Introduction to Azure Data Lake Storage Gen2
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for big data analytics.
Join the DZone community and get the full member experience.
Join For FreeBuilt on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for big data analytics.
Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics. You will also receive low-cost, tiered storage with high availability and disaster recovery capabilities because these capabilities are built on Blob storage.
Developed for Enterprise Huge Data Analytics
Azure Storage is now the starting point for creating enterprise data lakes on Azure, thanks to Data Lake Storage Gen2. Data Lake Storage Gen2, created from the ground up to support many petabytes of data while supporting hundreds of gigabits of throughput, enables you to easily manage enormous volumes of data.
The expansion of Blob storage to include a hierarchical namespace is a key component of Data Lake Storage Gen2. For effective data access, the hierarchical namespace groups object and files into a hierarchy of folders. Slashes are frequently used in object storage names to simulate a hierarchical directory structure. The advent of Data Lake Storage Gen2 makes this arrangement a reality. Operations on a directory, including renaming or removing it, become single atomic metadata operations. There is no requirement to enumerate and handle every object that shares the directory's name prefix.
Blob storage is a foundation for Data Lake Storage Gen2, which improves administration, security, and performance in the following ways:
Performance
As a result of not needing to replicate or change data before analysis, performance is optimized. In addition, the hierarchical namespace on Blob storage performs directory management activities far better than the flat namespace does, which enhances job performance.
Management
Because you can arrange and manage files using directories and subdirectories, management is simpler.
Security
Because POSIX permissions can be set on folders or specific files, security is enforceable.
Additionally, Data Lake Storage Gen2 is relatively affordable because it is based on the inexpensive Azure Blob Storage. The additional functionalities reduce the overall cost of ownership for using Azure to execute big data analytics.
Important Characteristics of Data Lake Storage Gen2
- Data Lake Storage Gen2 enables you to organize and access data in a manner that is comparable to that of a Hadoop Distributed File System (HDFS). All Apache Hadoop settings support the new ABFS driver, which is used to access data. Azure HDInsight, Azure Databricks, and Azure Synapse Analytics are some examples of these environments.
- ACLs and POSIX permissions are supported by the security model for Data Lake Gen2, as well as additional granularity unique to Data Lake Storage Gen2. In addition, frameworks like Hive and Spark, as well as Storage Explorer, allow for the configuration of settings.
- Cost-effective: Low-cost storage space and transactions are available with Data Lake Storage Gen2. Thanks to features like Azure Blob Storage lifecycle, costs are reduced as data moves through its lifecycle.
- Driver optimization: The ABFS driver has been tailored for big data analytics. The endpoint dfs.core.windows.net exposes the corresponding REST APIs.
Scalability
Whether you access via Data Lake Storage Gen2 or Blob storage interfaces, Azure Storage is scalable by design. Many exabytes of data can be stored and served by it. The throughput for this quantity of storage is measured in gigabits per second (Gbps) at high input/output operation rates per second (IOPS). Latencies for processing are monitored at the service, account, and file levels and are nearly constant per request. Whether you access via Data Lake Storage Gen2 or Blob storage interfaces, Azure Storage is scalable by design. Many exabytes of data can be stored and served by it. The throughput for this quantity of storage is measured in gigabits per second (Gbps) at high input/output operation rates per second (IOPS). Latencies for processing are monitored at the service, account, and file levels and are nearly constant per request.
Cost-Effectiveness
Storage capacity and transaction costs are lower since Data Lake Storage Gen2 is built on top of Azure Blob Storage. You don't need to relocate or change your data before you can study it, unlike other cloud storage providers. Visit Azure Storage pricing for additional details on pricing.
The overall performance of many analytics activities is also greatly enhanced by features like the hierarchical namespace. Because of the increase in performance, processing the same amount of data now requires less computing power, which lowers the total cost of ownership (TCO) for the entire analytics project.
A Single Service, Many Ideas
Since Data Lake Storage Gen2 is based on Azure Blob Storage, the same shared objects can be described by several concepts.
The following are identical objects that are described by various concepts. Unless otherwise stated, the following terms are directly synonymous:
Concept |
Top Level Organization |
Lower-Level Organization |
Data Container |
Blobs - General purpose object storage |
Container |
Virtual directory (SDK only - doesn't provide atomic manipulation) |
Blob |
Azure Data Lake Storage Gen2 - Analytics Storage |
Container |
Directory |
File |
Blob Storage-Supporting Features
Your account has access to Blob Storage capabilities like diagnostic logging, access tiers, and Blob Storage lifecycle management policies. Most Blob Storage features are fully supported, although some are only supported in preview mode or not at all.
See Blob Storage feature support in Azure Storage accounts for further information on how each Blob Storage feature is supported with Data Lake Storage Gen2.
Supported Integrations of Azure Services
Several Azure services are supported by Data Lake Storage gen2. They can be used to perform analytics, produce visual representations, and absorb data. See Azure services that support Azure Data Lake Storage Gen2 for a list of supported Azure services.
Open-Source Platforms That Are Supported
Data Lake Storage Gen2 is supported by several open-source platforms. See Open-source platforms that support Azure Data Lake Storage Gen2 for a comprehensive list.
Utilizing Azure Data Lake Storage Gen2 Best Practices
The Gen2 version of Azure Data Lake Storage is not a specific service or account type. It is a collection of tools for high-throughput analytical tasks. Best practices and instructions for exploiting these capabilities are provided in the Data Lake Storage Gen2 reference. See the Blob storage documentation content for information on all other facets of account administration, including setting up network security, designing for high availability, and disaster recovery.
Review Feature Compatibility and Known Problems
When setting up your account to leverage Blob storage services, apply the approach below.
- To find out if a feature is fully supported in your account, read the page on Azure Storage accounts' Blob Storage feature support. In accounts with Data Lake Storage Gen2 enabled, several features are either not supported at all or only partially supported. As feature support continues to grow, be sure to frequently check this page for changes.
- Check the Known issues with the Azure Data Lake Storage Gen2 article to check if the functionality you want to use has any restrictions or needs any specific instructions.
- Look through feature articles for any advice that applies specifically to accounts with Data Lake Storage Gen2 enabled.
Recognize the Terminology Used in the Documentation
You'll notice some minor vocabulary variations as you switch between content sets. For instance, the term "blob" will be used instead of "file" in the featured featured featured content in the Blob storage description. Technically, the data you upload to your storage account turns into blobs there. Consequently, the phrase is accurate. However, if you're used to the term "file," the term "blob" could be confusing. A file system will also be referred to as a "container." Think of these phrases as interchangeable.
Think About Premium
Consider adopting a premium block blob storage account if your workloads demand low constant latency and/or a high volume of input-output operations per second (IOP). High-performance hardware is used in this sort of account to make data accessible. Solid-state drives (SSDs), which are designed for minimal latency, are used to store data. Compared to conventional hard drives, SSDs offer a greater throughput. Premium performance has greater storage costs but reduced transaction costs. Therefore, a premium performance block blob account may be cost-effective if your applications conduct a lot of transactions.
We strongly advise using Azure Data Lake Storage Gen2 together with a premium block blob storage account if your storage account will be used for analytics. The premium tier for Azure Data Lake Storage is the usage of premium block blob storage accounts in conjunction with a Data Lake Storage-enabled account.
Improve Data Ingestion
The source hardware, source network hardware, or network connectivity to your storage account may be a bottleneck while ingesting data from a source system.
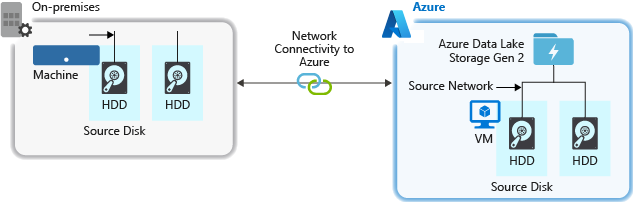
Source Hardware
Make sure to carefully choose the right hardware, whether you're using virtual machines (VMs) on Azure or on-premises equipment. Pick disc hardware with quicker spindles and think about employing Solid State Drives (SSD). Use the quickest Network Interface Controllers (NIC) you can find for network hardware. We advise using Azure D14 VMs because they have adequate networking and disc hardware power.
Connection to the Storage Account's Network
There may occasionally be a bottleneck in the network connectivity between your source data and your storage account. When your source data is on-premises, you might want to use an Azure ExpressRoute dedicated link. The performance is optimum when your source data, if it's in Azure, is in the same Azure region as your Data Lake Storage Gen2-enabled account.
Set Up Data Ingestion Mechanisms for the Most Parallel Processing Possible
Use all available throughput by running as many reads and writes in parallel as you can to get the optimum performance.

Sets of Structured Data
Consider organizing your data's structure beforehand. Performance and expense can be affected by file format, file size, and directory organization.
File Formats
Different formats can be used to absorb data. Data can be presented in compressed binary formats like tar. go or in human-readable formats like JSON, CSV, or XML. Data can also arrive in a variety of sizes. Large files (a few terabytes) can make up data, such as information from the export of a SQL table from your on-premises systems. The data from real-time events from an Internet of things (IoT) solution, for example, can also come in the form of numerous little files (a few kilobytes in size). By selecting an appropriate file format and file size, you may maximize efficiency and cut costs.
A selection of file formats supported by Hadoop is designed specifically for storing and analyzing structured data. Avro, Parquet, and the Optimized Row Columnar (ORC) format are a few popular formats. These are all binary file formats that can be read by machines. They are compressed to assist you in controlling file size. They are self-describing because each file contains an embedded schema. The method used to store data varies between different formats. The Parquet and ORC formats store data in a columnar fashion, whereas Avro stores data in a row-based format.
If your I/O patterns are more write-heavy or your query patterns favor fetching numerous rows of information in their entirety, you might want to use the Avro file format. The Avro format, for instance, works well with message buses that write a sequence of events or messages, like Event Hubs or Kafka.
When the I/O patterns are more read-intensive or the query patterns are concentrated on a specific subset of columns in the records, consider the Parquet and ORC file formats. Instead of reading the full record, read transactions might be streamlined to get only certain columns.
Open-source Apache Parquet is a file format that is designed for read-intensive analytics pipelines. You can skip over irrelevant data because of Parquet's columnar storage format. Because your queries may specifically target which data to send from storage to the analytics engine, they are significantly more efficient. Additionally, Parquet provides effective data encoding and compression techniques that can reduce the cost of data storage because similar data types (for a column) are stored together. There is native Parquet file format support in services like Azure Synapse Analytics, Azure Databricks, and Azure Data Factory.
File Size
Larger files result in improved performance and lower expenses.
Analytics engines like HDInsight typically include a per-file overhead that includes activities like listing, determining access, and carrying out different metadata operations. Data storage in the form of several little files might have a negative impact on performance. For improved performance, organize your data into larger files (256 MB to 100 GB in size). Files more than 100 GB in size may not be processed efficiently by some engines and programs.
Reducing transaction costs is another benefit of enlarging files. You will be charged for read and write activities in 4-megabyte increments, whether the file contains 4 megabytes or merely a few kilobytes. See Azure Data Lake Storage pricing for more on pricing.
The raw data, which consists of numerous little files, can occasionally be under the limited control of data pipelines. We advise that your system have a procedure to combine small files into bigger ones for use by downstream applications. If you're processing data in real-time, you can use a real-time streaming engine (like Spark Streaming or Azure Stream Analytics) in conjunction with a message broker (like Event Hubs or Apache Kafka) to save your data as larger files. As you combine small files into bigger ones, consider saving them in a read-optimized format, like Apache Parquet, for later processing.
Directory Structure
These are some typical layouts to consider when working with the Internet of Things (IoT), batch scenarios, or when optimizing for time-series data. Every workload has various requirements on how the data is consumed.
Arrangement of a Batch Work
In IoT workloads, a lot of data that comes from many goods, devices, businesses, and customers may be absorbed. The directory layout needs to be planned in time for organization, security, and effective data processing for downstream users. The following design could serve as a broad template to think about:
{Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
For illustration, the structure of landing telemetry for an aircraft engine in the UK might be as follows:
UK/Planes/BA1293/Engine1/2017/08/11/12/
You may more easily restrict regions and topics to users and groups in this example by adding the date to the end of the directory structure. It would be far more challenging to secure these areas and topics if the date structure came first. For instance, you would need to request separate authorization for several directories beneath every hour directory if you wanted to restrict access to UK data or only particular planes. Additionally, as time went on, this arrangement would rapidly grow the number of directories.
The Structure of a Batch Task
Adding data to an "in" directory is a frequent batch processing technique. After the data has been processed, place the fresh data in an "out" directory so that other processes can use it. This directory structure is occasionally used for tasks that only need to examine a single file and don't necessarily need to be executed in massively parallel across a big dataset. A useful directory structure has parent-level directories for things like area and subject matters, like the IoT structure shown above (for example, organization, product, or producer). To enable better organization, filtered searches, security, and automation in the processing, take date and time into consideration when designing the structure. The frequency with which the data is uploaded or downloaded determines the level of granularity for the data structure.
File processing can occasionally fail because of data corruption or unexpected formats. A directory structure may benefit from having a /bad folder in these situations so that the files can be moved there for additional analysis. The batch task may also oversee reporting or alerting users to these problematic files so that they can take manual action. Think about the following template arrangement:
{Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/{Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/{Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
For example, a marketing firm receives daily data extracts of customer updates from its clients in North America. It might look like the following snippet before and after being processed:
NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csvNA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
The output already goes into a separate folder for the Hive table or external database in the typical scenario of batch data processing being done directly into databases like Hive or traditional SQL databases; thus, there is no need for a /in or /out directory. For instance, each directory would receive daily extracts from consumers. After that, a daily Hive or Spark job would be started by a service like Azure Data Factory, Apache Oozie, or Apache Airflow to process and write the data into a Hive table.
Data Structure for Time Series
Partition pruning of time-series data for Hive workloads might enable some queries to read only a portion of the data, improving performance.
Pipelines for absorbing time-series data commonly organize their files into named folders. Here is an example of data that is often arranged by date:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Keep in mind that the Date and Time details can be found in the filename as well as the folders.
The following is a typical format for date and time:
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Once more, the decision you make about how to organize your folders and files should be optimized for higher file sizes and a manageable quantity of files in each folder.
Set Up Security
Start by going over the suggestions in the article Security considerations for Blob storage. You'll receive best practice advice on how to safeguard data behind a firewall, guard against malicious or unintentional deletion, and use Azure Active Directory (Azure AD) as the foundation for identity management.
Then, for advice unique to accounts that have Data Lake Storage Gen2 enabled, see the Access control model section of the Azure Data Lake Storage Gen2 page. This article explains how to apply security permissions to directories and files in your hierarchical file system using Azure role-based access control (Azure RBAC) roles and access control lists (ACLs).
Ingest, Carry Out, and Assess
Data can be ingested into a Data Lake Storage Gen2-capable account from a wide variety of sources and in a variety of methods.
To prototyping applications, you can ingest huge sets of data from HDInsight and Hadoop clusters as well as smaller collections of ad hoc data. You can take in streaming data produced by a variety of sources, including software, hardware, and sensors. You can utilize tools to record and process this kind of data in real-time, event by event, and then write the events into your account in batches. Web server logs, which include details like the history of page requests, can also be ingested. If you want to have the flexibility to integrate your data uploading component into your bigger big data application, think about using bespoke scripts or programs to submit log data.
Once the data is available in your account, you can run an analysis on that data, create visualizations, and even download the data to your local machine or to other repositories, such as an Azure SQL database or SQL Server instance.
Monitor Telemetry
Operationalizing your service requires careful attention to usage and performance monitoring. Examples include procedures that happen frequently, have a lot of latency, or throttle services.
Through the Azure Storage logs in Azure Monitor, you may access all of the telemetries for your storage account. This functionality allows you to archive logs to another storage account and links your storage account with Log Analytics and Event Hubs. Visit the Azure Storage monitoring data reference to view the whole collection of metrics, resource logs, and their corresponding structure.
Depending on how you intend to access them, you can store your logs anywhere you like. You can store your logs in a Log Analytics workspace, for instance, if you wish to have access to them in almost real-time and be able to connect events in the logs with other metrics from Azure Monitor. Then, use KQL and author queries to query your logs, which list the StorageBlobLogs table in your workspace.
You can set up your diagnostic settings to send logs to both a Log Analytics workspace and a storage account if you wish to store your logs for both near real-time query and long-term preservation.
You can set up your diagnostic settings to send logs to an event hub and ingest logs from the event hub to your preferred destination if you want to retrieve your logs through another query engine, such as Splunk.
Conclusion
Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics. You will also receive low-cost, tiered storage with high availability/disaster recovery capabilities because these capabilities are built on Blob storage.
Opinions expressed by DZone contributors are their own.
Comments