How You Can Avoid a CrowdStrike Fiasco
Deconstruct the architectural shortcomings that could have prevented the worldwide Crowdstrike IT meltdown from being so disastrous.
Join the DZone community and get the full member experience.
Join For FreeBy now we've all heard about — or been affected by — the CrowdStrike fiasco. If you haven't, here's a quick recap.
An update to the CrowdStrike Falcon platform, pushed on a Friday afternoon, caused computers to crash and be unbootable. The update was pushed to all customers at once, and the only way to recover was to boot into "Safe Mode" and uninstall the update. That often required direct physical access to the affected computer, making recovery times even longer.
I'm not going to go into a detailed post-mortem of all that went wrong, because I honestly don't know the gory details (Was it dereferencing a null pointer? Was it an attempt to read a protected memory location?). There have been a number of posts and articles written about the incident, and I'm sure that CrowdStrike is doing a deep dive into what went wrong and how to prevent it from happening again. (Plus there's that $10 UberEats gift card!)
This is absolutely not a finger-pointing exercise. I'm not here to say "I told you so" or "You should have done it this way." There's plenty of blame to go around in any large-scale incident like this. but examining how we could have avoided such an incident, from an architectural perspective and how to make sure it doesn't repeat, is a valuable exercise.
Issues
Here are the issues I have with how this was rolled out:
- The update was pushed to all customers at once. This is a recipe for disaster. Updates should be pushed in a phased manner, starting with a small subset of customers, and then increasing the number of customers as the update is proven to be stable. There are, of course, situations where this is just not possible. Zero-day exploits need to be patched immediately, and there is no time for a phased rollout.
- The updates were run as "mandatory" and "background" updates. This means that the updates were pushed to the computers without the user's knowledge or consent. In general, System Admins should have a warning before such updates are applied and should have the ability to forgo the updates if they choose.
- The update was pushed on a Friday afternoon. This is a classic "bad idea" in the world of IT. Updates should be pushed during the week when there are more people available to deal with any issues that arise. (Let's not get into this argument, shall we? There are lots of opinions on this, and I'm sure that you have yours.) Again, there are always situations where an emergency update is required, and there is no time for a phased rollout.
- There was no fall-back strategy in place for if the update went wrong.
The main thing missing from the entire episode was any idea of resiliency. How do you recover from a failed update? How do you ensure that your customers are not left high and dry when an update goes wrong? How do you ensure that your customers are not left with a bricked computer? These are all questions of resiliency that should be explicitly addressed in any update strategy.
How the Embedded World Handles Updates
In the embedded world, we have been designing systems to handle firmware updates — and update failures — for decades. Back in my days, we had a firmware update architecture that would update the firmware on the device, and if the update failed, the device would automatically roll back to the previous version. This was a system that was designed to be updated over the air (OTA) and to be updated in the field. We had to design for the worst-case scenario that was both robust and recoverable.
How did we do this? We implemented what is known as A/B partitioning. The device has 2 partitions (well, more really, but we'll cover that in a minute), A and B. When an update is pushed, it is pushed to the partition that is not currently running the active system. The device then reboots into the new partition, and if the update is successful, the device continues to run normally. If the update fails, the device reboots into the previous partition, and the device is back up and running. The failed partition can then be updated again, and the process repeated until the update is successful.
It is a fail-safe way to push updates to devices that are in the field, and it is a system that has been in use for decades in the embedded world. If you have an Android-based phone, chances are that your phone is using this system to update the OS. If you have a Mac, you may notice that you have a small disk partition that can be used for "recovery" in case of a system failure. It's not a full A/B partitioning system, but it is a similar idea.
Why Didn't CrowdStrike Use This System?
Well, the first problem is that these systems were all running Windows. I'll defer the whole "don't run production systems on Windows" argument for another time, but suffice it to say that Windows is not known for its robustness in the face of updates. Windows updates have been known to cause all sorts of problems, from the benign to the catastrophic. Anyone that runs Windows daily can attest to these problems. Drivers conflict, updates fail, and the system is left in a state that is not recoverable. The dreaded Blue Screen of Death (BSOD).
Windows is also not built to use such an A/B partitioning system. Windows is designed to be updated in place, by the user, and the user is expected to be able to recover from a failed update. Much of this has been taken over by remote administration, but the basic idea is still the same: Windows is designed to be updated in place. Recent versions of Windows do have a system of "snapshots" of prior working versions that can be rolled back to, but this is not the same as a full A/B partitioning system and the roll-back is not automatic.
The CrowdStrike update pushed a change to a driver that is loaded early in the boot phase. When this driver (or any driver that is loaded into kernel space) fails for any reason, Windows will refuse to boot and go to the Blue Screen of Death (BSOD). This is how Windows protects itself from malicious drivers and driver conflicts. Effective, sure, but not the most resilient way to go when you're dealing with large production systems that *must* be up and running all the time.
Production servers simply must be available all the time. There is no room for downtime, and there is no room for failure. This is why we have resiliency built into our systems. This is why we have A/B partitioning.
How Does A/B Partitioning Actually Work?
A/B partitioning schemes are designed to provide high resiliency in systems that must be up and running all the time, or where a failed update can be extremely difficult or costly to recover. Think about a small sensor embedded in a hydroelectric dam that needs to get a firmware update over the air. Now think about what happens if that update fails for some reason. Having that sensor offline due to a failed update can have catastrophic results. Sending a technician out to that remote place, to crawl into some small, dark, possibly unsafe place to fix it just isn't a viable solution. Having a system that allows for the graceful recovery of the device is the only practical solution.
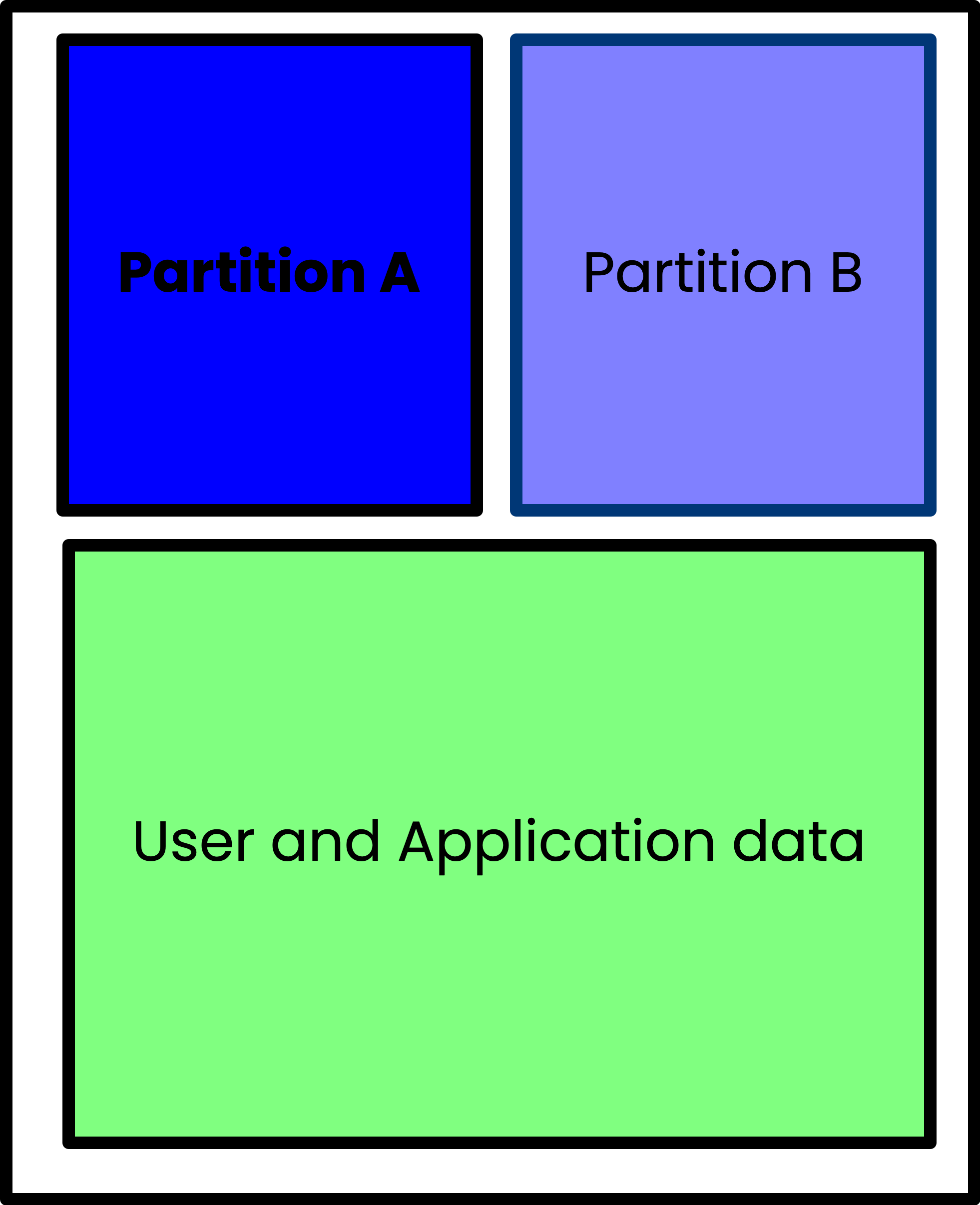
This is a simple diagram of how A/B partitioning works. The system boots into partition A, and when an update is pushed, it is written to partition B. The system then reboots from partition B, and if the update is successful, the system continues to run the updated firmware. If the update fails, the system reboots from partition A, and the system is back up and running. The failed partition can then be updated again, and the process repeated. Once successful, the system will be running out of partition B, and partition A will be the new 'spare'.
During the next update cycle, the system will update the partition that is not currently running (in this example, partition A). This way, the system is always running on a known-good partition, and the system can always recover from a failed update. This makes the system extremely resilient in the face of failed updates.
Resiliency. It's a good thing.
Is there a cost for this? Of course. There is a cost in terms of storage space, obviously. You need to have enough space to hold 2 copies of the OS, and that can be expensive. But you don't have to have double the storage space of the entire system, as only the critical OS components need to be stored in the A/B partitions. All of the user and application data can be stored in a separate partition that is always available to the running OS no matter which partition it is running from.
Is storage expensive? It can be, yes, but let's compare the relatively minor cost of this extra bit of storage to, say, the $500 million dollars that Delta Airlines has reportedly lost over the latest incident. Seems like a small price to pay for the added resiliency that it could provide.
Conclusion
The CrowdStrike meltdown was a failure of epic proportions, that much is clear. But there are a lot of factors that could have prevented it. Once the update escaped the validation and Q/A phase at CrowdStrike (which they acknowledge it shouldn't have), the lack of resiliency in the update process was the main issue and one that could have been addressed with an A/B partitioning scheme. A/B partitioning isn't available on Windows machines, but it is absolutely available for other architectures. (I know I said I wouldn't get into the "don't run your production systems on Windows" argument, but I just can't help myself.)
All drivers for Microsoft Windows must be cryptographically signed. Most software for Windows is also required to be signed. The same is true for macOS. All system and driver updates — really anything that runs in any privileged mode — should be cryptographically signed and verified before being allowed to be installed and run. Bootware ensures that all updates are cryptographically signed and verified before being allowed to be installed and run. This is a critical part of the security and resiliency of the system.
How a truly secure and resilient update process should be rolled out:
- Updates should be pushed in a phased manner, starting with a small subset of customers, and then increasing the number of customers as the update is proven to be stable whenever possible. Non-phased rollouts should be reserved for true emergency situation like zero-day exploits.
- Updates should be pushed during the week when there are more people available to deal with any issues that arise. Again, there are always situations where an emergency update is required, and there is no time for a phased rollout.
- Administrators should be informed before an update is rolled out and should have the ability to forgo the update if they choose.
- There should be a fall-back and recovery strategy in place for when an update goes wrong.
This is how a truly secure and resilient update process should be rolled out.
Opinions expressed by DZone contributors are their own.
Comments