Increase Your Vector Database Read Throughput with In-Memory Replicas
Use in-memory replicas to enhance read throughput and the utilization of hardware resources.
By
 ·
·
Analysis
·
·
Analysis
Likes
(3)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
4.4K Views
Join the DZone community and get the full member experience.
Join For Free
With its official release, Milvus 2.1 comes with many new features such as in-memory replicas, support for string data type, embedded Milvus, tunable consistency, user authentication, and encryption in transit to provide convenience and a better user experience. Though the concept of the in-memory replica is nothing new to the world of distributed databases, it is a critical feature that can help you boost system performance, increase database read throughput, and enhance the utilization of hardware resources in an effortless way.
Therefore, this post sets out to explain what in-memory replica is and why it is important, and then introduces how to enable this new feature in Milvus, a vector database for AI.
Concepts Related to In-Memory Replica
Before getting to know what in-memory replica is and why it is important, we need to first understand a few relevant concepts, including replica group, shard replica, streaming replica, historical replica, and shard leader. The image below is an illustration of these concepts.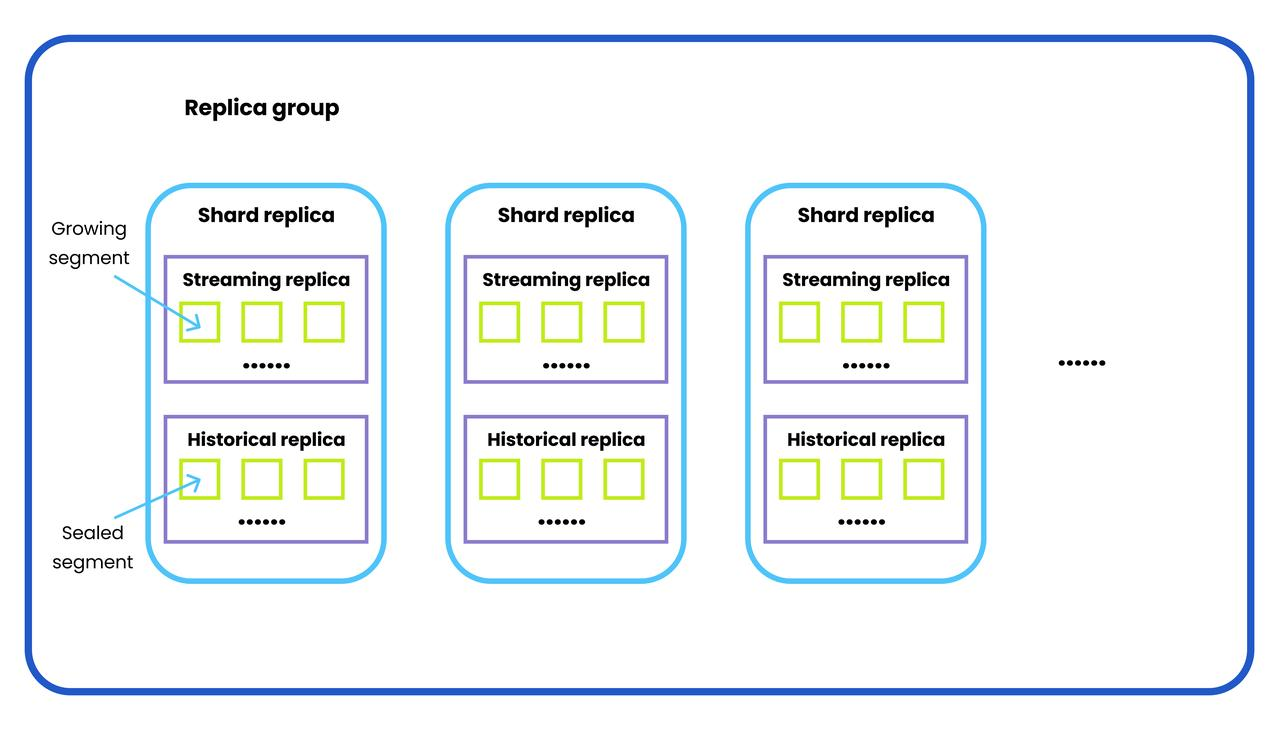
Replica concepts
Replica Group
A replica group consists of multiple query nodes that are responsible for handling historical data and replicas. More specifically, the query nodes in the Milvus vector database retrieve incremental log data and turn them into growing segments by subscribing to the log broker, loading historical data from the object storage, and running hybrid searches between vector and scalar data.Shard Replica
A shard replica consists of a streaming replica and a historical replica, both belonging to the same shard (i.e., Data manipulation language channel, abbreviated as DML channel in Milvus). Multiple shard replicas make up a replica group. And the exact number of shard replicas in a replica group is determined by the number of shards in a specified collection.Streaming Replica
A streaming replica contains all the growing segments from the same DML channel. A growing segment keeps receiving the newly inserted data till it is sealed. Technically speaking, a streaming replica should be served by only one query node in one replica.Historical Replica
A historical replica contains all the sealed segments from the same DML channel. A sealed segment no longer receives any new data and will be flushed to the object storage, leaving new data to be inserted into a freshly created growing segment. The sealed segments of one historical replica can be distributed on several query nodes within the same replica group.Shard Leader
A shard leader is the query node serving the streaming replica in a shard replica.
What Is In-Memory Replica?
Enabling in-memory replicas allows you to load data in a collection on multiple query nodes so that you can leverage extra CPU and memory resources. In other words, when you load the data in a collection and specify that you want to load it as two replicas, you will ultimately have two copies of the data on two query nodes. The feature of in-memory replicas is very useful if you have a relatively small dataset but want to increase read throughput and enhance the utilization of hardware resources.By default, the Milvus vector database holds one replica for each segment in memory for now. However, with in-memory replicas, you can have multiple replications of a segment on different query nodes. This means if one query node is conducting a search on a segment, an incoming new search request can be assigned to another idle query node as this query node has a replication of exactly the same segment. And the benefit is that you totally do not have to reload the data again. You do not have to do anything, and the idle query node automatically conducts the search or query as the data has already been replicated and received by this query node.
In addition, if we have multiple in-memory replicas, we can better cope with the situation in which a query node crashes. Without in-memory replicas, we have to wait for the segment to be reloaded in order to continue and search on another query node. However, with in-memory replication, the search request can be resent to a new query node immediately without having to reload the data again, just as illustrated in the image below.
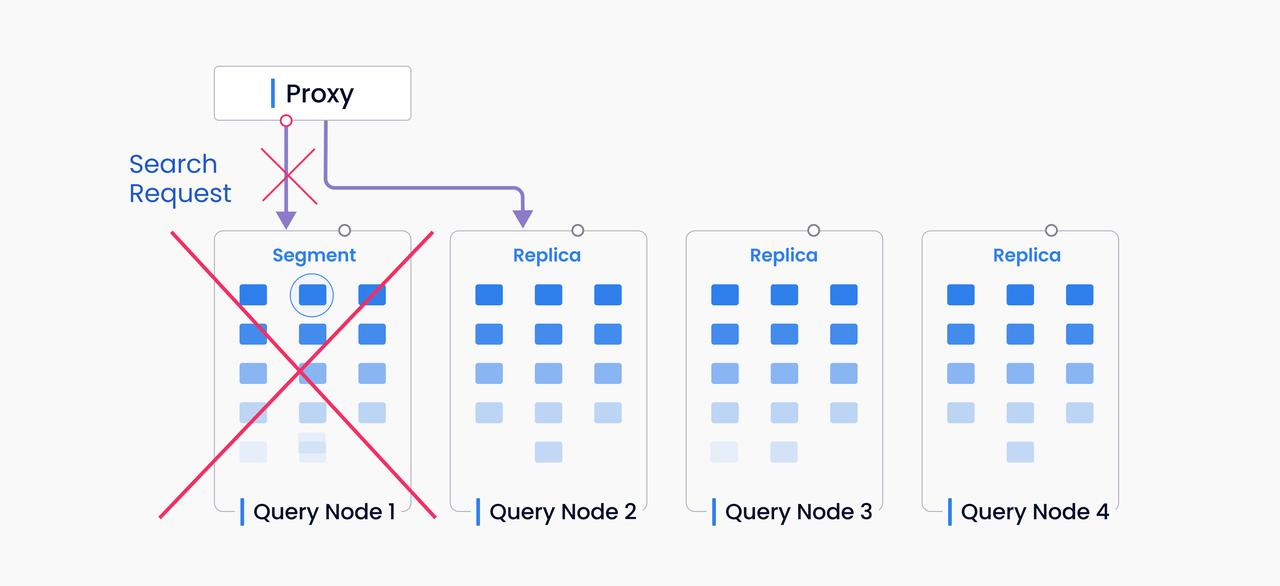
In-memory replicas
Why Are In-Memory Replicas Important?
One of the most significant benefits of enabling in-memory replicas is the increase in overall QPS (query per second) and throughput. You will be able to see a great leap in the system performance if you have enabled in-memory replicas when using your Milvus vector database. Furthermore, with in-memory replicas, multiple segment replicas can be maintained, and the system is more resilient in the face of a failover, just like the example illustrated above.Enable In-Memory Replicas in the Milvus Vector Database
Enabling the new feature of in-memory replicas is effortless in the Milvus vector database. All you need to do is simply specify the number of replicas you want when loading a collection (i.e., callingcollection.load()).
In the following tutorial, we will use the example of a collection that contains book information. We suppose you have already created a collection named "book" and inserted data into it. Then you can specify the number of replicas you would like to create when loading the collection data. The example code below loads the collection as two replicas.
from pymilvus import Collection
collection = Collection("book") # Get an existing collection.
collection.load(replica_number=2) # load collection as 2 replicas
You can flexibly modify the number of replicas in the example code above to best suit your application scenario. Then you can directly conduct a vector similarity search or query on multiple replicas without running any extra commands. However, it should be noted that the maximum number of replicas allowed is limited by the total amount of usable memory to run the query nodes. If the number of replicas you specify exceeds the limitations of usable memory, an error will be returned during the data load.
You can also check the information of the in-memory replicas you created by running
collection.get_replicas(). The information of replica groups and the corresponding query nodes and shards will be returned. The following is an example of the output.
Replica groups:
- Group: <group_id:435309823872729305>, <group_nodes:(21, 20)>, <shards:[Shard: <channel_name:milvus-zong-rootcoord-dml_27_435367661874184193v0>, <shard_leader:21>, <shard_nodes:[21]>, Shard: <channel_name:milvus-zong-rootcoord-dml_28_435367661874184193v1>, <shard_leader:20>, <shard_nodes:[20, 21]>]>
- Group: <group_id:435309823872729304>, <group_nodes:(25,)>, <shards:[Shard: <channel_name:milvus-zong-rootcoord-dml_28_435367661874184193v1>, <shard_leader:25>, <shard_nodes:[25]>, Shard: <channel_name:milvus-zong-rootcoord-dml_27_435367661874184193v0>, <shard_leader:25>, <shard_nodes:[25]>]>
Data manipulation language
Data structure
Database
Object storage
Queries per second
Data (computing)
Memory (storage engine)
Shard (database architecture)
Throughput (business)
Data Types
Published at DZone with permission of Charles Xie. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments