Importance of Schema Registry on Kafka Based Data Streaming Pipelines
Schema Registry acts as a service layer for metadata. It stores a versioned history of all the schema of registered data streams and schema change history.
Join the DZone community and get the full member experience.
Join For FreeApache Kafka delivers messages to both real-time and batch consumers without performance degradation and in addition to that gaining enormous momentum as a foremost component for data streaming pipelines too.
Credit card fraud detection, predictive maintenance, or real-time analytics, building streaming IoT platform, etc. are the example of real-time use cases. To handle massive amounts of data ingestion, Apache Kafka is the cornerstone of a robust IoT data platform. A schema defines the structure of the data format and schema evolution is a feature that allows updating the schema used to write new data while maintaining backward compatibility with the schema(s) of old data. The schema evolution is an important characteristic of data management. Once the initial schema is defined, streaming applications those integrated through data pipelines may need to evolve over time. There would be a critical situation for the downstream consumers of streaming data to handle data encoded with both the old and the new schema seamlessly when schema evolution takes place.
The major benefit of including a schema is that it clearly specifies the structure, the type, and the meaning of the data. Besides, data can be encoded more efficiently with a schema. The schema of data streams changes frequently over a period of time for long-running streaming jobs due to enhancement at source points. This happens to owe to changes in business requirements and eventually could break the existing data pipelines. And cause a service disruption because of schema changes on existing data. To support the corresponding changes at the source points, the cruel way is stopping them then updating and eventually restarting the data pipelines. With this traditional approach, we won’t be able to handle many important scenarios with these designed data pipelines. These are mainly tracking the change history of a data stream, backward compatibility on demand, approach to reading data from a data stream in a future-proof way, etc.
To understand better, let’s consider a simple example where a stream of changes or events is getting fired due to DML actions like an update, insert, alter or delete operations on rows of data on a specific table in a relational database like MySQL. Henceforth, we can consider the RDBMS (MySql) as a source point of streaming data. By leveraging Kafka Connect for a database (source connector), we can push the changes on the table as a stream into the multi-broker Kafka topic and subsequently, pull out those events as messages from the Kafka topic to destination point like Hadoop for offline analysis, secondary indexes such as Elasticsearch, Amazon S3, etc using Kafka connect sink connector.
In a nutshell, Kafka Connect (Source and Sink connector together) can be considered as a data-centric pipeline focused mainly on streaming data to and from Kafka topic and also an integral component of an ETL pipeline. Suppose if the table structure gets changes to accommodate new data or to add additional columns with the existing one due to business requirements, the data pipelines that connect to Kafka topic will have to update accordingly. But the issues arise if we need to roll back to the previous one or a further update occurs at the target table as there is no facility to maintain a change history of the data stream or backward compatibility on demand.
The schema registry plays an outstanding role to resolve the above difficulties. Schema Registry acts as a service layer for metadata. It stores a versioned history of all the schema of registered data streams and schema change history. Before constructing a Kafka based data pipeline, we need to register or assign schema info in the schema registry about the data available at the source point. Schema Registry is a distributed storage layer for schemas by making use of the underlying storage mechanism of Kafka. It assigns a unique ID to each registered schema. Instead of appending the whole schema info, only schema ID needs to be set with each set of records by the producer while sending messages to Kafka’s topic. By extracting the schema ID from the messages, consumers look up the whole schema info from Schema Registry and subsequently deserialized the messages before sending them to the sink or destination.
Assigning only schema ID with each record or message additionally saves time as well as speed up the whole serialization and deserialization process at producers and consumers. If some updates occur at the source point as mentioned in the above example, we need to just register new scheme info with a unique ID on the schema registry and update the schema ID for both producers as well as consumers. If the same consumer consumes records with previous schema ID, then updated fields on each record get removed during deserialization. With the Schema registry, there won’t be any hurdle in the entire data pipelines if changes get rollback at the source point. Simply by replacing the schema ID with the previous version of saved schema ID in producers as well as consumers, all the fields on each record get changes to the previous one upon deserialization in consumers. The following figure illustrating to understand better.
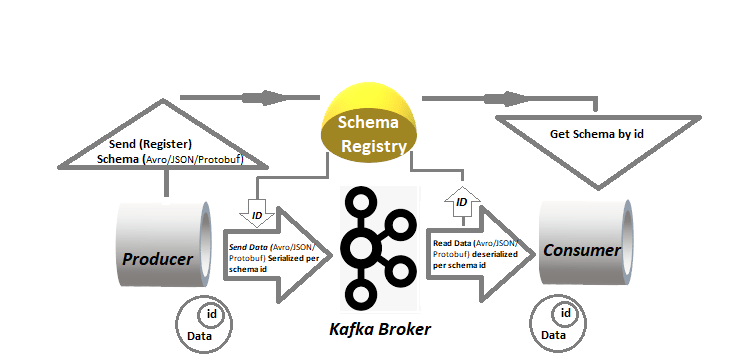
Kafka producers and consumers maintain an unsaid understanding to writes data with a schema as well as read/consume subsequently from topics even as producers and consumers evolve their schemas. Schema Registry works as a helping hand to ensure that this unsaid understanding or contract is met with compatibility checks. Schema registry provides centralized schema management and compatibility checks as schemas evolve. To ensure the producer-consumer contract is intact, Schema Registry pitches in when schema evolution requires compatibility check. Kafka works as a write-ahead or commits change log for the state of Schema Registry and the containing schemas.
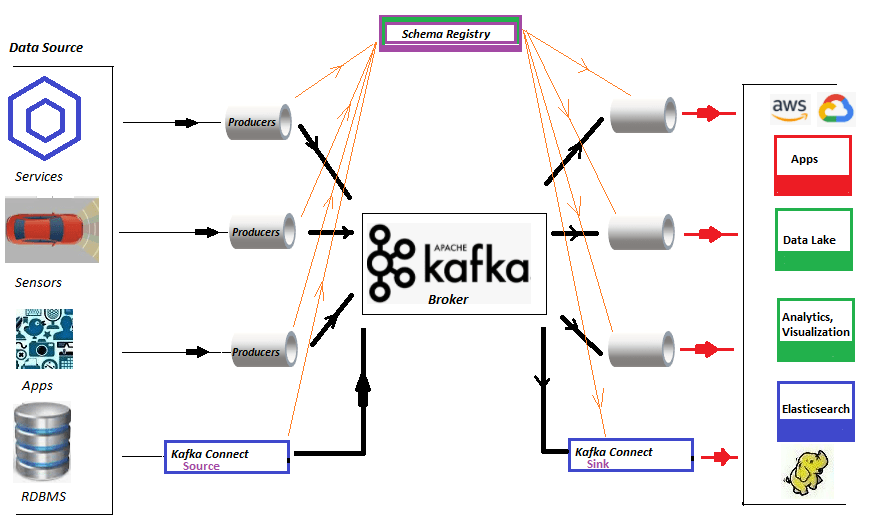
Confluent Schema Registry supports Avro, JSON Schema, and Protobuf schemas. Additionally, a built-in RESTful interface can be leveraged to store and retrieve schemas from the Schema Registry. Schema Registry can run independently outside of the multi-broker Kafka cluster. No separate installation is required of Schema Registry if we install the complete Confluent Platform on promises. The Confluent is the complete event streaming platform which is free and open source (see https://github.com/confluentinc/ for the source). But Enterprise version that includes the Control Center monitoring apps is not open source.
Hope you have enjoyed this read and foreseeing that the above would assist you with managing productively on Kafka based data streaming pipelines.
Reference: https://docs.confluent.io/current/schema-registry/index.html
Published at DZone with permission of Gautam Goswami, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments