Configuring Amazon S3 Using Mulesoft
Mulesoft provides the Amazon S3 connector to help you easily connect to your S3 and get on with your integration. Follow the tutorial below!
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Amazon S3 or Amazon Simple Storage Service is a service offered by Amazon Web Services to store objects, download, and use the data kept in the S3, and help to build an application that requires internet storage.
Mulesoft provides the Amazon S3 connector to help you easily connect to your S3 and get on with your integration.
Tutorial
To get connected to the Amazon S3 using Mulesoft, we have two types of connections:
- Basic
- Role
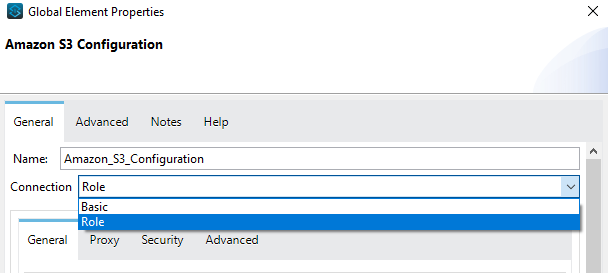
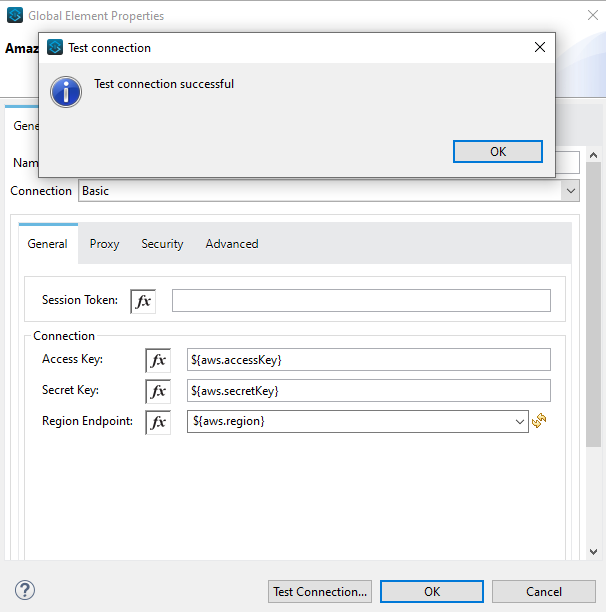
To get connected to the Amazon S3 using the Basic connection, you will need the following:
- Access Key
- Secret Key
- Region Endpoint
The Basic connection is used usually when you are the ROOT USER of the AWS Account.
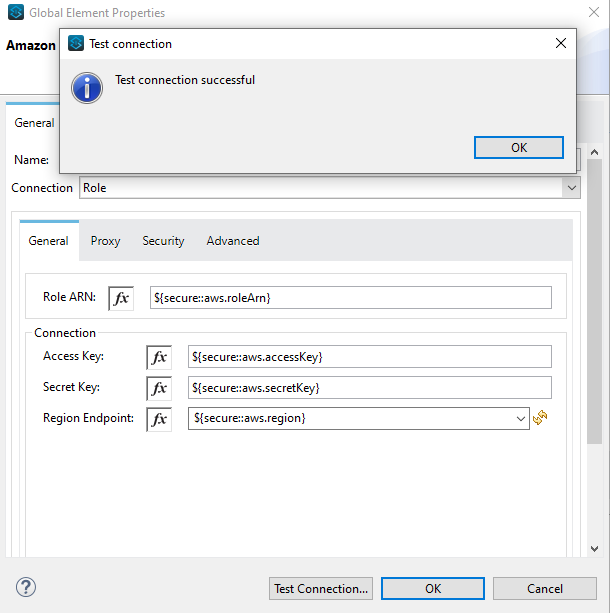
To get connected to the Amazon S3 using the Role Connection, you will need the following:
- Access Key
- Secret Key
- Region Endpoint
- Role ARN
Now that our configuration is done, let’s jump into the implementation part and see how we can take benefit from the Amazon S3 Connector.
In the implementation here, we will be focusing on:
- How to create a bucket.
- How to upload objects into the bucket.
- How to retrieve objects from the bucket.
Create an S3 Bucket
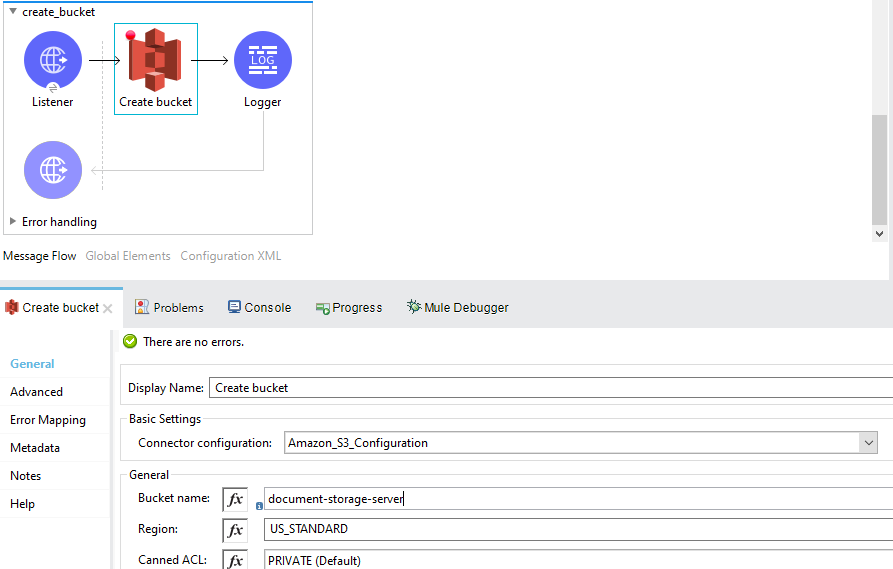
When you are done with the Amazon S3 configuration in the global elements tab, drag and drop the Create Bucket operation from the mule palette. If you haven’t already downloaded the module for the S3, go to the mule palette and search in the exchange for the S3 Connector.
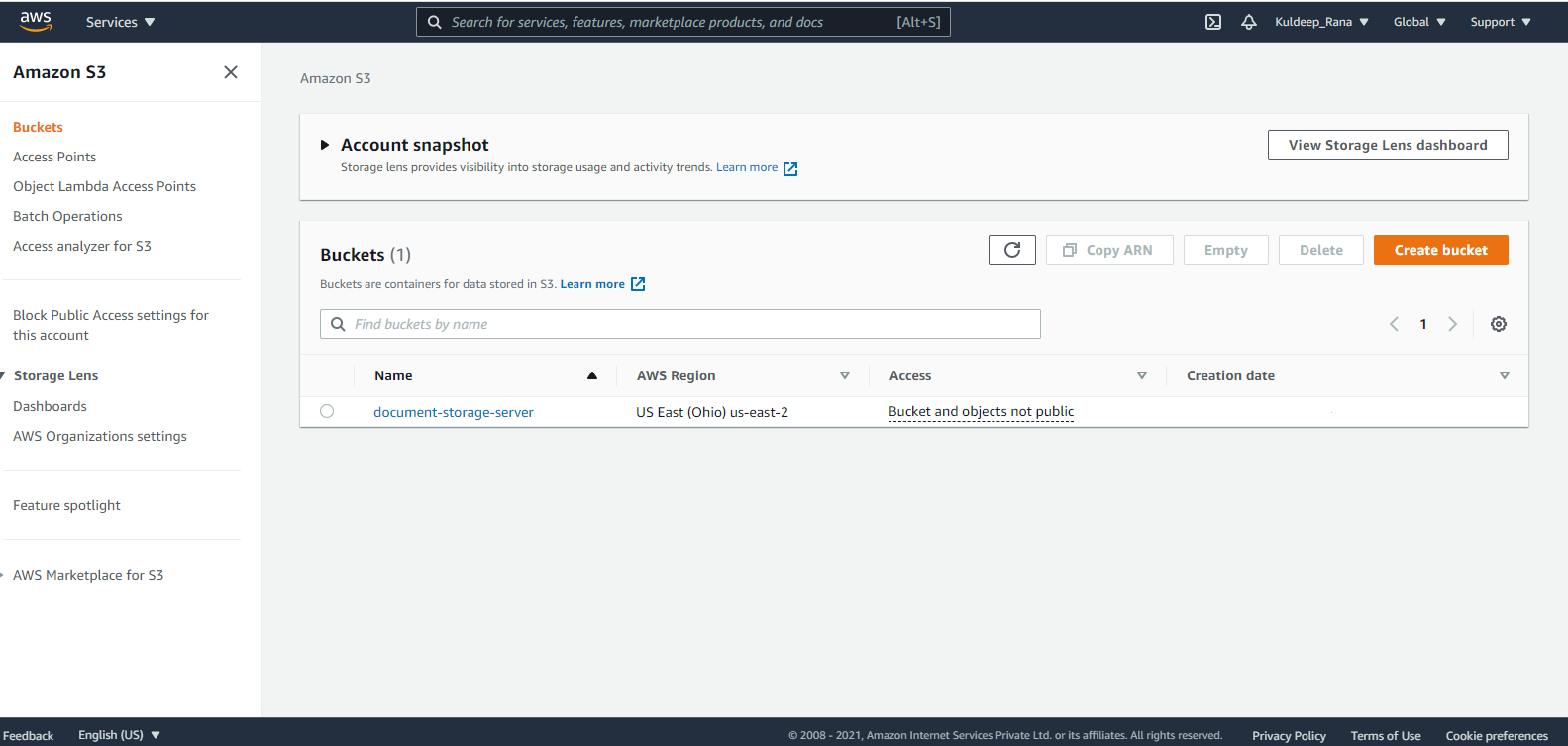
Once you have the create bucket operation, just add the Connector configuration from the drop-down and add the bucket name for your bucket to be displayed in the AWS S3.
Run the flow and if it executes successfully, you can see your bucket in your AWS Account.
Upload an Object into the S3 Bucket

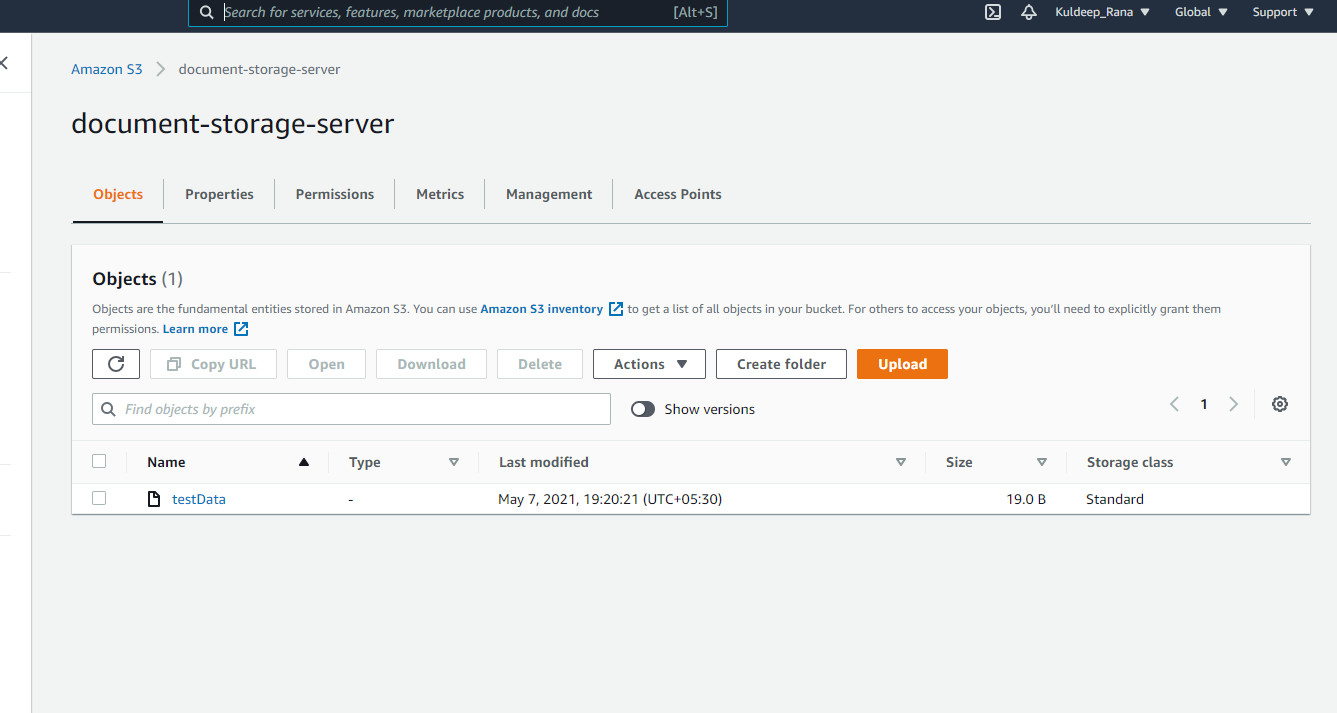
Drag the Create Object operation from the mule palette. Add the connector configuration.
Here, we have to add two things to the connector which are: The Bucket Name to which the file is to be uploaded (as an AWS can have multiple buckets) and the Key which is the name of the object to be uploaded (in my case it is the name of the file).
Setup your flow according to the implementation above and run it. If the flow gets executed successfully, you can see the object getting placed in the bucket.
Getting an Object From the S3 Bucket
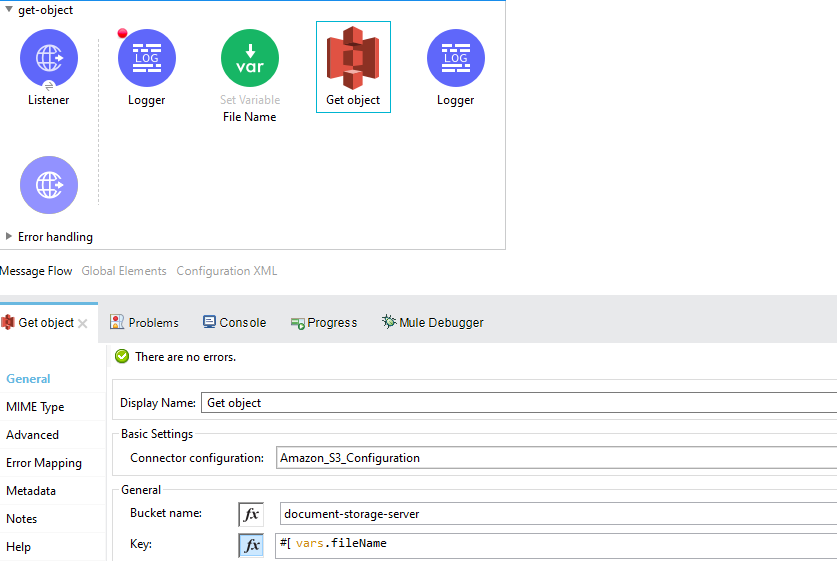
Drag the Get Object operation from the mule palette. Add the connector configuration.
Here, we have to add two things to the connector which are: The Bucket Name from which the file is to be fetched (as an AWS can have multiple buckets) and the Key which is the name of the object to be fetched (in my case it is the name of the file).
Setup your flow according to the implementation above and run it. If the flow gets executed successfully, you can see the content of the object in the logger or in the postman.

Similarly, there are many other operations in the Amazon S3 connector like deleting the bucket that we just created above, copying the object from one bucket to the other, deleting an object, or deleting multiple objects, listing all the buckets in a particular AWS Account, and many other more.
Use the operations according to your use case and build a full-fledged running integration.
Reference Links
Opinions expressed by DZone contributors are their own.
Comments