spice things up a bit. Suppose you need several trading strategies operating concurrently, driven by a common data feed. Furthermore, the trading strategies will be developed by different teams; the objective being to decouple these implementations as much as possible, allowing the teams to operate autonomously — develop and deploy at their individual cadence, perhaps even using different programming languages and tool-chains. That said, you'd ideally want to reuse as much of what's already been written. So, how would we pull this off?
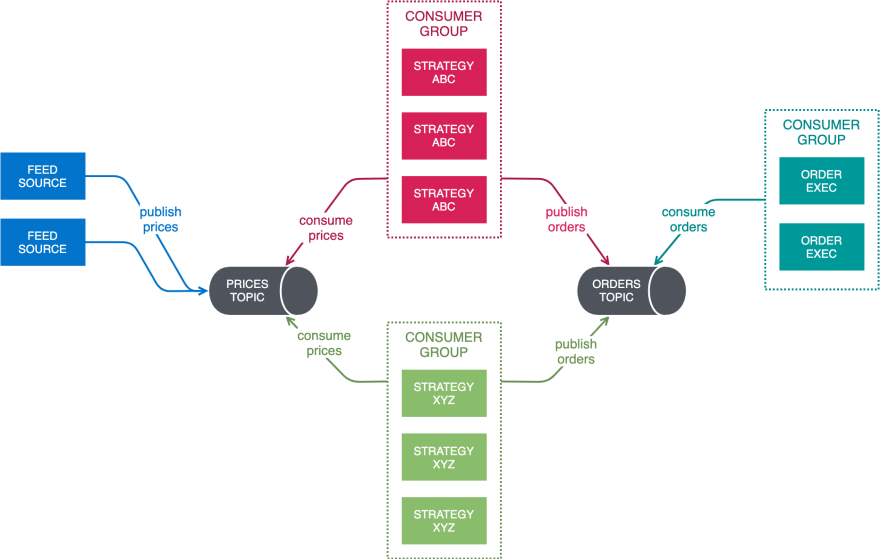
Kafka's flexible multipoint-to-multipoint pub-sub architecture combines stateful consumption with broadcast semantics. Using distinct consumer groups, Kafka allows disparate applications to share input topics, processing events at their own pace. The second trading strategy would need a dedicated consumer group — trading-strategy.xyz — applying its specific business logic to the common pricing stream, publishing the resulting orders to the same orders topic. In this fashion, Kafka enables you to construct modular event processing pipelines from discrete elements that are readily reusable and composable.
Note: In the days of service buses and traditional 'enterprisey' message brokers, before event sourcing entered the mainstream, you would have had to choose between persistent message queues or transient broadcast topics. In our example, you would likely have created multiple FIFO queues, using the fan-out pattern. Because Kafka generalises pub-sub topics and persistent message queues into a unified model, a single source topic can power a diverse range of consumers without incurring duplication.
In Conclusion
Event streaming platforms are a highly effective building block in the construction of modular, loosely-coupled, event-driven applications. Within the world of event streaming, Kafka has solidified its position as the go-to open-source solution that is both amazingly flexible and highly performant. Concurrency and parallelism are at the heart of Kafka's architecture, forming partially-ordered event streams that can be load-balanced across a scalable consumer ecosystem. A simple reconfiguration of consumers and their encompassing groups can bring about vastly different event distribution and processing semantics; shifting the offset commit point can invert the delivery guarantee from an at-most-once to an at-least-once model.
Of course, Kafka isn't without its flaws. The tooling is sub-par, to put it mildly; most Kafka practitioners have long abandoned the out-of-the-box CLI utilities in favour of other open-source tools such as Kafdrop, Kafkacat and third-party commercial offerings like Kafka Tool. The breadth of Kafka's configuration options is overwhelming, with defaults that are riddled with gotchas, ready to shock the unsuspecting first-time user.
All in all, Kafka represents a paradigm shift in how we architect and build complex systems. Its benefits go beyond the superfluous, and they dwarf any of the niggles that are bound to exist in a technology that has undergone such aggressive adoption. Crucially, it paves the way for further progress in its space; Apache Pulsar is a prime example of an alternative platform that has improved on much of Kafka's shortcomings, yet owes a great deal to its predecessor for laying the cornerstone and bringing the genre to the mainstream.
~ ~ ~
Was this article useful to you? Take a moment to like it, so others might spot it too. I'd love to hear your feedback, so don't hold back! If you are interested in Kafka or event streaming, or just have any questions, follow me on Twitter.
Further Reading
Published at DZone with permission of Emil Koutanov. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments