IBM App Connect Operators: IntegrationServer Resource
Part 2: Exploring the IntegrationServer Resource of the IBM App Connect Operator
Join the DZone community and get the full member experience.
Join For FreeIn Part 1, we discussed what a Kubernetes Operator is, and the reasons why we chose to create one for IBM App Connect. In this part, we’ll delve into what the Operator does, and how it works.
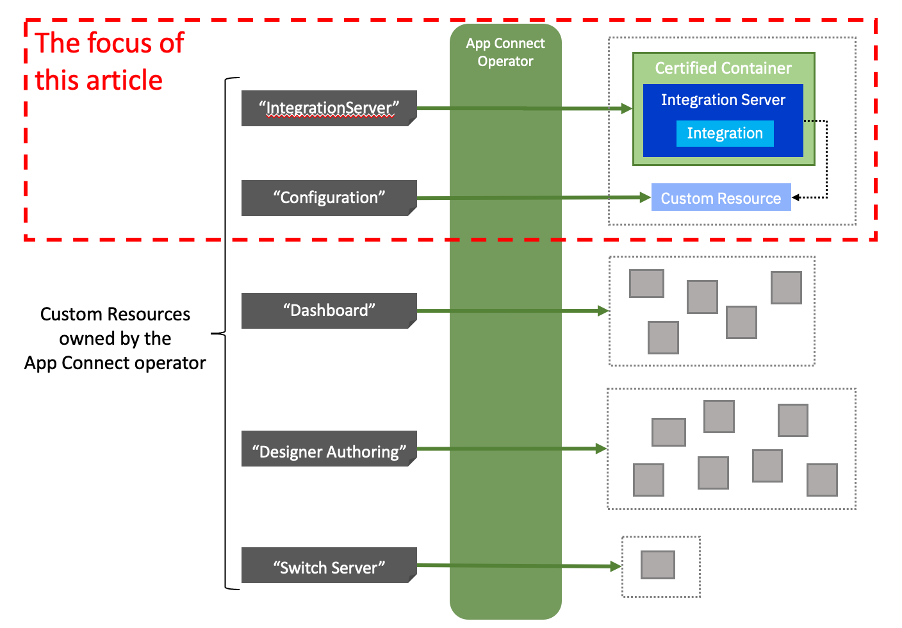
We noted that the IBM App Connect Operator can look after a number of different IBM App Connect-related custom resources. The main topic of this post is the IntegrationServer resource, but we will also discuss the Configuration resource since almost all deployments of IntegrationServer resources will require Configuration resources too.
The IntegrationServer and Configuration are used together to enable you to run integrations created using the IBM App Connect “Toolkit” or “Designer”.
You use the IntegrationServer resource to create an instance of an IBM App Connect integration server in a container.
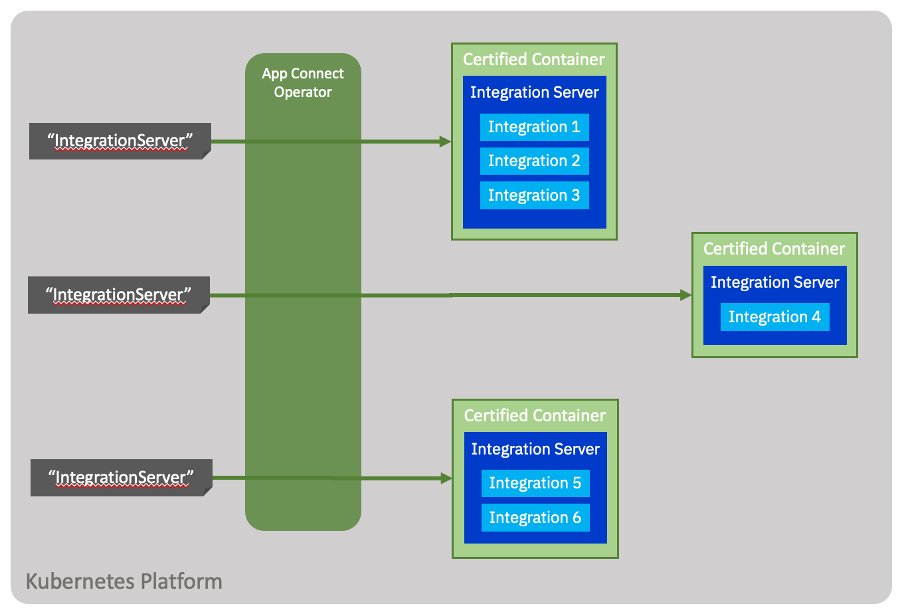
Many separate IntegrationServer resources may be created. The diagram shows that an IntegrationServer process has one or more Integrations deployed within it. We're using the term "Integration" in this context to describe an independently deployable collection of integration artifacts. It is effectively the smallest set of artifacts that could be usefully deployed within a single container.
Thinking specifically about the App Connect product, the Toolkit encourages users to group message flows and other associated artifacts together — either using an Application, a REST API (whose interface is described by an Open API document), or an Integration Service (whose interface is described by a WSDL document). These three product concepts are all equivalent to the general idea of an "Integration." The artifacts contained within each Application (or REST API or Integration Service) are dependent on one another and together they form an independently deployable unit.
We've deliberately shown in the above diagram that we expect containers will often house more than one integration. Technically, it would certainly be possible for each integration to be deployed in a separate container, but it is unlikely that this level of granularity is necessary, or even wise given most large enterprises have in the order of 100s of integrations.
We often find grouping decisions have already been made in integration architectures prior to the introduction of containers. Sets of Integration deployed under integration servers (or "execution groups" as they were previously known) are often an excellent starting point for how the integrations should be grouped across containers. You can then explore other factors to decide whether to split the groups further into smaller units, as discussed in a separate post.
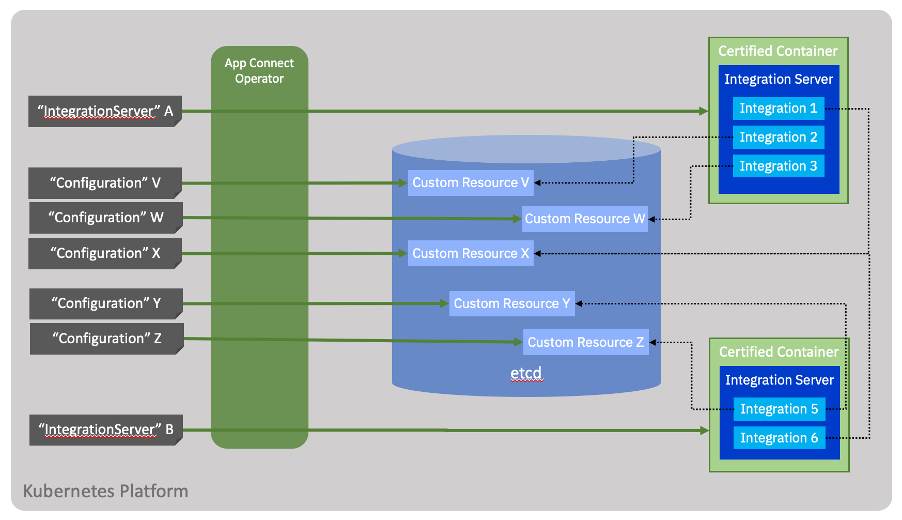
The Configuration resource is used to store important configuration information required by IntegrationServer resources. Each integration may have a number of different Configurations, each of a different type. For example, an odbc.ini file for connecting to a database, or an MQ policy file for connecting to IBM MQ.
You may notice that it is possible for Configurations to be shared between integrations (see Configuration X above), although this raises interesting questions around whether this creates couplings between those integrations. We can imagine that the credentials to connect to a particular application might be re-used by several integrations. This would make it easy to change the credentials for all integrations at the same time, but equally, the change would be introduced as a “big bang” across multiple landscapes.
However, since the Configurations are attached at deployment time, it would of course be possible to introduce a change via a new Configuration and link it only to a specific integration initially before rolling it out across the landscape. This is typical of the subtle architectural decisions that need to be made when embracing a more fine-grained deployment model.
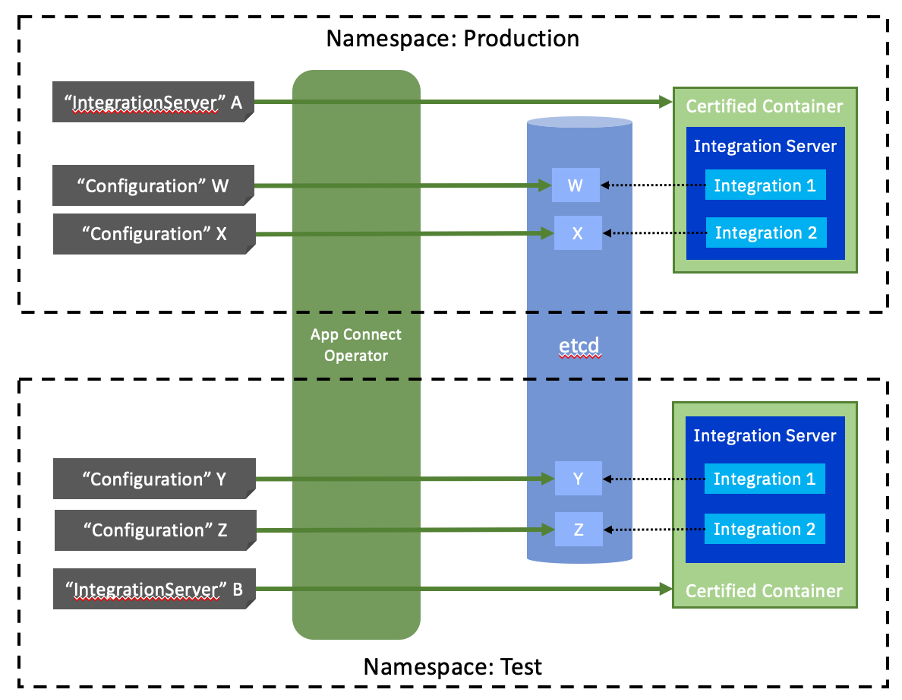
Furthermore, there may be several instances of each Configuration for the integration, containing details required for each environment (development, test, production, etc.).
Let’s explore those two custom resources in more detail.
What Does the IntegrationServer Custom Resource Look Like?
When you install the IBM App Connect Operator, it introduces six new Custom Resource Definitions (CRDs) to the Kubernetes API:
- IntegrationServer
- Configuration
- Dashboard
- DesignerAuthoring
- SwitchServer
- Trace
As noted, we will be focusing on the IntegrationServer, and Configuration resources.
Once the CRDs are present, instances of the resource types (known as “objects” in the Kubernetes documentation) can be created in just the same way as any other Kubernetes resource using the kubectl command (or “oc” command in OpenShift).
Let’s first have a look at an example of an IntegrationServer custom resource. This would be created using the following command line.
kubectl apply -f my-integration.yaml
Where the my-integration.yaml file contains a definition of an IntegrationSever as in the following example.
apiVersion: appconnect.ibm.com/v1beta1
kind: IntegrationServer
metadata:
name: http-echo-service
namespace: ace-demo
labels: {}
spec:
adminServerSecure: false
barURL: >-
https://github.com/amarIBM/hello-world/raw/master/HttpEchoApp.bar
configurations:
- github-barauth
createDashboardUsers: true
designerFlowsOperationMode: disabled
enableMetrics: true
license:
accept: true
license: L-KSBM-C37J2R
use: AppConnectEnterpriseProduction
pod:
containers:
runtime:
resources:
limits:
cpu: 300m
memory: 350Mi
requests:
cpu: 300m
memory: 300Mi
replicas: 1
router:
timeout: 120s
service:
endpointType: http
version: '12.0'The above is taken from an example of a simple deployment of an integration server using the IBM App Connect Operator. Feel free to take a look at that post if you’d like to understand the detail of the file in more depth. For a complete specification of the possible entries in the above IntegrationServer YAML file, see the product documentation here.
Essentially, it provides the integration’s name, the BAR file that has the integration code, the version of the IBM App Connect runtime to run it on, some CPU/memory requirements, and a replication policy. You don’t need a detailed knowledge of all the underlying Kubernetes objects required. Clearly, this single definition file is significantly simpler to prepare than the suite of Kubernetes native objects that will ultimately need to be created. As we will see later, the Controller will take care of all that.
The IntegrationServer resource can also be created and applied using a web dashboard which is an optional part of the IBM App Connect Operator. A simple example using the dashboard is also documented in the same series.
The above definition file deploys a trivially simple integration that simply exposes an HTTP endpoint that echoes back anything it receives. You will notice that it has a single entry in its “configurations” section called github-barauth. This informs the controller that there is a related Configuration resource, in this case containing the credentials for the GitHub repository from which the BAR file can be downloaded on start-up.
There are two other worked examples of IntegrationServer specifications in the same series that might be worth taking a look at.
The IntegrationServer configurations for these are largely the same but for additional lines in the “configurations” section, for an MQ policy in the first, and for multiple ODBC properties and credentials in the second.
With that in mind, let’s take a closer look at the Configuration custom resource.
What Does the Configuration Custom Resource Look Like?
Inevitably, integrations need a lot of different pieces of information about how to connect to the things to which they are integrating. This information is very deliberately separable from the core definition of the integration as it will almost certainly change as we promote integrations from one environment to another.
This connection information comes in many different forms. It could be database connection strings, MQ queue manager names and locations, Kafka brokers lists, keystore, and trust store locations, many different types and formats of credentials, and more. IBM App Connect has learned to connect to so many different back-end systems over the years that the list is almost endless.
Each of these has different requirements around how they should be securely stored in Kubernetes, and how they should be made available to the integration. In an effort to give users of the product a single mechanism for providing all these very different things, the IBM App Connect Operator has a custom resource known as a “Configuration.”
A Configuration can contain any one of the various types of connection information. The YAML file to create a Configuration looks like the following:
apiVersion: appconnect.ibm.com/v1beta1
kind: Configuration
metadata:
name: <Your configuration name>
namespace: <Your namespace>
spec:
type: <The name of the Configuration type>
description: <Your description>
data: <Your Configuration data in base64>Which is then created just like any other custom resource:
kubectl apply -f yourConfiguration.yaml
These can also be created using the IBM App Connect dashboard.
So, the Configuration enables you to use a single Kubernetes construct to create and update many different types of configuration information. There were 18 types at the time of writing, some of which hold multiple sub-types within them. The Accounts type, for example, enables the configuration of 30+ different SaaS application credentials.
Controllers: How the Operator Pattern Actually Works
An Operator isn’t really one thing, it’s a group of different pieces that come together to create the operator pattern.
In the simplest possible form of that pattern, there are two key components: Custom Resources discussed already, which you use to store data on what you want the Operator to do, and Controllers, which are software components that perform the actual actions. Often when we speak about the actions that the Operator performs, we are really talking about the Controller. Somewhat oversimplifying things, you could almost say that the Controller is the Operator, and Custom Resources are just how we provide it with the data it needs to do its job.
We have looked at the two Custom Resources we’re focused on for this post (IntegrationServer and Configuration), let’s now take a look at what the Controller does.
When you do a “kubectl apply” command to create a resource in Kubernetes, it really does nothing more than store the resource data in an object in etcd (with some data validation along the way). This is true whether it’s a Kubernetes native resource, a custom one, such App Connect’s IntegrationServer, or Configuration resources. The underlying engine of the Operator pattern is a piece of software called a Controller. The Controller component watches for the creation or update of any instances of the resources it owns and acts upon it.
There are in fact, Controllers behind nearly all Kubernetes resources, we’re just not typically aware of it since we work only with the custom resources they look after. A Controller’s job is to treat its resources data as a definition of the “desired state” and attempt to make whatever changes are necessary to move to that state. This is a critically important point to understand about the way Kubernetes works. A change to a resource (or custom resource) is only a request for change, it doesn’t mean that change has been enacted yet. The underlying controllers implement “eventual consistency,” working out the most appropriate sequence of actions to get to the desired state, and managing their completion.
Let’s take the example of the Controller for IBM App Connect and what it does when it is informed by Kubernetes of new IntegrationServer resources:
- Product version management: Work out the correct version of the IBM App Connect container image to use.
- Creation of Kubernetes resources: Request creation of the required Kubernetes resources such as:
- Pod: In Kubernetes, containers are always deployed in Pods, and it is here that replication, CPU, memory, etc. are defined. Sensible defaults are added where they are not specified in the IntegrationServer resource.
- Namespace: If the namespace specified in the IntegrationServer does not already exist, it is created.
- Ingress: On OpenShift, if the integration is invoked via HTTP, then a “Route” (Kubernetes term for an Ingress) is created, to make the HTTP endpoint available outside the Kubernetes cluster.
- Service Account, Role, Role Binding: Creates service accounts, with associated role bindings, so the pod can only access the resources it actually needs. Without this it could access everything in the namespace. For example, it only allows access to the secrets that are defined in the IntegrationServer resource.
- Code deployment: Pass a list of the BAR files specified in the IntegrationServer resource to the Certified Container.
- Environment-specific configuration: Pass a list of the Configurations resources specified in the IntegrationServer resource to the Certified Container. Any environment variables specified in the IntegrationServer resource will also be created within the container.
- Metrics: Set up the OpenShift resources to allow Pod to submit metrics into the embedded Prometheus (OpenShift only).
- Readiness: Provide status feedback during the deployment process to the standard logs, and if in OpenShift, also to the status resource shown in the OpenShift web console.
- SSL Configuration: Set up SSL for your integrations using any certificates you have provided, such that it does not have to be done on an individual flow basis. Also set up self-generated certificates for administrative communication.
- Licensing: Ensure all pods created are annotated with correct license properties for the license server to be able to report on.
- Change management: Continually watch the IntegrationServer resource for updates, and then work to apply any required changes. For example, changes to the resources (CPU/memory) or runtime version, or indeed the BAR file URL would automatically result in a coordinated rolling update of the targeted integration server’s pods.
At the time of writing, both the list of BAR files and the list of Configurations are passed to the container by injecting them into an environment variable on start-up. However, this mechanism is internal to the workings of the operator and may change over time.
Operational administration is one of the key differences between what can be achieved with an Operator compared to the common alternative approach of using Helm Charts. Operators continue to monitor the deployed components and compare them to the custom resource object they were created from, taking actions to ensure they stay in alignment, and indeed remain healthy. In contrast, Helm Charts primarily focus on the creation aspect. Helm Charts can optionally be used as part of the implementation of an Operator, but the operator will typically then also introduce code to perform its more sophisticated features.
The IBM App Connect Operator’s Controller also of course watches for the creation of Configuration objects, too. When new Configurations are created it inspects the resource’s data and depending on the value in its spec.type field it may remove the data from the custom resource and place it in a linked Kubernetes Secret. For example, for the odbc.ini type, there is no sensitive data, so this data is left in the custom resource, but for the setdbparms.txt type, the username/password credentials will be moved to a Secret, leaving behind only a link to the Secret in the custom resource data.
As noted in Part 1, the App Connect controller also watches a number of other custom resources: Trace, Dashboard, DesignerAuthoring, SwitchServer. These are beyond the scope of this article, but the Trace resource is worth a brief mention. This provides the mechanism to capture Trace information from an IntegrationServer to assist with problem diagnosis.
The IBM App Connect Certified Container
We have discussed the key elements of the operator pattern, the custom resources, and the controller. However, most operators are also highly dependent on the behavior of the container images that they deploy.
IBM provides a Certified Container image for IBM App Connect. This is specifically designed for use with the IBM App Connect operator and should not be used independently.
It’s worth noting at this point that you can use IBM App Connect in containers without using the operator, and samples of how to do this are well-documented. However, the aim for the operator pattern is to provide a premium experience, such that developers only need to use the non-operator path for specific custom use cases.
The Certified Container performs the following on start-up of the container, and prior specifically to complement the Operator.
- Prior to start-up of the integration server
- If a list of BAR file URLs has been passed in by the controller, it downloads the BAR files onto the file system in the appropriate directory for them to be parsed on start-up.
- If a list of Configurations has been passed in by the controller, it retrieves the data, following any links to related data stored in Kubernetes Secrets, un-parses the data as required, and in most cases simply places them in their relevant location on the ACE file system within the container.
- Starts up the integration server within the container, loading any BAR files supplied
- Performs any actions that require a running integration server such as connection to the Prometheus stack for monitoring and similar for tracing.
- Flags the container as being “ready” for incoming work.
The slightly more advanced article on an integration connecting to a database provides a good example of how the Certified Container processes a number of different configuration types.
Clearly, the collaboration between the Controller and the Certified Container is critical in order to gain the full benefits of the Operator Pattern, and it is easy to see how many powerful features can be introduced via this mechanism in the future.
Baking Bar Files Into the Container
As noted, the Certified Container has a mechanism to download BAR files on start-up, and this is a very convenient mechanism for getting started with containers quickly. However, there is an alternative approach whereby we could create a new container image with an integration included within it. This is sometimes referred to as the “baked” approach, since the integration file is baked into the image.
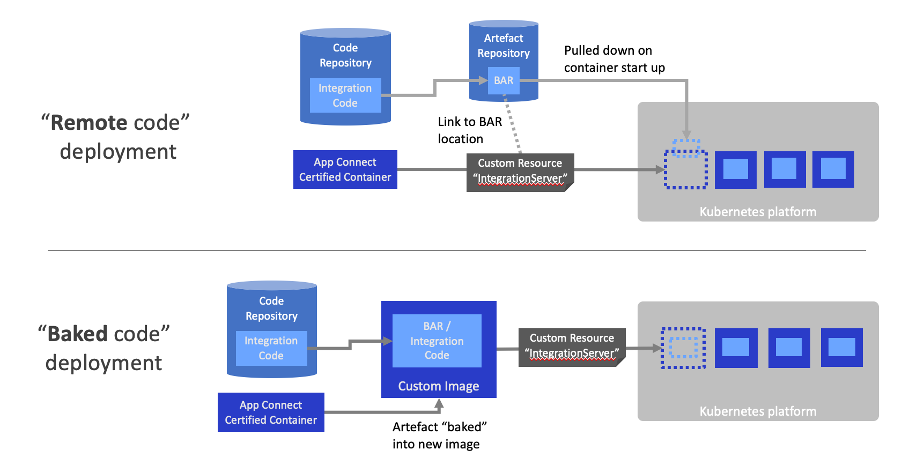
There are advantages to this approach in terms of deployment consistency. You have greater certainty that what you deploy is the same when you promote it through the environments. Also, you have no dependencies beyond the image repository. For example, you don’t need to worry about each environment being able to access the repository where your BAR file is located.
If we want to use the Operator with our baked image, we must use the Certified Container as a base. You then have two options.
Either
Add your BAR file to that initial-config directory and build your new image. The certified container will parse the BAR file on start-up, moving the contents into the integration server’s working directory. This may be the simplest for existing customers to take on as the BAR file is still the unit of deployment so they may be able to re-use much of their existing build artifacts.
Or
Directly populate the working directory in the certified image with the artifacts of your integration, and create a new image from that. This may be a new approach and require more refactoring of existing build artifacts, but there are commands specifically designed to assist such as ibmint deploy with the --output-work-directory option. This removes the need for an intermediate BAR file, simplifying the end-to-end pipeline. It also improves start-up time in a couple of ways. Firstly, the IntegrationServer has no need to parse a BAR file into a working directory. Secondly, it enables the use of the new ibmint optimize server command that allows the IntegrationServer to minimise what components it loads on start-up. For more details on this feature check out the write-up in the new features in App Connect 12.0.4.0.
You may also choose to bake in some of the elements that might otherwise have been provided via Configurations, although clearly some of these need to remain separate if they are likely to be different per environment.
Whichever of the two options you take, the next step is the same. You specify the name of the newly created image in the spec.pod.containers.runtime.image property of your IntegrationServer.yaml custom resource file, and deploy it using kubectl -apply as normal.
Using the Operator on Non-OpenShift Kubernetes Distributions
Most of the examples that we have linked to in this post have assumed that your Kubernetes environment is Red Hat OpenShift. This reduced the steps in the examples significantly as OpenShift pre-integrates a huge number of commonly used capabilities (200+) and performs a number of common steps automatically. However, we recognize that not all enterprises have OpenShift available to them, and for that reason, the IBM App Connect runtime, and also its operator are designed and supported to run on any major Kubernetes distribution.
However, the Operator depends upon the open-source Operator Framework. This is installed and pre-integrated with OpenShift, but on most other Kubernetes distributions, it will have to be installed, resulting in some preparation before using the App Connect operator. These additional steps are fully documented in the product documentation, and we have documented an example based on Amazon Elastic Kubernetes Service (EKS).
Conclusion
The App Connect operator’s IntegrationServer resource enables significant simplification of the deployment of integration servers on the Kubernetes platform. It reduces the complexity of build pipelines accelerating the path to full CI/CD, and the Configuration resource takes care of many of the subtleties around configuring environment-specific properties. As noted in at the beginning, the operator reaches far beyond integration server deployment, to the provision of an administrative dashboard, switch servers, web-based authoring, and more.
Acknowledgement and thanks to Kim Clark and Ben Thompson for providing valuable input to this article.
Published at DZone with permission of Rob Convery. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments