Spark Structured Streaming Using Java
In this article, take a look at Spark structured streaming using Java.
Join the DZone community and get the full member experience.
Join For FreeSpark provides streaming library to process continuously flowing of data from real-time systems.
Concept
Spark Streaming is originally implemented with DStream API that runs on Spark RDD’s where the data is divided into chunks from the streaming source, processed and then send to destination.
From Spark 2, a new model has been developed in Spark which is structured streaming that is built on top of Spark SQL engine working on DataFrames and Datasets.
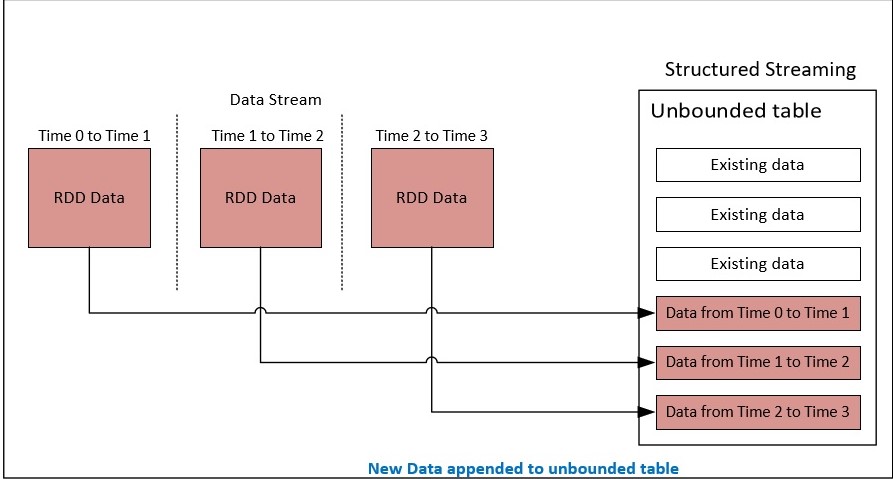
Structured Streaming makes use of continuous data stream as an unbounded table being updated continuously as events are processed from the stream.
Spark streaming application can be implemented using SQL queries performing various computations on this unbounded data.
Structured streaming handles several challenges like exactly-once stream processing, incremental updates, etc.
Structured Streaming works on polling of data based on trigger interval for fetching the data from the source. An output mode is required while writing result data set to sink. It supports append mode (only new data elements added to the result table will be written to sink), update mode (only the data elements that are updated in the result table will be written to sink), complete mode (all items in the result table will be written to sink).
In built Sources and Sinks
Structured Streaming supports following in built data sources.
File Source: Allows to read the files placed in certain directory. The formats supported are text, CSV, parquet, JSON
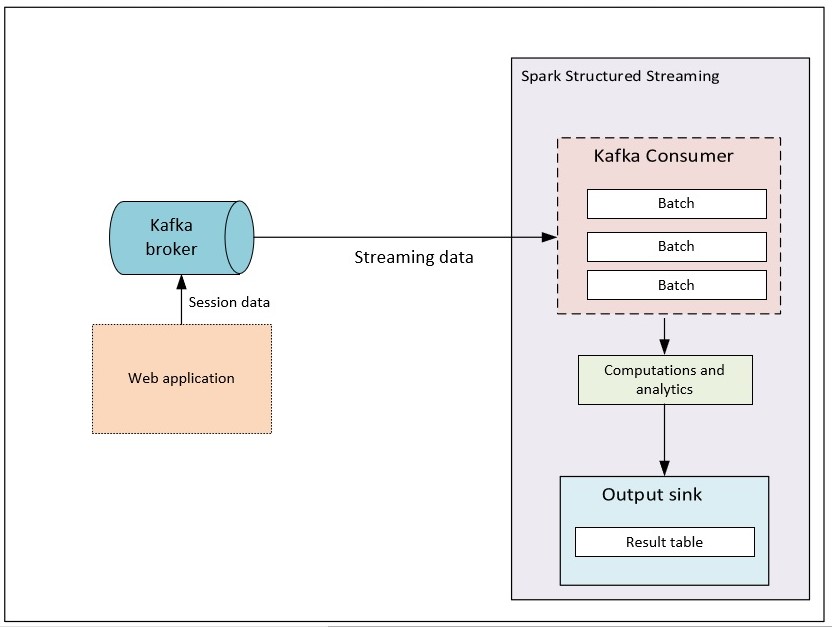
Kafka Source: Streaming library provides Kafka consumer to read data from Kafka broker. This is highly used in production.
Socket Source: Data can be read from socket using socket connections in UTF-8 format
The various built in sinks supported are as follows
File sink: Stores the output to a directory
Kafka sink: Stores the output to one or more topics in Kafka
Console sink: Prints the output to console, used for debugging purpose
Memory sink: Output is stored in memory as in-memory table, used for debugging purpose
Foreach sink: Runs adhoc computation on the records in output
Handling Fault Tolerance
Structured streaming provides fault tolerance by using check pointing to save the state of job and restart the job from the failed stage. This is also applicable to Spark Streaming using DStreams.
In addition, Structured Streaming provides following conditional based recovery mechanism for fault tolerance.
- The source must be replayable which is not yet committed
- The streaming sinks are designed to be idempotent for handling reprocessing
Demonstration
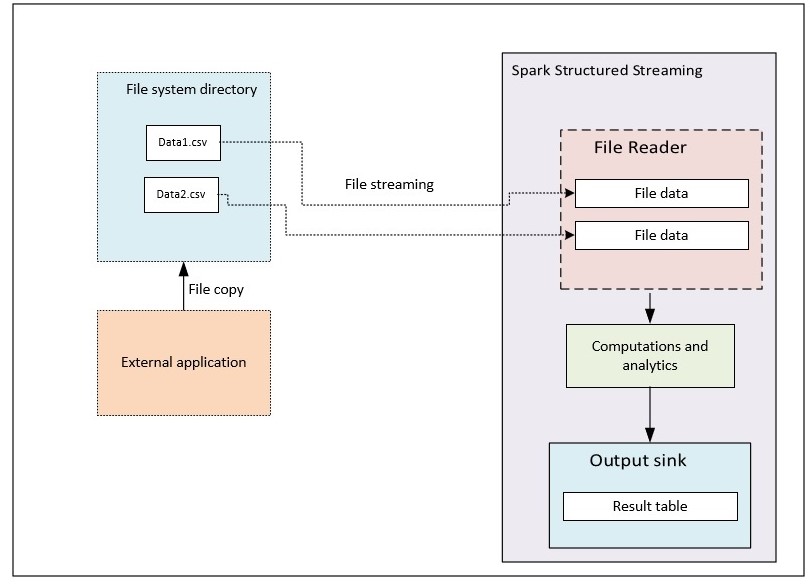
File Source
In this demo, we will be seeing Spark Streaming with some computations using File source and generating output to console sink.
This use case contains sample csv data set related to employee containing "empId, empName, department" fields. The data in csv will be placed in particular location of folder.
Spark Stream inbuilt file source listens for the directory update event notifications and passes the data to computation layer for required analytics. The output is streamed to console in this example.
The following example is Spark Structured Streaming program that computes the count of employees in a particular department based on file streaming data
package com.sparkstreaming;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.OutputMode;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
public class FileStream {
public static void main(String[] args) throws Exception {
//build the spark sesssion
SparkSession spark = SparkSession.builder().appName("spark streaming").config("spark.master", "local")
.config("spark.sql.warehouse.dir", "file:///app/").getOrCreate();
//set the log level only to log errors
spark.sparkContext().setLogLevel("ERROR");
//define schema type of file data source
StructType schema = new StructType().add("empId", DataTypes.StringType).add("empName", DataTypes.StringType)
.add("department", DataTypes.StringType);
//build the streaming data reader from the file source, specifying csv file format
Dataset<Row> rawData = spark.readStream().option("header", true).format("csv").schema(schema)
.csv("D:/streamingfiles/*.csv");
rawData.createOrReplaceTempView("empData");
//count of employees grouping by department
Dataset<Row> result = spark.sql("select count(*), department from empData group by department");
//write stream to output console with update mode as data is being aggregated
StreamingQuery query = result.writeStream().outputMode(OutputMode.Update()).format("console").start();
query.awaitTermination();
}
}
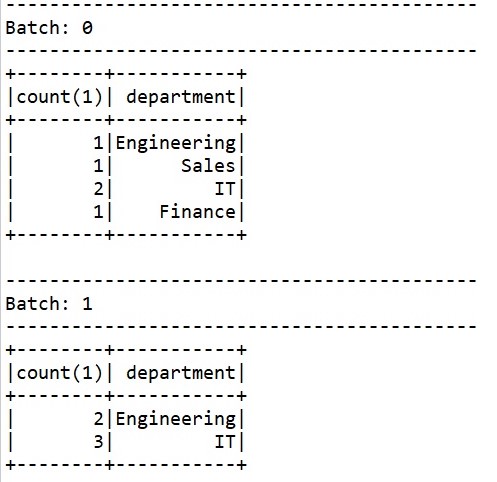
The output is streamed in batches where the first batch related to first file and second batch relates to second file etc
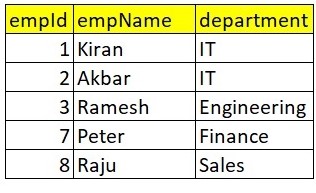
First csv file contains below data
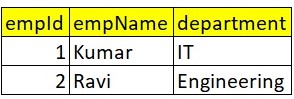
Second csv file contains below data
The output of streaming query is as shown below where the count is grouped by department name. The 2nd batch data is aggregated with first batch based on key values and the output is updated in 2nd batch.
Kafka Source
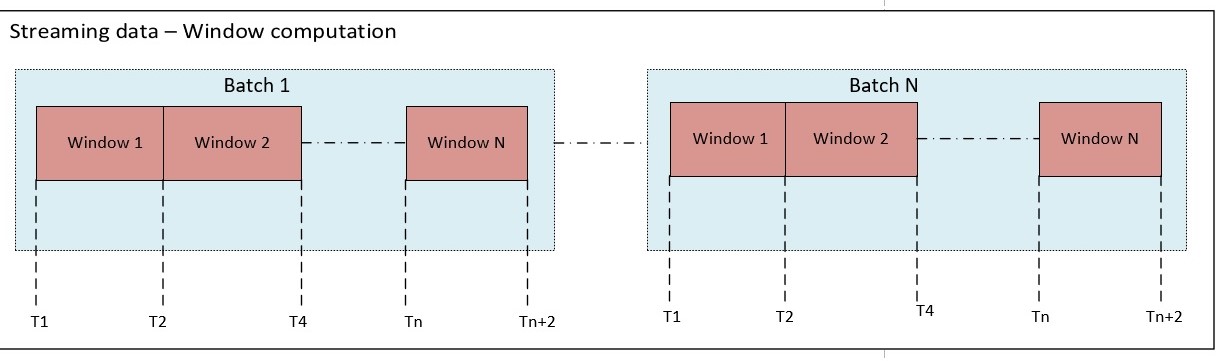
In this demo, we will be seeing implementation of Spark structured streaming reading from Kafka broker and computing aggregations on 2 minute window period for batch
In this use case, web application is continuously generating logged in session duration of the users to Kafka broker.
Using Spark streaming program, for every 2 minute window we compute the sum of session duration of the user logged into the website
The below is the Spark Streaming program in Java that computes the window based aggregations
x
package com.sparkstreaming;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.streaming.OutputMode;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.streaming.StreamingQueryException;
import org.apache.spark.sql.types.DataTypes;
public class DataStream {
public static void main(String[] args) throws StreamingQueryException
{
//set the hadoop home directory for kafka source
System.setProperty("hadoop.home.dir", "d:/winutils");
SparkSession session = SparkSession.builder()
.master("local[*]")
.appName("structuredViewingReport")
.getOrCreate();
session.sparkContext().setLogLevel("ERROR");
//define UDF to parse kafka message that can be passed to Spark SQL
session.udf().register("sessionDurationFn", new UDF1<String, Long>() {
public Long call(String messageValue) throws Exception {
String[] strArr = messageValue.split(",");
//returns the session duration value from Kafka message which is the first value in the coma delimited string value passed fron Kafka broker
return Long.parseLong(strArr[0]);
}
}, DataTypes.LongType);
session.udf().register("userNameFn", new UDF1<String, String>() {
public String call(String messageValue) throws Exception {
String[] strArr = messageValue.split(",");
//returns user name value from Kafka message which is the second value in the coma delimited string value passed fron Kafka broker
return strArr[1];
}
}, DataTypes.StringType);
//define kafka streaming reader
Dataset<Row> df = session.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "sessiondata")
.load();
// start dataframe operations
df.createOrReplaceTempView("session_data_init");
// key, value, timestamp are the core attributes in the kafka message. Value contains the coma delimited string with sessionduration,userid value format
Dataset<Row> preresults = session.sql("select sessionDurationFn(cast (value as string)) as session_duration, userNameFn(cast (value as string)) as userName,timestamp from session_data_init");
preresults.createOrReplaceTempView("session_data");
//compute sum of session duration grouping on 2 minute window and userName
Dataset<Row> results =
session.sql("select window,sum(session_duration) as session_duration,userName from session_data group by window(timestamp,'2 minutes'),userName");
//log the results to console
StreamingQuery query = results
.writeStream()
.format("console")
.outputMode(OutputMode.Update())
.option("truncate", false)
.option("numRows", 50)
.start();
query.awaitTermination();
}
}
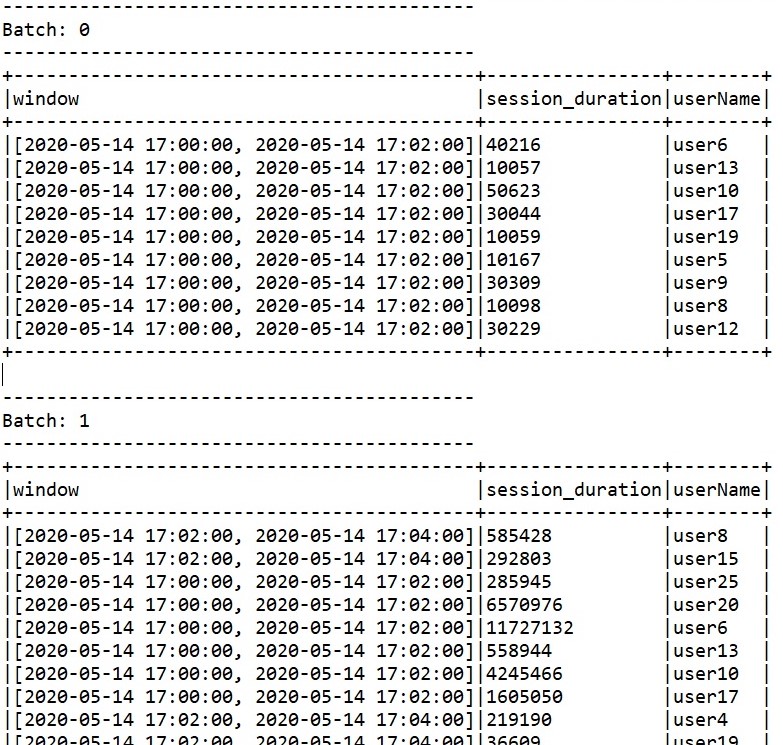
Kafka broker in this example sends the messages in key value pair where value is coma delimited string with session duration and userName value.
The output of the above program contains sequence of batches on window computation
These use cases are built as maven project. The below are the dependencies added in pom.xml
xxxxxxxxxx
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.2.0</version>
</dependency>
Performance Tuning Tips
Here are few performance tips to be considered in the Spark streaming applications
1. In the above Spark streaming output for Kafka source, there are some late arrival data. For example as shown below, first version of user19 data might be supposed to be arrived in batch1, but this has arrived in batch 2 for computation.

There are scenarios of late arrival data and computation of this data has to be performed on the earlier window data. In this scenario, the result of earlier window data is stored in memory and then aggregated with the late arrival data. Frameworks like Spark Streaming takes care of this process. But there might be possibilities of more memory consumption as the historical data is stored in the memory till the missed data is arrived which might lead to memory accumulation. In these scenarios, Spark streaming has feature of watermarking which discards the late arrival data when it crosses threshold value. In some cases, business results might have mismatch because of discarding these values. To avoid these type of issues, instead of applying watermarking feature, custom functionality has to be implemented to check the timestamp of data and then store it in HDFS or any cloud native object storage system to perform batch computations on the data. This implementation leads to complexity.
2. In the above Spark streaming output for kafka source, there is some performance lag where the data computation is slow. When we open the spark console and view the task and job info, we can predict the root cause for this issue.
The job is taking more than 1.5 minutes
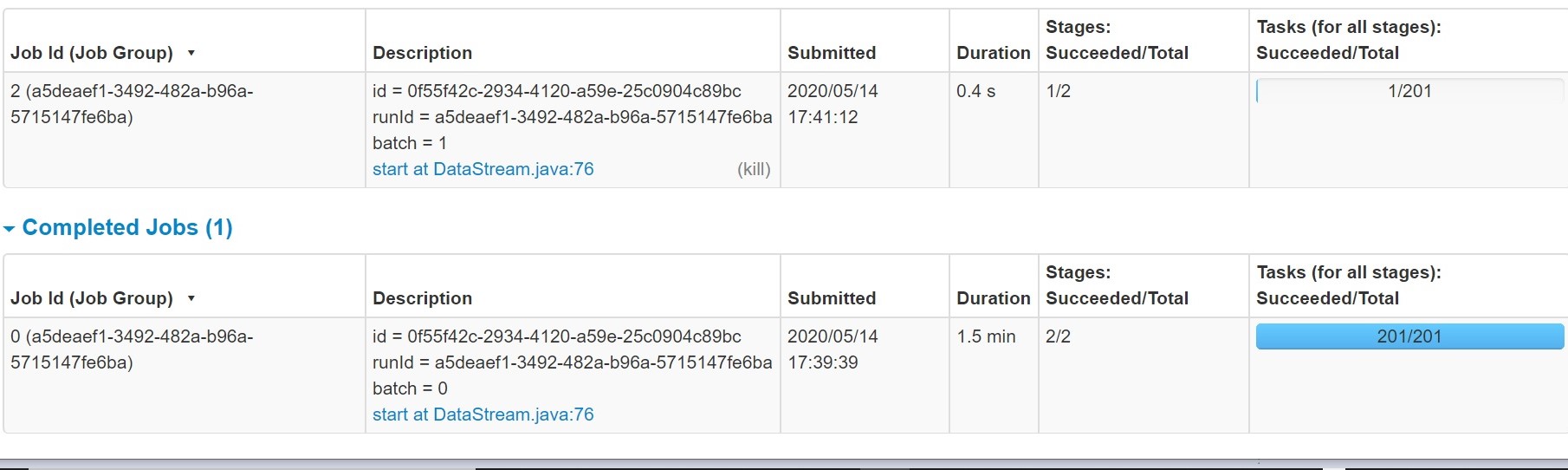
When we open the task info of the completed job, we can see there are many partitions created with 0 shuffling tasks handled. These dummy tasks on these partitions will take some time to start and stop and there by increase the total processing time which leads to latency
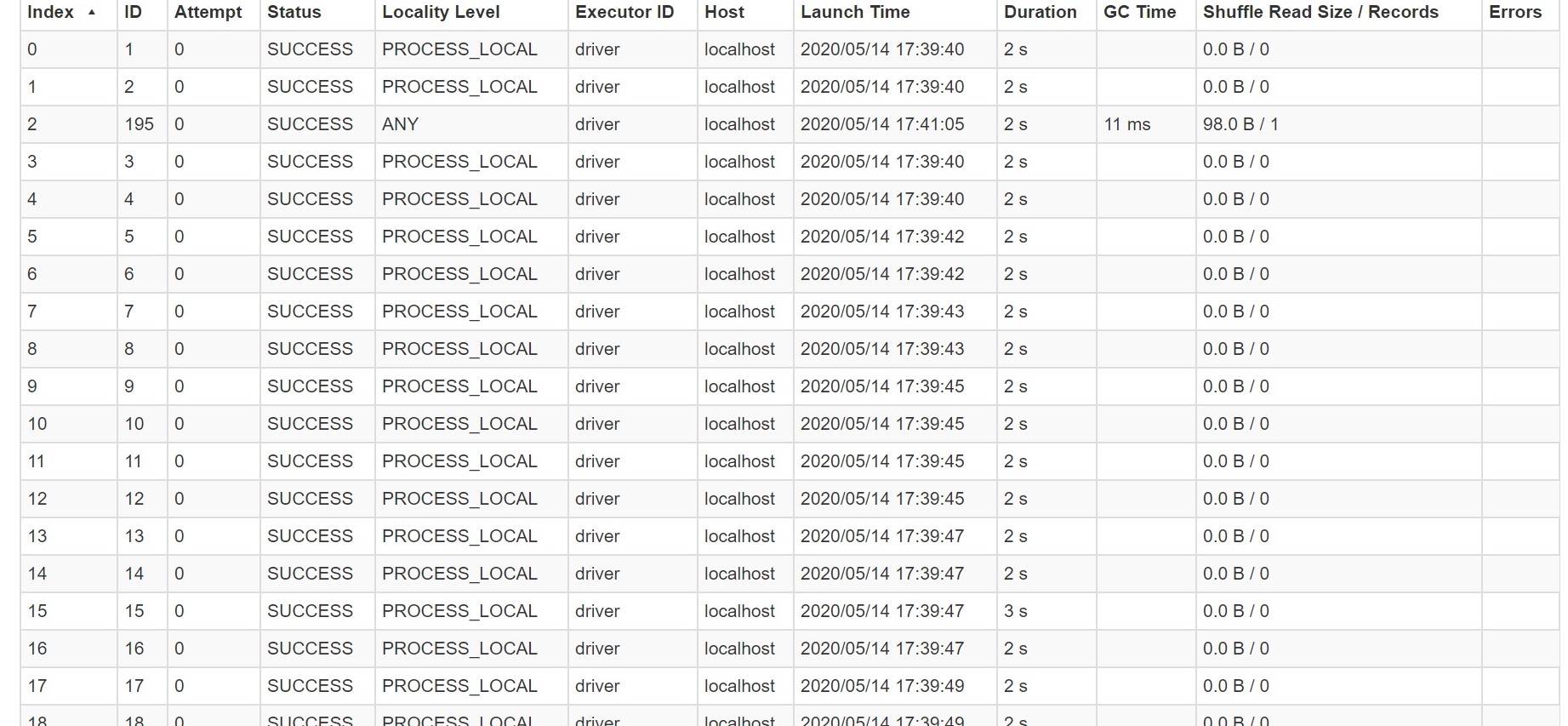
By default 200 partitions are getting created as shown above. Spark while processing uses shuffling when grouping operation is performed. During shuffling, partitions of data will be created and each partition will have the tasks assigned. Spark SQL has to take decision to use how many partitions to use. In these scenarios, more partitions will be created during shuffle read and many partitions will not have data to work on. This is because there are not many keys in the output as partitions size. These dummy tasks on these partitions will take some time to start and stop and there by increase the total processing time which leads to latency. The recommendation is to set the below property in the Spark code. This property determines the number of partitions that are used when shuffling data for joins or aggregations
xxxxxxxxxx
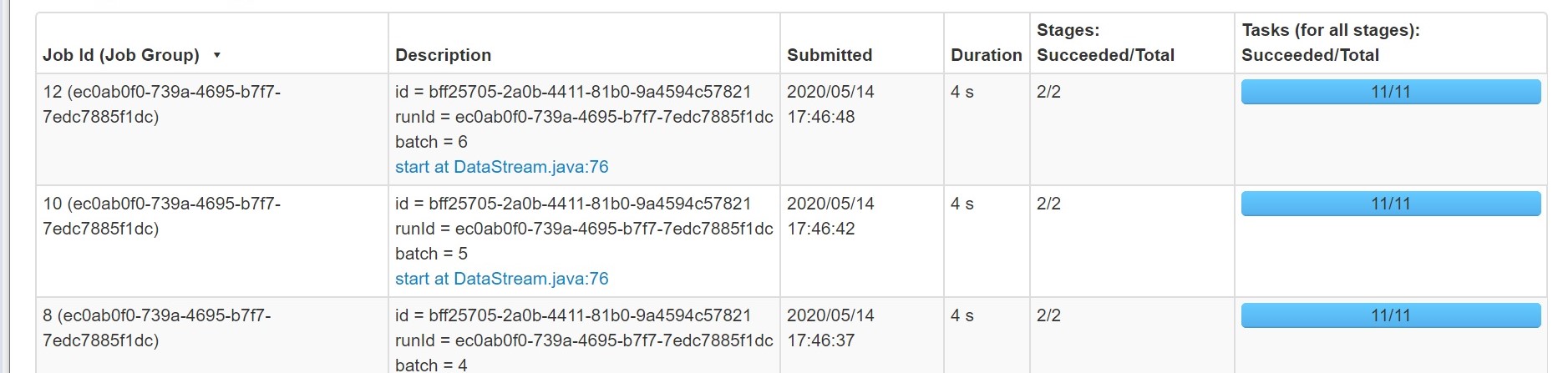
session.conf().set("spark.sql.shuffle.partitions", "10");
With this parameter, we can observe the job performance has been increased and also optimal number of partitions are created as shown below which is viewed from Spark console
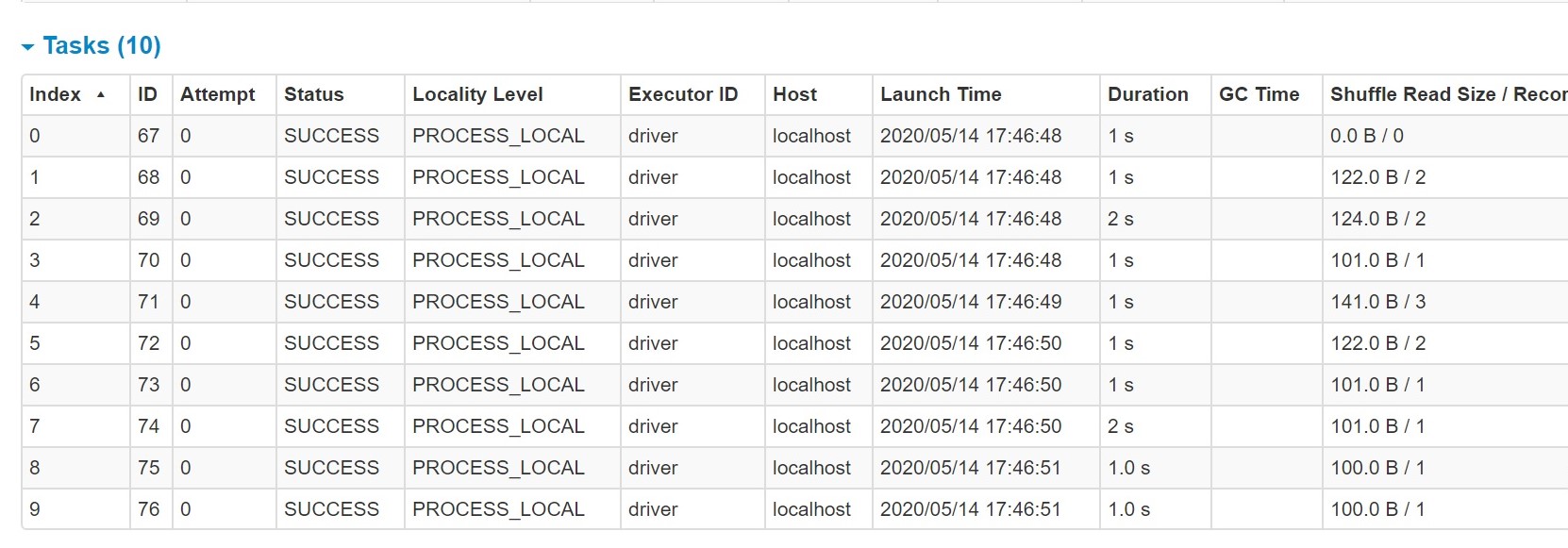
In this way, we can leverage Spark Structured Streaming in real time applications and get benefits of optimized Spark SQL based computing on the streaming data.
Opinions expressed by DZone contributors are their own.
Comments