Integrate Amazon S3 with Mule
Amazon S3 connectors allow operations on the Objects and Buckets. Get an understanding of S3 connectors in Anypoint Platform with this blog.
Join the DZone community and get the full member experience.
Join For FreeAmazon Web Service’s S3 stands for “Simple Storage Service.” It is a type of cloud storage provided to the developers as a scalable solution over the Internet.
Amazon S3 uses the concept of Buckets and Objects to store the data. It allows an easy, user-friendly, fast and on-demand approach for storing & retrieving the data online.
MuleSoft provides an Amazon S3 connector that allows us to perform various operations on the Objects and Buckets.
In this blog, we are going through the understanding and working of the below S3 connectors:
- Create Bucket.
- Delete Bucket.
- Create Object.
- Get Object.
- Delete Object.
Prerequisite Steps:
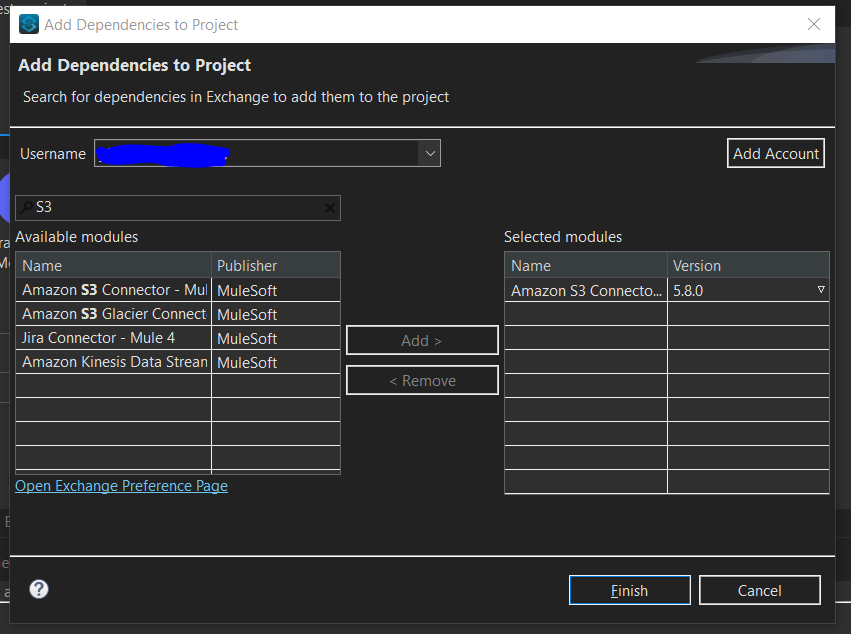
There are two ways to add the Amazon S3 connector to your project:
- Add AWS-S3 connector module from Exchange to the Studio palette.
![]()
- Or Go to the Anypoint Platform > Exchange > All assets > Provided by MuleSoft. Search and select the “Amazon S3 Connector” for Mule 4. On opening the connector, click on “Dependency Snippets.” Copy the opened Snippet under Maven.
Finally, paste it inside your pom file under <dependencies> tag.
- Make sure you have an account created with Amazon Web Services. You can refer to this link https://portal.aws.amazon.com/billing/signup to sign-up for a free account.
- Note down the Security Credentials named “Access Key ID” and “Secret Key” from your AWS account. To create a new set of credentials you can click on the “Create New Access Key” button under the “Security Credentials” option.
- Create a global connector configuration for “Amazon S3 Configuration” which will be common and used in the implementation of all the below-mentioned S3 connectors.
For the “Basic” Connection, we will need to provide the details for “Access Key” and “Secret Key” (refer to the previous point).
1. Create Bucket
A Bucket is used to store the Objects. Whenever an Object is added to the Bucket, a distinct property called “Version Id” is allocated to the Object internally.
We have created a simple flow using HTTP Listener (to make the POST call), loggers (to log the required information to the console), and most importantly “Create Bucket” connector from the Amazon S3 module.
Select the “Amazon_S3_Configuration” set up in global-config for the “Connector Configuration” field.
For the “Bucket name” field, we can enter the value directly or dynamically. In our case, we are getting the value dynamically using the POST call’s payload.
Set the name of the bucket in the payload while hitting the URL.
In our case, a bucket named “for-blog” is created successfully.
2. Delete Bucket
Now we will make use of the “Delete Bucket” connector from the S3 module to delete the Bucket created in the previous section of the blog.
Here also, we will set the value of “Bucket name” dynamically using the payload.
On triggering the URL with the name of the Bucket to be deleted, we see that the “for-blog” named bucket is deleted from the S3 storage.
3. Create Object
The AWS Object contains the data which we want to store in the Bucket. The object is labeled with the value of “Key” passed while creating the Object.
For the “Create Object” connector, we will need to provide the values of the below fields:
- Bucket name: We are using an already created Bucket named “poc-aws-api” directly.
- Key: Here we entered the name of the object to be created dynamically using the payload.
- Object content: We will be passing the below data in JSON format to be stored, as part of the payload.
{
“objectName”: “newobject”,
“description”: “description of the newobject comes here !”
}After the successful triggering of the URL, we can see the object with the name “newobject” is created under the “poc-aws-api” Bucket.
4. Get Object
In this scenario, we will use the “Get Object” S3 connector to fetch the data stored in the Object.
We are also using the “Write” file connector to download the fetched data in a file on a local location.
In the “Get object” connector’s configuration, we will mention the below details:
- Bucket name: The name of the Bucket where the Object is stored.
- Key: The name of the Object to be fetched is passed as Variable stored as “objectName”.
On execution of the flow, the details of the object are successfully fetched and downloaded locally as a JSON file.

5. Delete Object
In this section, we will use the “Delete object” S3 connector to delete the Object created in 3rd section of the blog.
In the “Delete object” connector’s configuration, we will mention the below details:
- Bucket name: The name of the Bucket where the Object is stored.
- Key: The name of the Object to be deleted is passed as the part of payload.
After triggering the URL, we can see the mentioned Object is deleted from the Bucket.
Best Practice: For purpose of simplification, we have mentioned the configuration details directly, but it is always recommended to externalize these details and encrypt the sensitive data.
Published at DZone with permission of Gitanshu Choudhary. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments